Qwen3 VL 4B Instruct
Qwen/Qwen3-VL-4B-Instruct
published Oct 2025 · updated Oct 2025
Qwen3 VL 4B Instruct is a vision-language model that excels in visual reasoning, long-context video understanding, and agent tasks, with dynamic thinking mode.
specs
| Task | Vision-Language (VLM) |
| Architecture | Dense Vision-Language Transformer with Interleaved-MRoPE and DeepStack |
| Parameters | 4 billion |
| License | Apache 2.0 |
about this model
Qwen3-VL-4B-Instruct is a vision-language model (VLM) that integrates advanced visual perception, reasoning, and agent interaction capabilities with native 256K context length (expandable to 1M) for processing images, videos, and long-form text.
Capabilities
- Visual agent functionality: operates PC and mobile GUIs by recognizing elements, understanding functions, invoking tools, and completing tasks.
- Visual code generation: produces Draw.io, HTML, CSS, and JS from image or video inputs.
- Advanced spatial perception: judges object positions, viewpoints, and occlusions; supports 2D grounding and 3D grounding for spatial reasoning and embodied AI.
- Long-context video understanding: handles hours-long video with full recall and second-level event indexing.
- Upgraded visual recognition: identifies celebrities, anime, products, landmarks, flora/fauna, and other categories.
- Expanded OCR: supports 32 languages (up from 19), performs robustly in low light, blur, and tilt conditions, and handles rare/ancient characters and jargon.
- Text understanding on par with pure LLMs, achieved through seamless text–vision fusion.
