Qwen2.5-VL 7B Instruct
Qwen/Qwen2.5-VL-7B-Instruct
published Jan 2025 · updated Apr 2025
Qwen2.5-VL 7B Instruct is a vision-language model that understands images, videos, and text, supports visual agent tasks, long video understanding, and structured output generation.
specs
| Task | Image-Text-to-Text |
| Architecture | Vision-Language Model with dynamic resolution, window attention, SwiGLU, RMSNorm |
| Parameters | 7B |
| License | Apache-2.0 |
about this model
Qwen2.5-VL-7B-Instruct is a vision-language model (VLM) that processes images, videos, and text for understanding, reasoning, and agentic tasks. It is the instruction-tuned 7B parameter variant of the Qwen2.5-VL series, offering enhanced visual perception, temporal reasoning, and structured output generation.
Architecture and Capabilities
The model uses a streamlined vision encoder with window attention, SwiGLU, and RMSNorm, aligned with the Qwen2.5 language backbone. Dynamic FPS sampling extends dynamic resolution to the temporal dimension, enabling comprehension of videos over one hour with temporal grounding to pinpoint specific events. Multimodal Rotary Position Embedding (M-RoPE) fuses positional information across text, images, and videos.
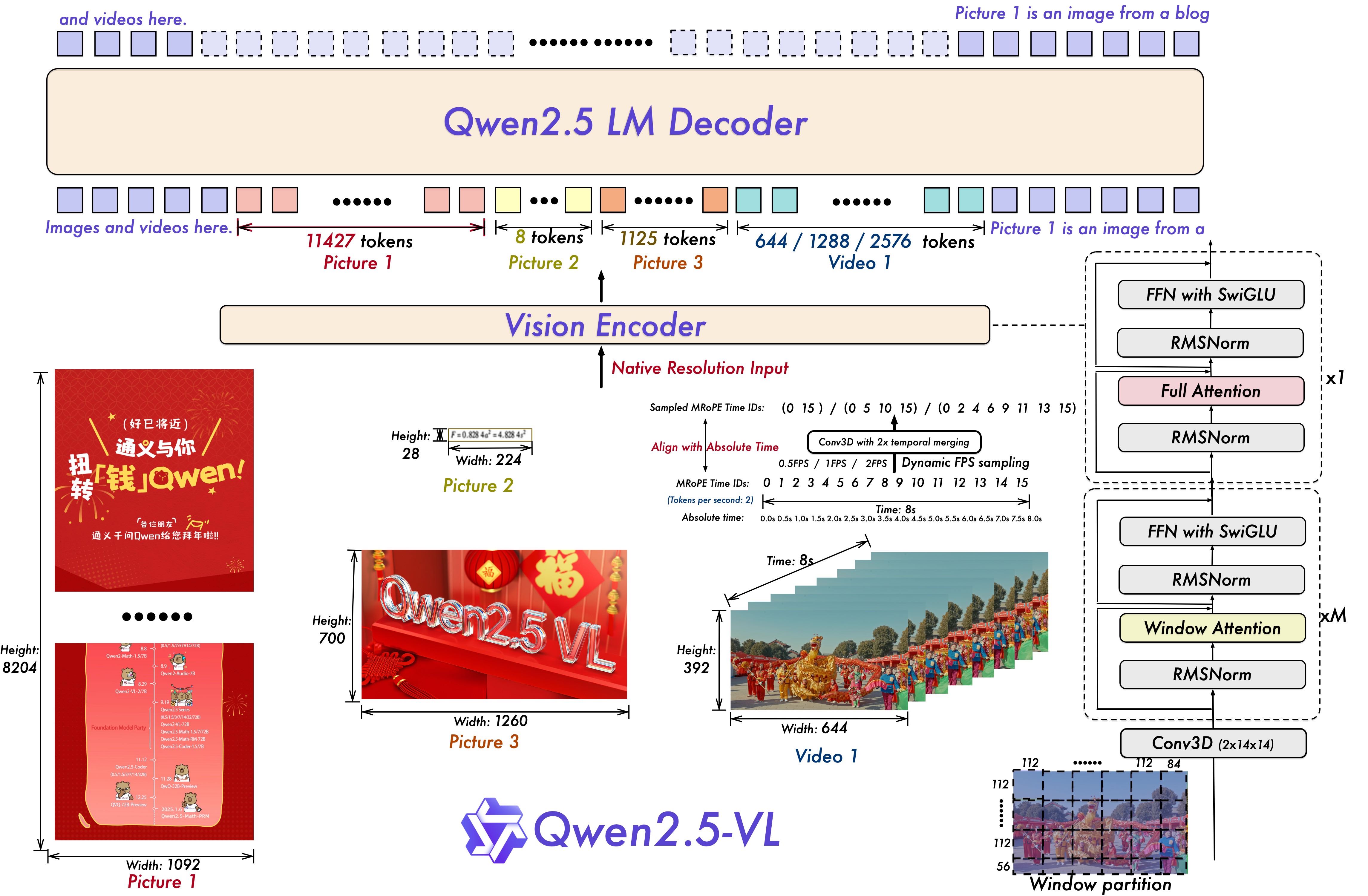
Capabilities include: accurate recognition of objects, text, charts, icons, and layouts; visual agent functions for computer and phone control via reasoning and tool invocation; visual localization using bounding boxes and points with stable JSON output; and structured extraction from invoices, forms, and tables.
Benchmark Performance
On image benchmarks (evaluation data from the model card), Qwen2.5-VL-7B achieves MMMU 58.6, MMMU-Pro 41.0, DocVQA 95.7, InfoVQA 82.6, ChartQA 87.3, TextVQA 84.9, OCRBench 864, MathVista 68.2, and MathVision 25.07. On video benchmarks it scores MVBench 69.6, Video-MME (without/with subtitles) 65.1/71.6, PerceptionTest 70.5, and MMBench-Video 1.79. Agent benchmarks show ScreenSpot 84.7, AITZ EM 81.9, Android Control High EM 60.1, MobileMiniWob++ SR 91.4, and AndroidWorld SR 25.5.
All reported numbers are from the model’s original evaluation suite. The model is hosted as a managed API on gigarouter, providing an OpenAI-compatible endpoint for production VLM workflows.
best for
- ·Visual analysis of documents, charts, icons, and graphics
- ·Visual agent tasks for computer and phone use
- ·Long video understanding with event detection and temporal localization
- ·Structured output from invoices, forms, and tables
FAQ
It can understand images and videos, perform visual grounding with bounding boxes, act as a visual agent for GUI interaction, and generate structured outputs from scanned documents.
Qwen2.5-VL 7B shows improved performance on many benchmarks including MMMU-Pro, DocVQA, ChartQA, MathVista, video understanding, and agent tasks.
It supports images (URLs or base64), videos (paths or URLs), and text interleaved with image/video content. It uses dynamic resolution for images and dynamic FPS for videos.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending a chat completion request with the model name and your input.
It is released under the Apache-2.0 license, allowing free use, modification, and distribution.
We're benchmarking and onboarding Qwen2.5-VL 7B Instruct as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.