LLaVA 1.5 7B
llava-hf/llava-1.5-7b-hf
published Dec 2023 · updated Jun 2025
LLaVA 1.5 7B is a visual language model (VLM) that connects a CLIP vision encoder to a fine-tuned Vicuna language model for multimodal instruction-following tasks like image captioning and visual question answering.
specs
| Task | Visual Language Model (VLM) |
| Architecture | Transformer-based multimodal (Vicuna v1.5-7B + CLIP ViT-L/336px MLP projection) |
| Parameters | 7 billion |
| License | LLAMA 2 Community License |
about this model
LLaVA-1.5-7B is a vision-language model (VLM) that combines a CLIP-ViT-L-336px vision encoder with an auto-regressive language model fine-tuned on multimodal instruction-following data. It enables open-ended visual dialogue, image description, and complex reasoning about images through a simple prompt template (USER: xxx\nASSISTANT:) with an <image> token. The model supports multi-image input and multi-prompt generation.
Key capabilities and performance
LLaVA-1.5 achieves state-of-the-art results across 11 benchmarks, including 90.92% accuracy on Science QA. The model was trained on 1.2M publicly available data points (158K unique language-image instruction-following samples spanning conversation, detailed description, and complex reasoning). The 13B variant was trained in approximately one day on a single 8-A100 node; the 7B variant benefits from the same architecture and training recipe.
The model was accepted at NeurIPS 2023 (Oral) and CVPR 2024 (highlight). Further technical details are available in the LLaVA-1.5 paper and on the project website.
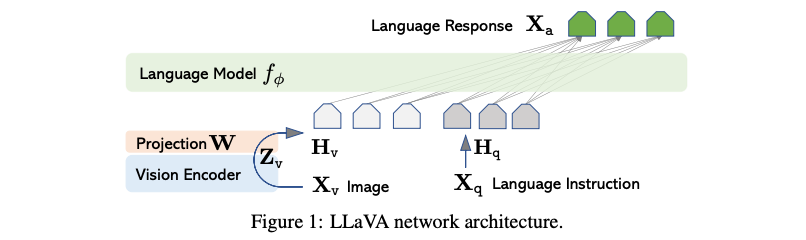
Model architecture
- Vision encoder: CLIP-ViT-L (336px resolution) with an MLP projection connector.
- Language backbone: fine-tuned LLaMA/Vicuna (7B parameters).
- License: Llama 2 Community License.
As a hosted API on gigarouter, LLaVA-1.5-7B is accessible via an OpenAI-compatible endpoint, requiring no local setup or infrastructure management.
best for
- ·Image captioning and visual question answering
- ·Multimodal chatbot with image understanding
- ·Complex reasoning about images (e.g., Science QA)
FAQ
Use the prompt template "USER: ...\nASSISTANT:" with an <image> token where the image goes. Images can be URLs or local paths passed via the chat template.
7 billion parameters.
It is licensed under the LLAMA 2 Community License.
Trained on 1.2 million publicly available multimodal instruction-following samples including 158K unique language-image pairs.
Use the OpenAI-compatible endpoint with your API key, sending an image URL or base64 and a text prompt following the required template.
We're benchmarking and onboarding LLaVA 1.5 7B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.