MinerU 2.5 1.2B
opendatalab/MinerU2.5-2509-1.2B
published Sep 2025 · updated Apr 2026
MinerU 2.5 1.2B is a vision-language model for efficient high-resolution document parsing.
specs
| Task | Document Parsing / OCR |
| Architecture | Vision-Language Model (VLM) |
| Parameters | 1.2B |
| License | Not specified |
about this model
MinerU2.5 is a 1.2B-parameter vision-language model (VLM) for document parsing that achieves state-of-the-art recognition accuracy with high computational efficiency. It employs a coarse-to-fine, two-stage parsing strategy: first performing efficient global layout analysis on downsampled images to identify structural elements, then conducting fine-grained content recognition on native-resolution crops for dense text, complex formulas, and tables. This decoupled approach circumvents the computational overhead of processing high-resolution inputs while preserving fine-grained detail.
Key Strengths
- Comprehensive layout analysis: Preserves non-body elements such as headers, footers, and page numbers, and uses a refined labeling schema for clearer representation of lists, references, and code blocks.
- Formula parsing: Handles complex, lengthy mathematical formulae and accurately recognizes mixed-language (Chinese-English) equations.
- Table parsing robustness: Effectively processes rotated tables, borderless tables, and tables with partial borders.
Benchmark Results
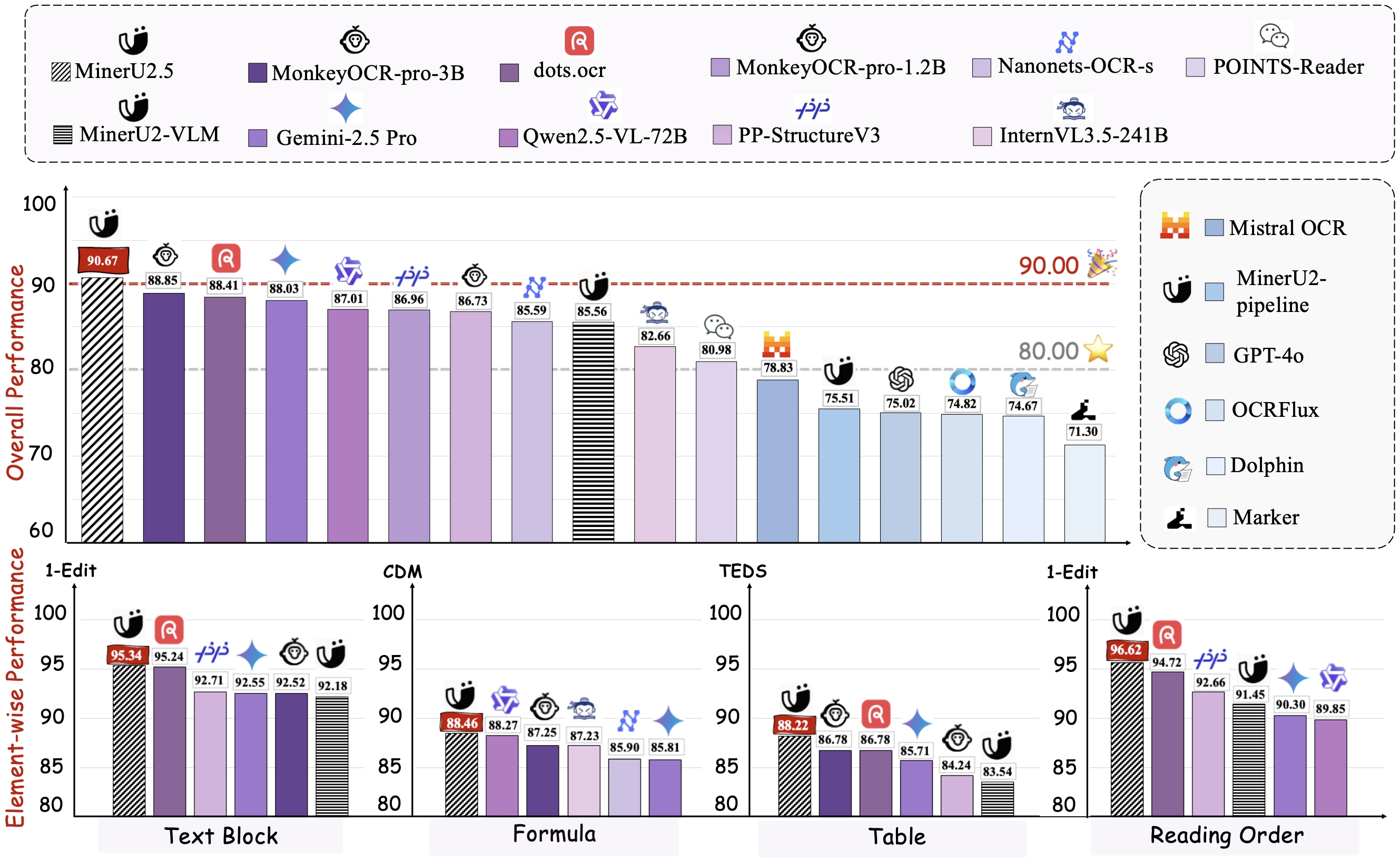
On the olmOCR-bench benchmark, MinerU2.5 achieves an overall score of 75.2, with 76.6 on Arxiv Math, 54.6 on Old Scans Math, and 84.9 on Table Tests. The model is supported by a large-scale, diverse data engine for both pretraining and fine-tuning, enabling robust performance across document types while maintaining low computational overhead.

best for
- ·Extracting structured content from scanned academic papers (text, formulas, tables)
- ·Parsing complex document layouts with headers, footers, and page numbers
- ·High-accuracy table extraction from borderless or rotated tables
- ·Converting mixed-language (Chinese-English) mathematical documents to digital format
FAQ
It is designed for efficient document parsing, including layout analysis, text recognition, formula parsing, and table extraction from high-resolution documents.
It is a 1.2B parameter vision-language model (VLM) employing a coarse-to-fine two-stage parsing strategy.
On the olmOCR-bench benchmark, it achieves an overall score of 75.2, with a table parsing score of 84.9.
Input is an image (document page); output is structured text with layout elements (paragraphs, formulas, tables). Via the gigarouter API, send the image as a base64 string or URL and receive JSON or text.
Use the gigarouter OpenAI-compatible endpoint with your API key. Provide the image as a URL or base64 in a chat completion request.
We're benchmarking and onboarding MinerU 2.5 1.2B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.