Qwen3.6 27B
unsloth/Qwen3.6-27B-MTP-GGUF
published May 2026 · updated May 2026
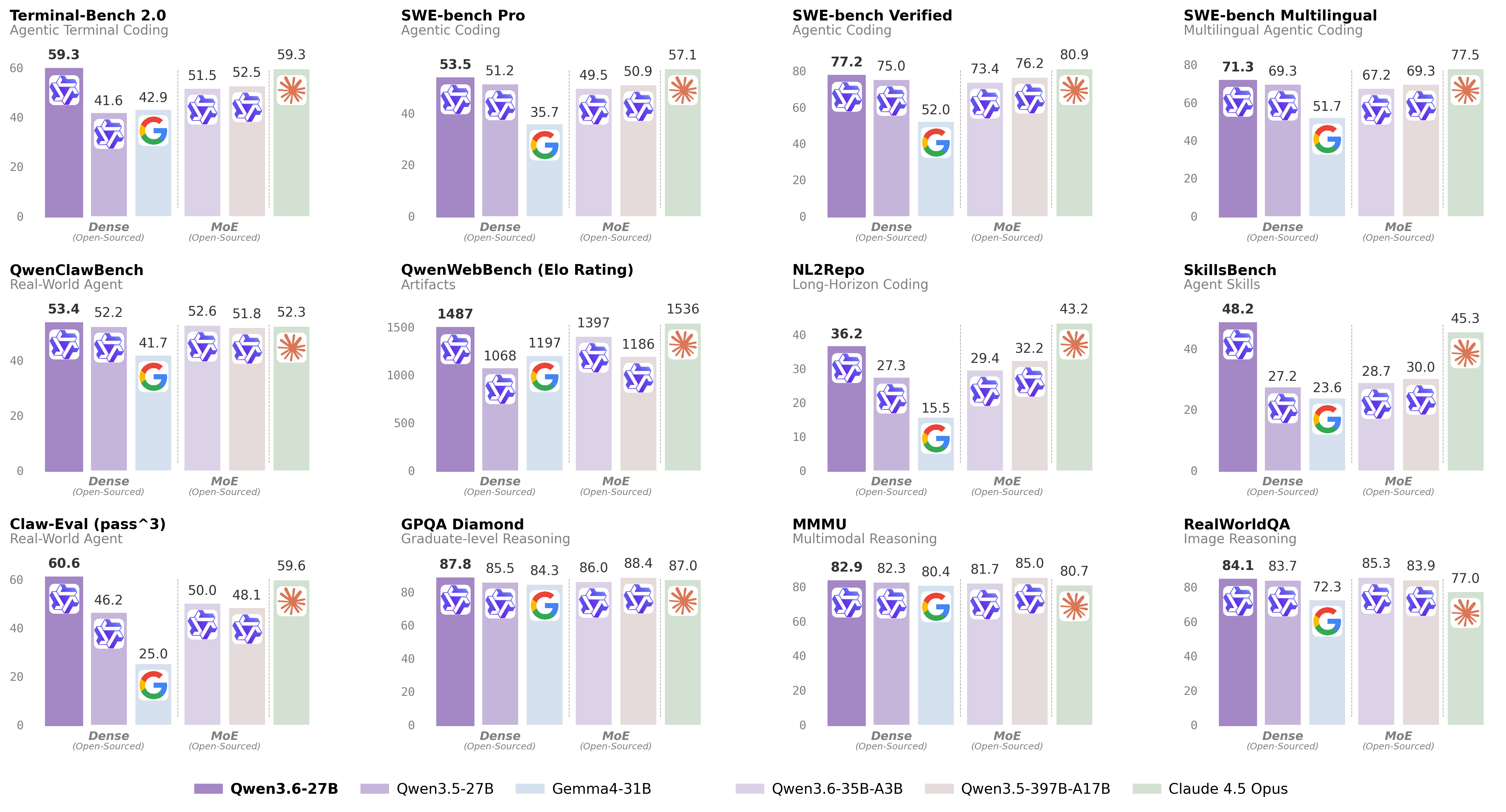
Qwen3.6 27B is a vision-language model that excels at agentic coding, repository-level reasoning, and preserving thinking context across iterative development.
specs
| Task | Vision-Language Model (VLM) |
| Architecture | Causal Language Model with Vision Encoder, Gated DeltaNet + Gated Attention |
| Parameters | 27B |
| License | See model card |
about this model
Qwen3.6-27B-MTP-GGUF is a vision-language model (VLM) that extends the Qwen3.5 series with a causal language model and vision encoder, optimized for agentic coding, reasoning preservation, and tool-calling reliability. The model has 27 billion parameters, 64 layers, a hidden dimension of 5120, and a native context length of 262,144 tokens (extendable to approximately 1 million tokens via YaRN). It employs a hybrid architecture combining Gated DeltaNet and Gated Attention layers with rotary position embeddings.
Key capabilities
- Multi-Token Prediction (MTP): Enables 1.4–2.2x faster inference with no accuracy loss when used with compatible inference engines.
- Thinking Preservation: Retains reasoning context from historical messages, reducing overhead in iterative development workflows.
- Agentic coding: Improved frontend workflow handling and repository-level reasoning.
- Tool calling: Enhanced parsing of nested objects for more reliable function calling.
Deployment via Gigarouter
Gigarouter hosts this model as a managed, OpenAI-compatible API. Below are memory requirements for available GGUF quantizations (Unsloth Dynamic 2.0 calibration dataset with over 1.5M hand-curated tokens):
| Quantization | Minimum VRAM |
|---|---|
| 3-bit | 15 GB |
| 4-bit | 18 GB |
| 6-bit | 24 GB |
| 8-bit | 30 GB |
| BF16 | 55 GB |
Recommended sampling parameters
- Thinking mode (general): temperature=1.0, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=0.0, repetition_penalty=1.0
- Thinking mode (coding): temperature=0.6, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=0.0, repetition_penalty=1.0
- Instruct (non-thinking) mode: temperature=0.7, top_p=0.80, top_k=20, min_p=0.0, presence_penalty=1.5, repetition_penalty=1.0

The model is available as an optimized GGUF through Gigarouter’s hosted API, eliminating the need for local infrastructure management.
best for
- ·Agentic coding and repository-level reasoning
- ·Frontend workflow automation with thinking preservation
- ·Iterative development with historical reasoning context
FAQ
It supports 262,144 tokens natively, extendable up to 1,010,000 tokens.
MTP enables approximately 1.5-2x faster inference with no accuracy loss.
For thinking mode coding: temperature=0.6, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=0.0, repetition_penalty=1.0.
Use the OpenAI-compatible endpoint with your API key, sending chat completion requests to the hosted model.
A 4-bit quant requires approximately 18 GB of memory.
We're benchmarking and onboarding Qwen3.6 27B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.