Qwen3.6 35B A3B
Qwen/Qwen3.6-35B-A3B-FP8
published Apr 2026 · updated Apr 2026
Qwen3.6 35B A3B is a vision-language model that excels at agentic coding, repository-level reasoning, and general agent tasks.
specs
| Task | Vision-Language Model (Coding Agent) |
| Architecture | Causal Language Model with Vision Encoder |
| Parameters | 35B total, 3B activated |
| Context Length | 262,144 tokens (extensible to 1,010,000) |
| License | Apache-2.0 |
about this model
Qwen3.6-35B-A3B-FP8 is a vision-language model (VLM) that combines a causal language model with a vision encoder, optimized for agentic coding and reasoning tasks.
The model uses an FP8-quantized, fine-grained quantization scheme (block size 128) that preserves performance nearly identical to the original unquantized version. It features 35 billion total parameters with only 3 billion activated per token through a Mixture-of-Experts architecture (256 experts, 8 routed + 1 shared). Context length is 262,144 tokens natively, extensible up to 1,010,000 tokens.
Key improvements over prior versions include enhanced fluency in frontend workflows and repository-level reasoning (agentic coding) and a new option to retain reasoning context from historical messages, reducing overhead in iterative development.
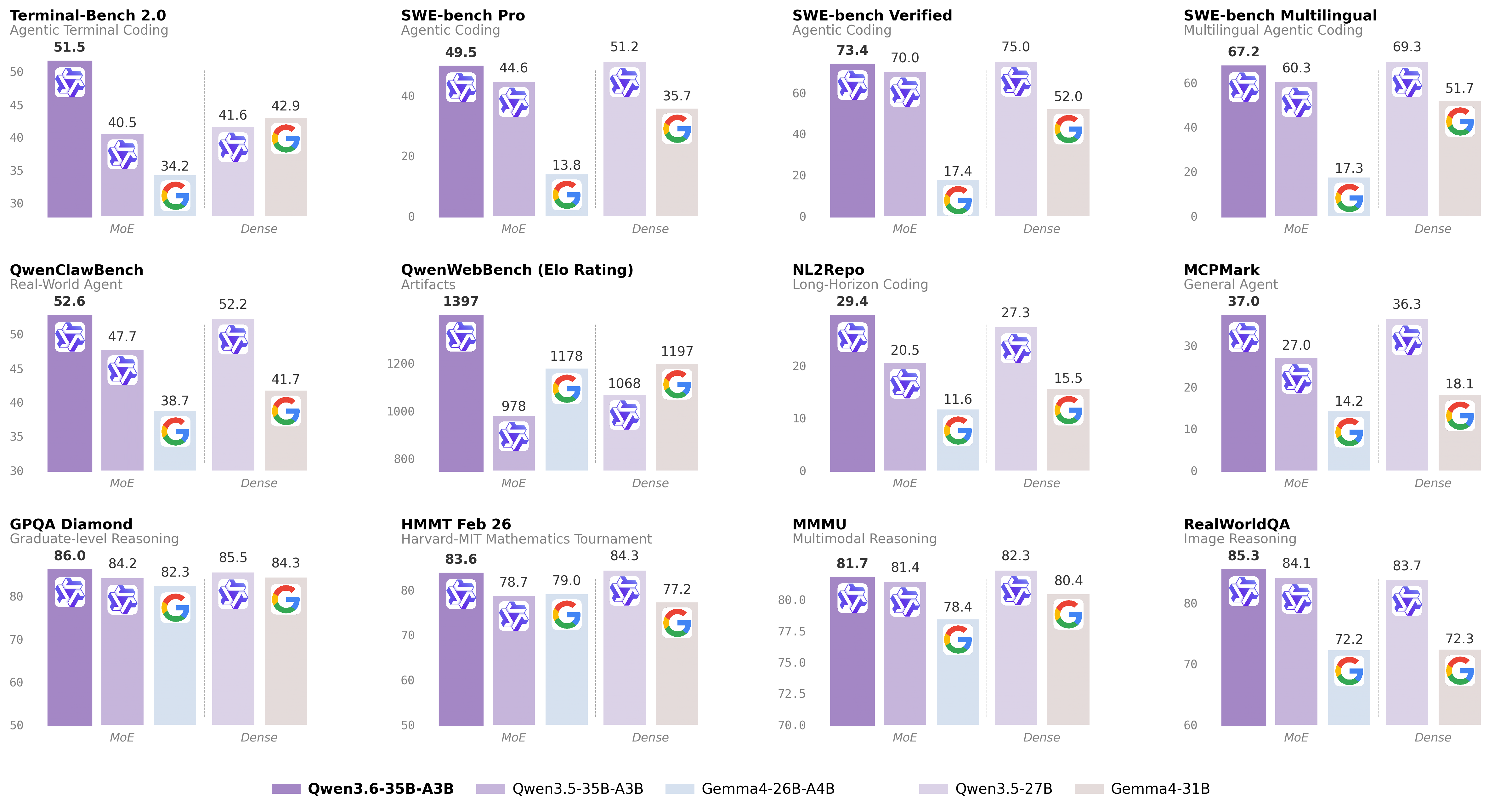
Benchmark results on coding agent and general agent tasks show Qwen3.6-35B-A3B-FP8 outperforming comparable models (Qwen3.5-35BA3B, Gemma4-31B, Gemma4-26BA4B) on many metrics, including:
| Benchmark | Qwen3.5-27B | Gemma4-31B | Qwen3.5-35BA3B | Gemma4-26BA4B | Qwen3.6-35BA3B |
|---|---|---|---|---|---|
| SWE-bench Verified | 75.0 | 52.0 | 70.0 | 17.4 | 73.4 |
| SWE-bench Multilingual | 69.3 | 51.7 | 60.3 | 17.3 | 67.2 |
