Dots OCR
rednote-hilab/dots.ocr
published Jul 2025 · updated Oct 2025
Dots OCR is a VLM model that unifies layout detection and content recognition for multilingual document parsing using a compact 1.7B-parameter LLM.
specs
| Task | Document Layout Parsing & OCR |
| Architecture | Vision-Language Model (VLM) based on a 1.7B LLM |
| Parameters | 1.7B |
about this model
Benchmark Results
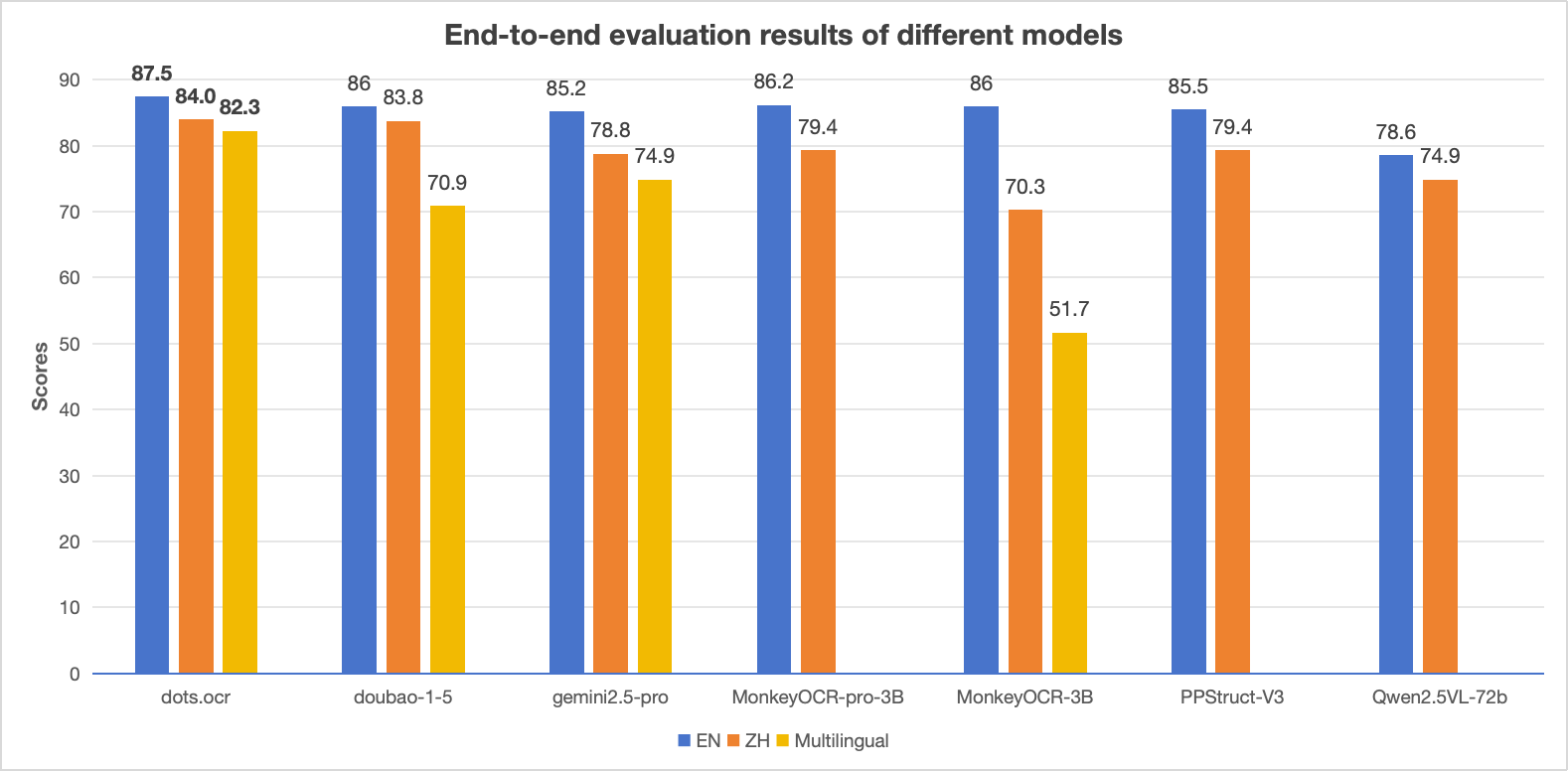
End-to-end evaluation on OmniDocBench (lower Edit is better, higher TEDS is better):
| Method | Overall (EN) | Overall (ZH) | Text (EN) | Text (ZH) | Formula (EN) | Formula (ZH) | Table (EN) | Table (ZH) | Read Order (EN) | Read Order (ZH) |
|---|---|---|---|---|---|---|---|---|---|---|
| dots.ocr | 0.125 | 0.160 | 0.032 | 0.066 | 0.329 | 0.416 | 88.6 | 89.0 | 0.040 | 0.067 |
best for
- ·Parsing multi-column documents with tables, formulas, and figures in multiple languages
- ·Extracting structured data from scanned PDFs with correct reading order
- ·Performing OCR on low-resource language documents
FAQ
It is best for multilingual document layout parsing, unifying detection and recognition of text, tables, formulas, and reading order in a single model.
Despite its compact 1.7B size, Dots OCR achieves state-of-the-art performance on OmniDocBench and XDocParse, often matching or exceeding much larger models.
Input is an image and a text prompt specifying the desired layout output; output is a JSON object with bounding boxes, categories, and formatted text (Markdown, HTML, or LaTeX).
Use the GigaRouter OpenAI-compatible endpoint with your API key to send images and prompts, receiving structured JSON responses.
Yes, it supports 126+ languages including low-resource ones, with robust parsing capabilities demonstrated on an in-house multilingual benchmark.
We're benchmarking and onboarding Dots OCR as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.