Qwen2 VL 2B Instruct
Qwen/Qwen2-VL-2B-Instruct
published Aug 2024 · updated Jan 2025
Qwen2 VL 2B Instruct is a vision-language model that understands images, videos, and multilingual text, supporting dynamic resolution and advanced reasoning.
specs
| Task | Vision-Language Model (Visual Understanding, Video QA, Document QA) |
| Architecture | Transformer with Multimodal Rotary Position Embedding (M-RoPE) and Naive Dynamic Resolution |
| Parameters | 2 billion |
about this model
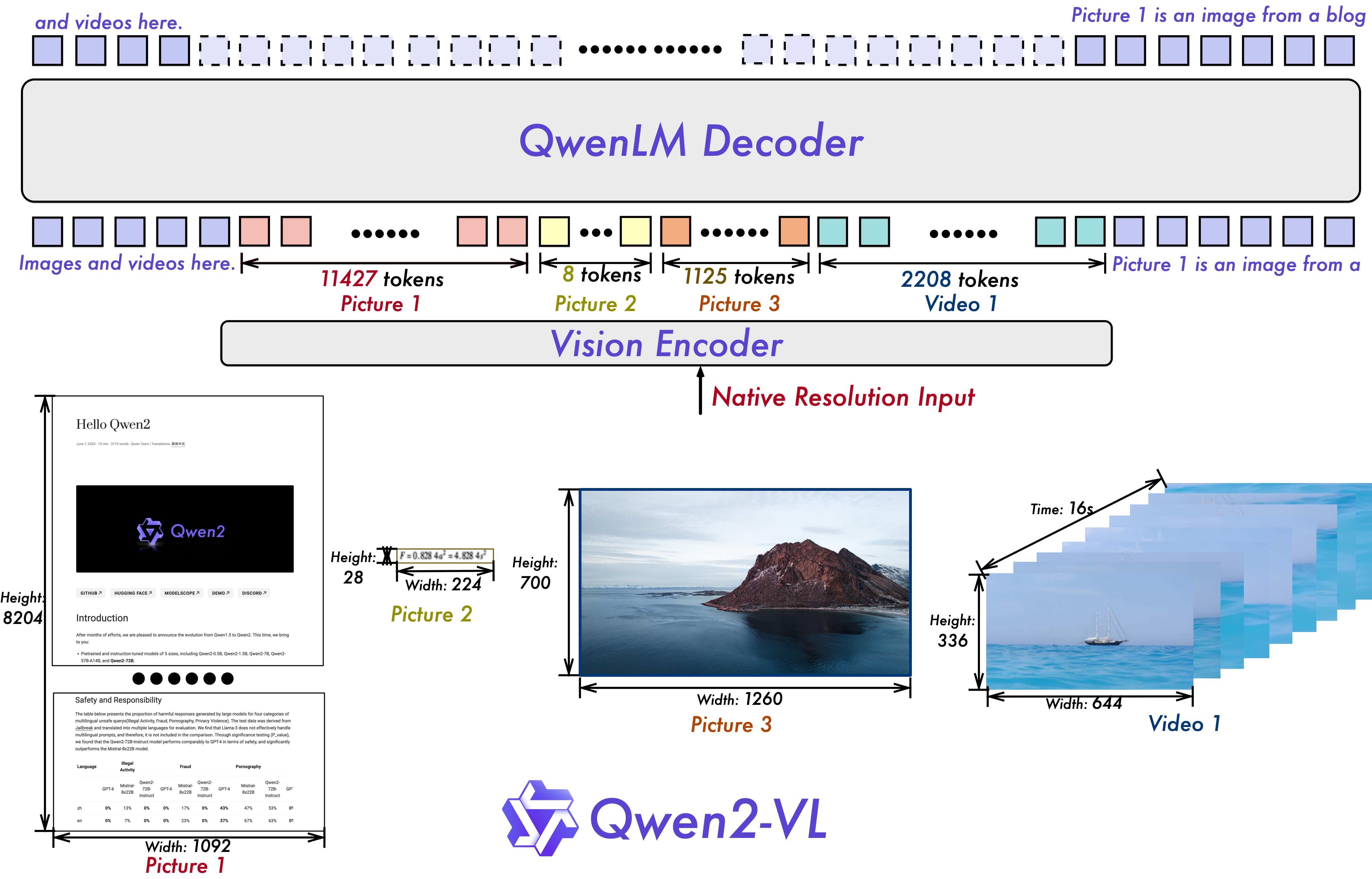
 Key capabilities include understanding videos longer than 20 minutes for question answering and content creation, supporting text extraction in multiple languages (European languages, Japanese, Korean, Arabic, Vietnamese) within images, and operating as an agent for mobile and robotic devices via visual environment interpretation and text instructions.
Key capabilities include understanding videos longer than 20 minutes for question answering and content creation, supporting text extraction in multiple languages (European languages, Japanese, Korean, Arabic, Vietnamese) within images, and operating as an agent for mobile and robotic devices via visual environment interpretation and text instructions.
Performance Benchmarks
The model achieves strong results across visual understanding benchmarks. Selected image and video benchmark scores are shown below.| Benchmark | Score |
|---|---|
| MMMU | 41.1 |
| DocVQA | 90.1 |
| InfoVQA | 65.5 |
| ChartQA | 73.5 |
| TextVQA | 79.7 |
| OCRBench | 794 |
| RealWorldQA | 62.9 |
| MMVet | 49.5 |
| MathVista | 43.0 |
| MVBench | 63.2 |
| Video-MME (wo/ subs) | 55.6 |
| Video-MME (w/ subs) | 60.4 |
best for
- ·Image description and question answering across varied resolutions
- ·Long-form video understanding (20+ minutes) and QA
- ·Document and chart understanding (DocVQA, ChartQA)
FAQ
It has 2 billion parameters.
Yes, it supports videos over 20 minutes for QA and dialog.
Images (URL, base64, file), video (frames or file), and text.
Use the OpenAI-compatible endpoint with your API key; refer to gigarouter documentation for details.
Yes, it supports text in most European languages, Japanese, Korean, Arabic, Vietnamese, and more.
We're benchmarking and onboarding Qwen2 VL 2B Instruct as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.