| SWE-bench Pro | 51.2 | 35.7 | 44.6 | 13.8 | 49.5 |
| Terminal-Bench 2.0 | 41.6 | 42.9 | 40.5 | 34.2 | 51.5 |
| Claw-Eval Avg | 64.3 | 48.5 | 65.4 | 58.8 | 68.7 |
| Claw-Eval Pass^3 | 46.2 | 25.0 | 51.0 | 28.0 | 50.0 |
| SkillsBench Avg5 | 27.2 | 23.6 | 4.4 | 12.3 | 28.7 |
| QwenClawBench | 52.2 | 41.7 | 47.7 | 38.7 | 52.6 |
| NL2Repo | 27.3 | 15.5 | 20.5 | 11.6 | 29.4 |
| QwenWebBench | 1068 | 1197 | 978 | 1178 | 1397 |
| TAU3-Bench | 68.4 | 67.5 | 68.9 | 59.0 | 67.2 |
| VITA-Bench | 41.8 | 43.0 | 29.1 | 36.9 | 35.6 |
Notable results include leading scores on SWE-bench Verified (73.4), Terminal-Bench 2.0 (51.5), Claw-Eval (68.7), NL2Repo (29.4), and QwenWebBench (1397).
The model is licensed under Apache-2.0.
best for
- ·Agentic coding and repository-level reasoning
- ·Frontend workflow automation and debugging
- ·General agent tasks requiring long-context understanding
FAQ
It is designed for agentic coding, including frontend workflows, repository-level reasoning, and general agent tasks, with excellent performance on SWE-bench and related benchmarks.
According to benchmark results, Qwen3.6 35B A3B improves on SWE-bench Verified (73.4 vs 70.0), Terminal-Bench 2.0 (51.5 vs 40.5), and QwenWebBench (1397 vs 978), among others.
The model is released under the Apache-2.0 license, allowing free use, modification, and distribution.
Use the gigarouter OpenAI-compatible endpoint with your API key. Refer to the gigarouter documentation for endpoint details and authentication.
As a vision-language model, it accepts both text and image inputs, and produces text outputs. It supports up to 262,144 tokens of context natively.
We're benchmarking and onboarding Qwen3.6 35B A3B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.