MinerU 2.5 Pro
opendatalab/MinerU2.5-Pro-2605-1.2B
published May 2026 · updated Jun 2026
MinerU 2.5 Pro is a VLM model that converts PDF pages to Markdown with layout detection, table, formula, and image/chart analysis.
specs
| Task | Document Parsing (PDF-to-Markdown) |
| Architecture | Qwen2VL (1.2B parameters) |
| Parameters | 1.2B |
| License | Apache-2.0 |
about this model
MinerU2.5-Pro-2605 is a vision-language model for document parsing that converts PDF pages to structured Markdown, combining layout detection, table and formula recognition, and image/chart analysis in a single 1.2B-parameter architecture.

Key Strengths
The 2605 version improves upon the previous 2604 release by substantially reducing category misclassification in layout detection—especially for the image_block category—and by enhancing recognition of charts, flowcharts, and seals through a large-scale training dataset. These refinements focus on real-world usability while maintaining competitive benchmark performance.
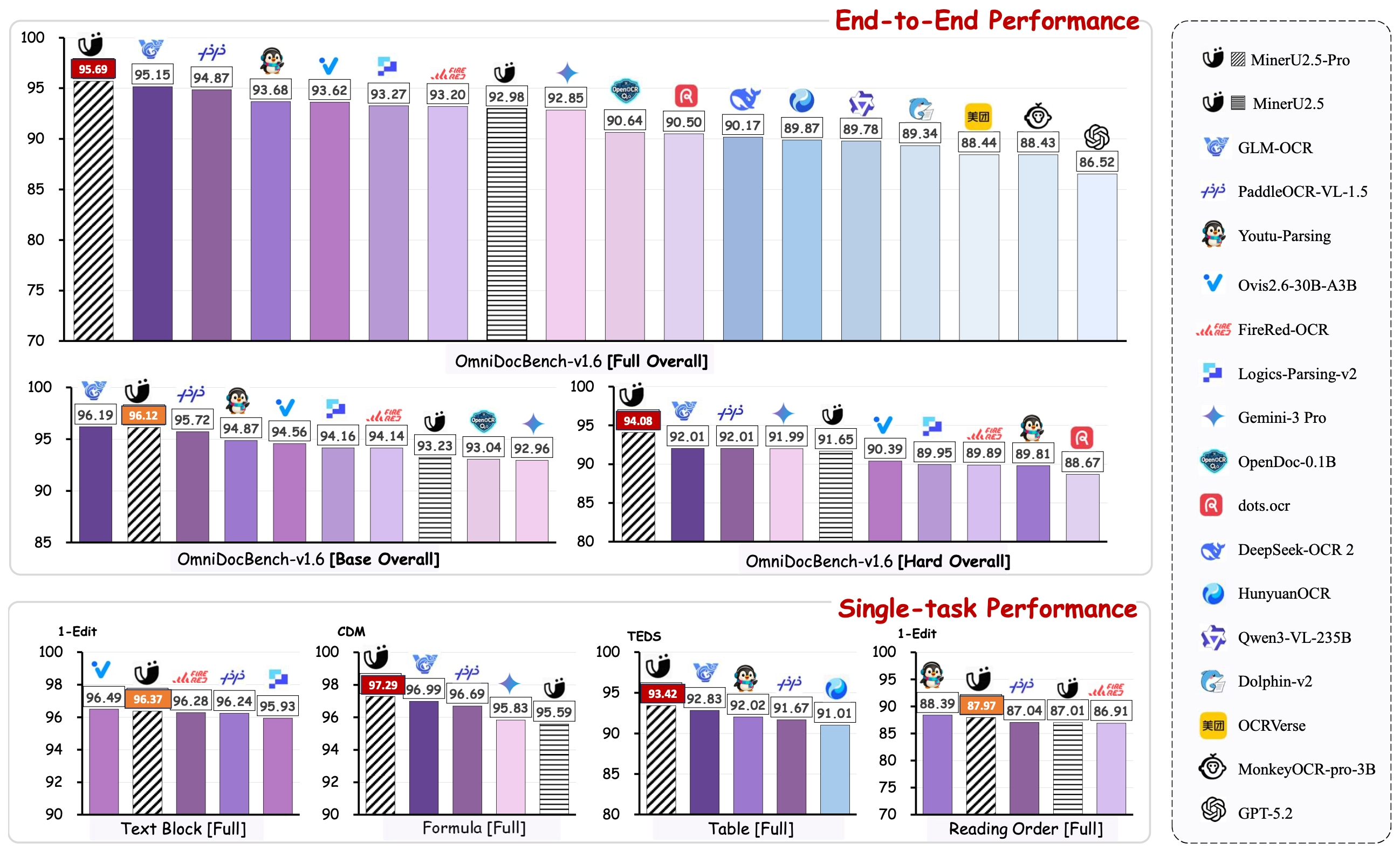
Benchmark Results
On OmniDocBench v1.6full, MinerU2.5-Pro-2605 achieves an overall score of 95.72. The table below compares it to the prior version:
| Model Version | Overall↑ | Text↓ | Formula↑ | Table↑ | Table↑ | Read Order↓ |
|---|---|---|---|---|---|---|
| MinerU2.5-Pro-2605 | 95.72 | 0.036 | 97.15 | 93.62 | 96.01 | 0.123 |
| MinerU2.5-Pro-2604 | 95.69 | 0.036 | 97.29 | 93.42 | 95.92 | 0.120 |
Additional modality-specific results include a formula CDM of 97.15 and a text Edit Distance of 0.036, both at state-of-the-art levels.
Technical Approach
Performance gains come from data engineering rather than architectural changes. The training corpus was expanded from under 10M to 65.5M pages using Diversity-and-Difficulty-Aware Sampling, and annotation quality was improved via Cross-Model Consistency Verification and a Judge-and-Refine pipeline. A three-stage training strategy (large-scale pre-training, hard-sample fine-tuning, GRPO alignment) maximizes data utility. When served with a vllm-async-engine on an A100, the model achieves an inference speed of 2.12 fps.
best for
- ·Accurate PDF-to-Markdown conversion for RAG pipelines
- ·Table and formula extraction from complex documents
- ·Document layout analysis and structured data extraction
FAQ
It accepts page images (e.g., PNG) and outputs structured ContentBlocks with bounding boxes, types (text, table, equation, image), and recognized content.
Using the vllm-async-engine on an A100, it achieves 2.12 frames per second (concurrent inference speed).
Apache-2.0.
It achieves SOTA on OmniDocBench v1.6 with a 95.69 overall score, outperforming models with over 200x more parameters.
Use the OpenAI-compatible endpoint with your gigarouter API key and send a page image for parsing.
We're benchmarking and onboarding MinerU 2.5 Pro as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.