Qwen 3.6 27B
Qwen/Qwen3.6-27B-FP8
published Apr 2026 · updated Apr 2026
Qwen 3.6 27B is a vision-language model (VLM) optimized for agentic coding and repository-level reasoning, with FP8 quantization for efficient deployment.
specs
| Task | Vision-Language (Image to Text) |
| Architecture | Causal Language Model with Vision Encoder |
| Parameters | 27B |
| Context Length | 262,144 tokens (extensible to ~1M) |
about this model

Key Strengths
The model excels at frontend workflows and multi-step agentic tasks. A new "thinking preservation" feature retains reasoning context from historical messages, reducing overhead in iterative development. Fine-grained FP8 quantization ensures low memory usage without measurable accuracy loss.
Benchmark Results (Coding Agent)
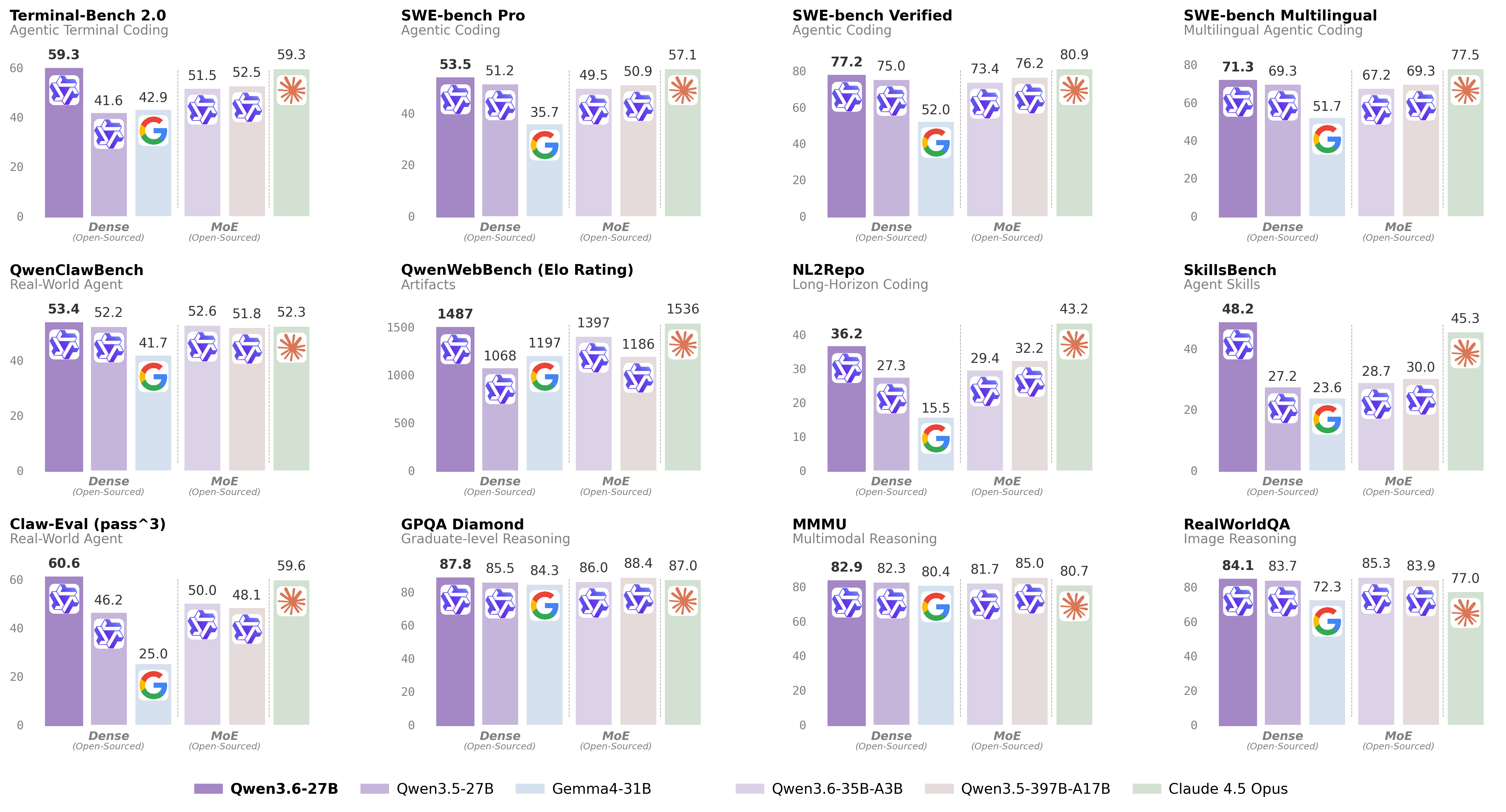
The table below highlights performance on major software engineering benchmarks. Full comparisons with Qwen3.5-27B, Qwen3.5-397B-A17B, Gemma4-31B, Claude 4.5 Opus, and Qwen3.6-35B-A3B appear in the image.
| Benchmark | Qwen3.6-27B |
|---|---|
| SWE-bench Verified | 77.2 |
| SWE-bench Pro | 53.5 |
| SWE-bench Multilingual | 71.3 |
| Terminal-Bench 2.0 | 59.3 |
| SkillsBench (Avg5) | 48.2 |
| NL2Repo | 36.2 |
| Claw-Eval (Avg) | 72.4 |
| QwenClawBench | 53.4 |
For additional details, see the Qwen3.6-27B blog post.
best for
- ·Agentic coding tasks like SWE-bench and frontend workflows
- ·Repository-level code reasoning and bug fixing
- ·Iterative development with preserved reasoning context
FAQ
It excels at agentic coding, repository-level reasoning, and frontend workflows, with strong results on SWE-bench, Terminal-Bench, and Claw-Eval.
Qwen 3.6 27B shows improvements across coding benchmarks: SWE-bench Verified 77.2 vs 75.0, Terminal-Bench 2.0 59.3 vs 41.6, and Claw-Eval Pass^3 60.6 vs 46.2.
Native context length is 262,144 tokens, extensible up to approximately 1,010,000 tokens.
Use the gigarouter OpenAI-compatible endpoint with your API key to send text and image inputs.
Yes, it uses fine-grained FP8 quantization with a block size of 128, maintaining near-lossless performance compared to the original model.
We're benchmarking and onboarding Qwen 3.6 27B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.