Qwen 3.6 35B A3B
unsloth/Qwen3.6-35B-A3B-GGUF
published Apr 2026 · updated Apr 2026
Qwen 3.6 35B A3B is a vision-language model specialized for agentic coding, tool calling, and reasoning preservation with a Mixture of Experts architecture.
specs
| Task | Vision-Language Modeling & Agentic Coding |
| Architecture | Mixture of Experts (256 experts, 8 routed + 1 shared) with Gated Attention and Gated DeltaNet |
| Parameters | 35B total, 3B activated |
| Context Length | 262,144 tokens native, extensible to 1,010,000 tokens |
about this model
Qwen3.6-35B-A3B is a vision-language model combining a causal language model with a vision encoder, optimized for agentic coding and real-world utility. With 35B total parameters and 3B activated per token across 256 experts, it achieves competitive performance while remaining computationally efficient. The model natively supports 262,144-token context, extendable to over 1M tokens.
Key strengths include improved handling of frontend workflows and repository-level reasoning, plus a new thinking preservation option that retains reasoning context across iterations for streamlined development. Multi-token prediction (MTP) enables 1.4–2.2x faster inference without accuracy loss.
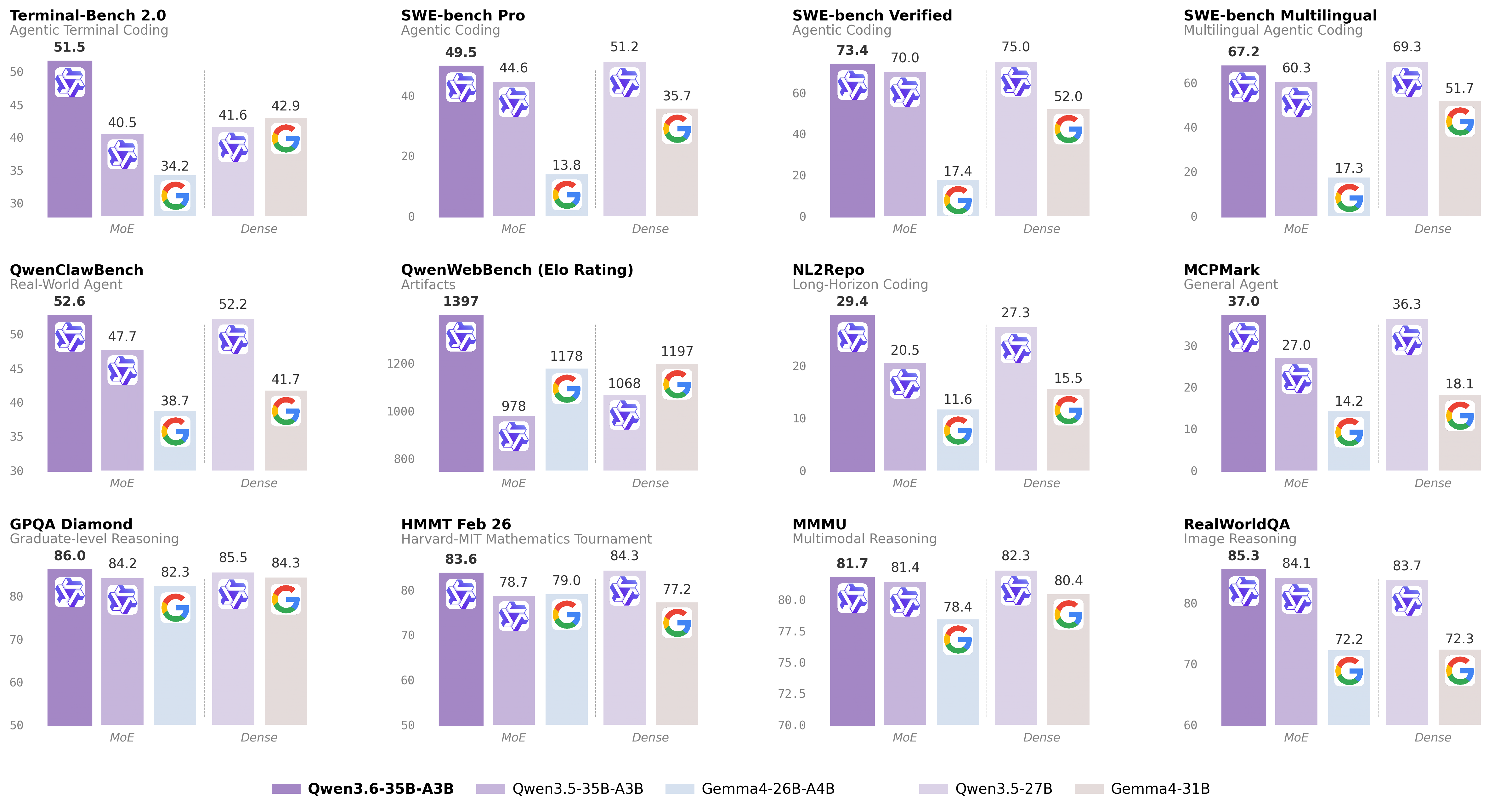
Benchmark results (from the model card) demonstrate strong coding agent performance:
| Benchmark | Score |
|---|---|
| SWE-bench Verified | 73.4 |
| SWE-bench Multilingual | 67.2 |
| SWE-bench Pro | 49.5 |
| Terminal-Bench 2.0 | 51.5 |
| Claw-Eval (Avg) | 68.7 |
| SkillsBench (Avg5) | 28.7 |
| QwenWebBench | 1397 |
This model is available as a hosted API on gigarouter, providing OpenAI-compatible access without local infrastructure overhead.
best for
- ·Building automated software engineering agents (e.g., SWE-bench, terminal tasks)
- ·Frontend and repository-level code generation and debugging
- ·Iterative development with preserved reasoning context across messages
FAQ
Approximately 23 GB of VRAM for the 4-bit quantized version.
Use thinking mode with temperature=0.6, top_p=0.95, and top_k=20.
Ensure context length is not set too low and use CUDA version below 13.2 or 13.3; avoid CUDA 13.2.
Use the gigarouter OpenAI-compatible endpoint with your API key; pass the model name and your input.
Yes, it includes a vision encoder and supports vision-language inputs for tasks like frontend screenshot understanding.
We're benchmarking and onboarding Qwen 3.6 35B A3B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.