Qwen3.6 35B A3B
unsloth/Qwen3.6-35B-A3B-MTP-GGUF
published May 2026 · updated May 2026
Qwen3.6 35B A3B is a vision-language model (VLM) that excels at agentic coding, repository-level reasoning, and tool calling, with Multi-Token Prediction for faster inference.
specs
| Task | Vision-Language Model (Causal LM with Vision Encoder) |
| Architecture | Mixture of Experts (MoE) with 256 experts (8 active + 1 shared), Gated DeltaNet & Gated Attention |
| Parameters | 35B total, 3B activated |
| Context Length | 262,144 tokens (extensible to 1,010,000) |
| MTP Support | Multi-Token Prediction for ~1.5-2x faster inference |
about this model
Qwen3.6-35B-A3B is a vision-language model that combines a causal language model with a vision encoder, featuring a Mixture-of-Experts architecture (35B total parameters, 3B activated) with 256 experts (8 routed + 1 shared). It supports native context lengths of 262,144 tokens, extensible to ~1M tokens.
Key capabilities
The model is optimized for agentic coding workflows, including repository-level reasoning, frontend development, and tool calling. It introduces thinking preservation, retaining reasoning context across iterative interactions. Multi-Token Prediction (MTP) enables 1.4–2.2x faster inference without accuracy loss, as implemented in the Unsloth GGUF quantizations hosted on gigarouter.
Benchmark performance
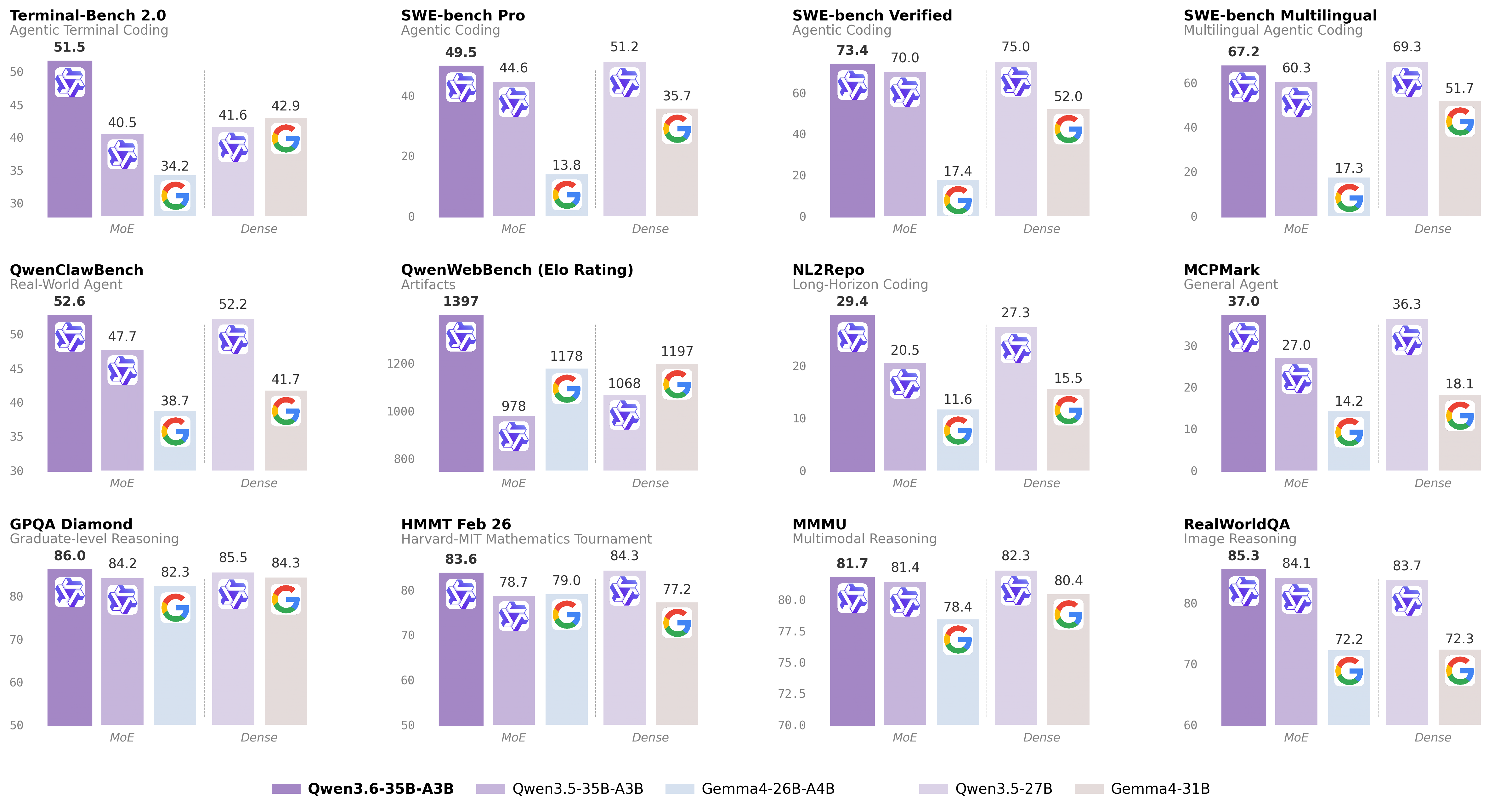
On coding agent benchmarks, Qwen3.6-35B-A3B achieves competitive or leading scores among similarly sized models (all scores from the official model card):
| Benchmark | Score |
|---|---|
| SWE-bench Verified | 73.4 |
| SWE-bench Multilingual | 67.2 |
| SWE-bench Pro | 49.5 |
| Terminal-Bench 2.0 | 51.5 |
| Claw-Eval (Avg) | 68.7 |
| SkillsBench (Avg5) | 28.7 |
Quantization and deployment
The gigarouter API serves Unsloth Dynamic 2.0 GGUF quantizations, which use a curated calibration dataset of over 1.5M tokens to preserve conversational quality. Memory requirements range from 17 GB (3-bit) to 70 GB (BF16). Recommended inference settings vary by mode: thinking mode uses temperature 1.0 / top_p 0.95 / top_k 20 for general tasks, or 0.6 / 0.95 / 20 for precise coding; instruct (non-thinking) mode uses 0.7 / 0.8 / 20 with presence penalty 1.5.
best for
- ·Agentic coding and software engineering tasks like SWE-bench
- ·Multi-step reasoning with thinking context preservation
- ·Tool calling and code execution in development workflows
FAQ
MTP enables ~1.5-2x faster inference with no accuracy loss.
Quantized versions require 17 GB (3-bit) to 70 GB (BF16) of total RAM+VRAM.
Use the OpenAI-compatible endpoint with your API key.
Native 262,144 tokens, extensible up to 1,010,000 tokens.
For thinking mode: temperature 1.0, top_p 0.95, top_k 20. For instruct mode: temperature 0.7, top_p 0.8, top_k 20, presence_penalty 1.5.
We're benchmarking and onboarding Qwen3.6 35B A3B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.