Architecture
- Interleaved-MRoPE: full-frequency allocation over time, width, and height for robust positional embeddings, enhancing long-horizon video reasoning.
- DeepStack: fuses multi-level ViT features to capture fine-grained details and sharpen image–text alignment.
- Text–Timestamp Alignment: precise timestamp-grounded event localization for stronger video temporal modeling.
Performance
Multimodal and pure text benchmark results are shown in the figures below.
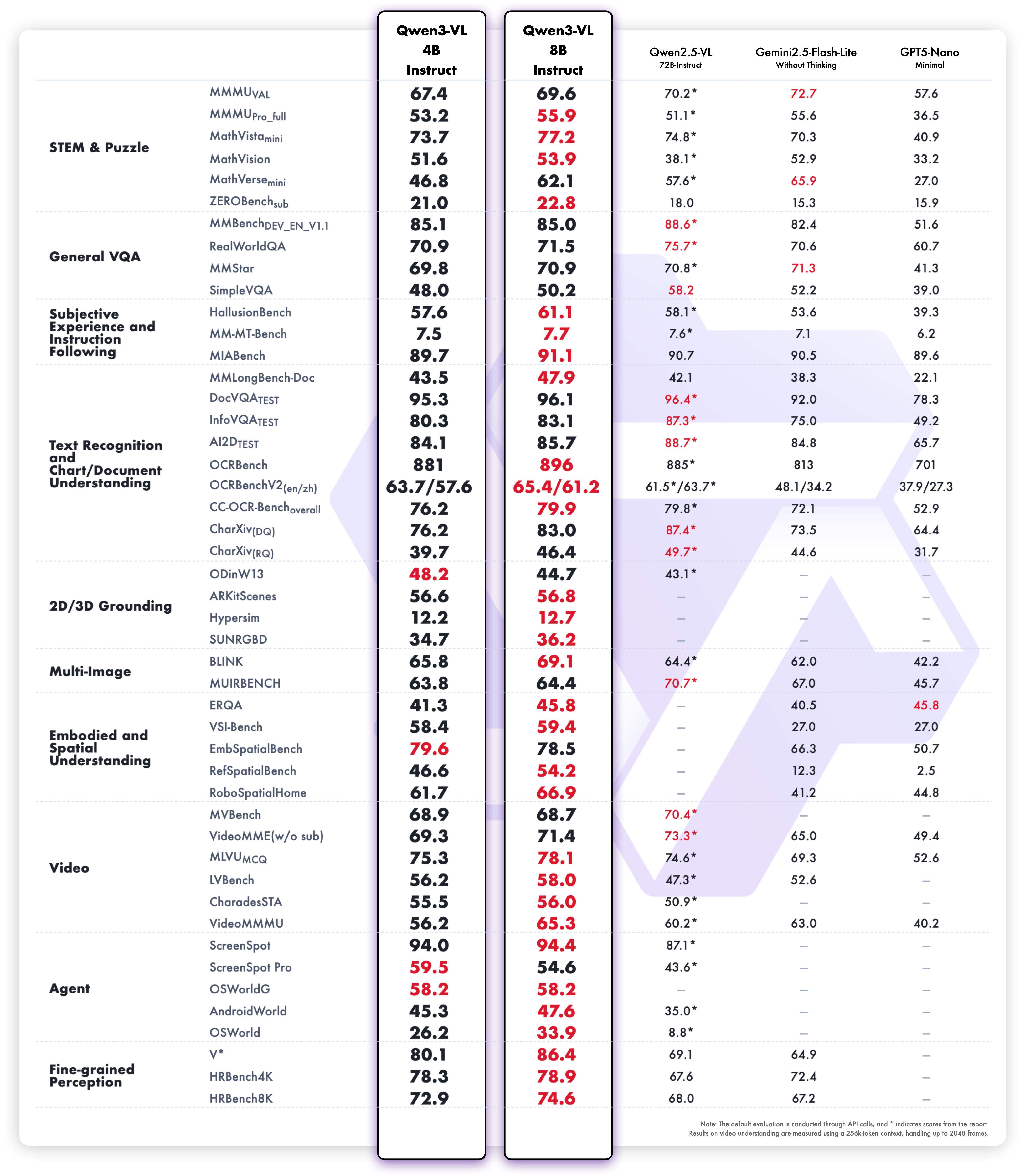
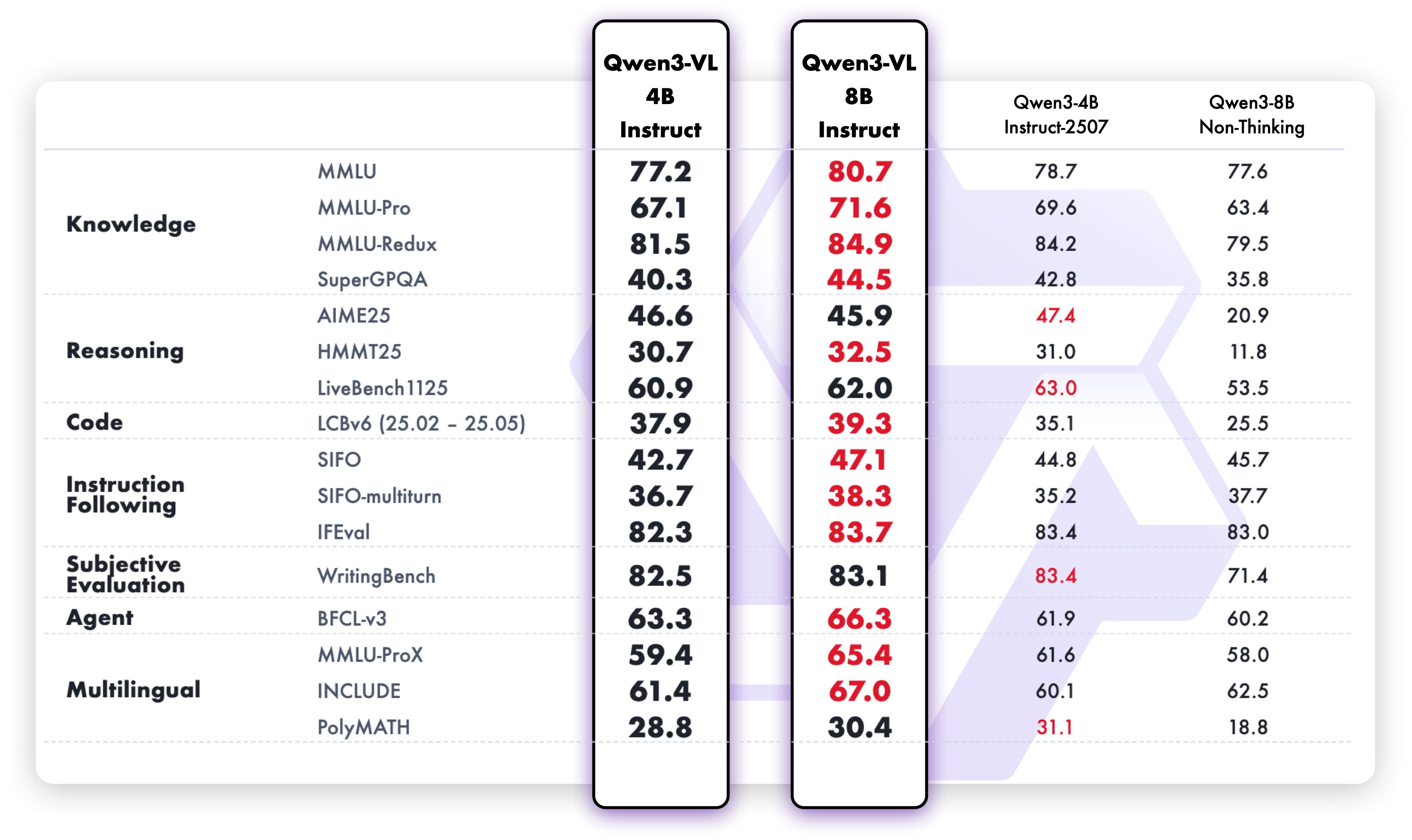
This model is part of the Qwen3-VL family, which incorporates thinking and non-thinking modes in a unified framework, and supports adaptive reasoning budgets. Qwen3-VL-4B-Instruct is available as a hosted, OpenAI-compatible API on gigarouter.
best for
- ·GUI automation and agent tasks
- ·Visual coding from images/videos
- ·Long-document OCR and parsing
- ·Video event localization and comprehension
FAQ
It excels at visual reasoning, long-context video understanding, visual agent tasks, and OCR in 32 languages.
It accepts images, videos, and text as input; outputs generated text. Use chat template with roles.
Use the gigarouter OpenAI-compatible endpoint with an API key; send messages with image and text content.
Native 256K tokens, expandable to 1M tokens.
Apache 2.0 license, allowing free use, modification, and distribution.
We're benchmarking and onboarding Qwen3 VL 4B Instruct as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.