LightOnOCR-2 1B
lightonai/LightOnOCR-2-1B
published Jan 2026 · updated Jun 2026
LightOnOCR-2 1B is a vlm model that converts document images into clean, naturally ordered text without relying on brittle OCR pipelines.
specs
| Task | Optical Character Recognition (OCR) |
| Architecture | Vision-Language Transformer |
| Parameters | 1 billion |
| License | Apache 2.0 |
| Inference Speed | 5.71 pages/s on H100 |
about this model
LightOnOCR-2-1B is a vision-language model that converts document images (PDFs, scans, images) into clean, naturally ordered text, without relying on brittle OCR pipelines. With 1 billion parameters, it is an end-to-end differentiable model refined with RLVR training for maximum accuracy.
Key Strengths
- State-of-the-art accuracy: Achieves 83.2 ± 0.9 on OlmOCR-Bench, the best among evaluated systems, outperforming Chandra-9B by over 1.5 percentage points despite being roughly 9× smaller.
- High throughput: Processes 5.71 pages per second on a single H100 (~493k pages/day) at under $0.01 per 1,000 pages.
- Speed vs. alternatives: 3.3× faster than Chandra OCR, 1.7× faster than OlmOCR, 5× faster than dots.ocr, 2× faster than PaddleOCR-VL-0.9B, and 1.73× faster than DeepSeekOCR.
- Versatile input handling: Works on tables, receipts, forms, multi-column layouts, and mathematical notation, and can predict bounding boxes for embedded images (bbox variants).
Benchmark Results
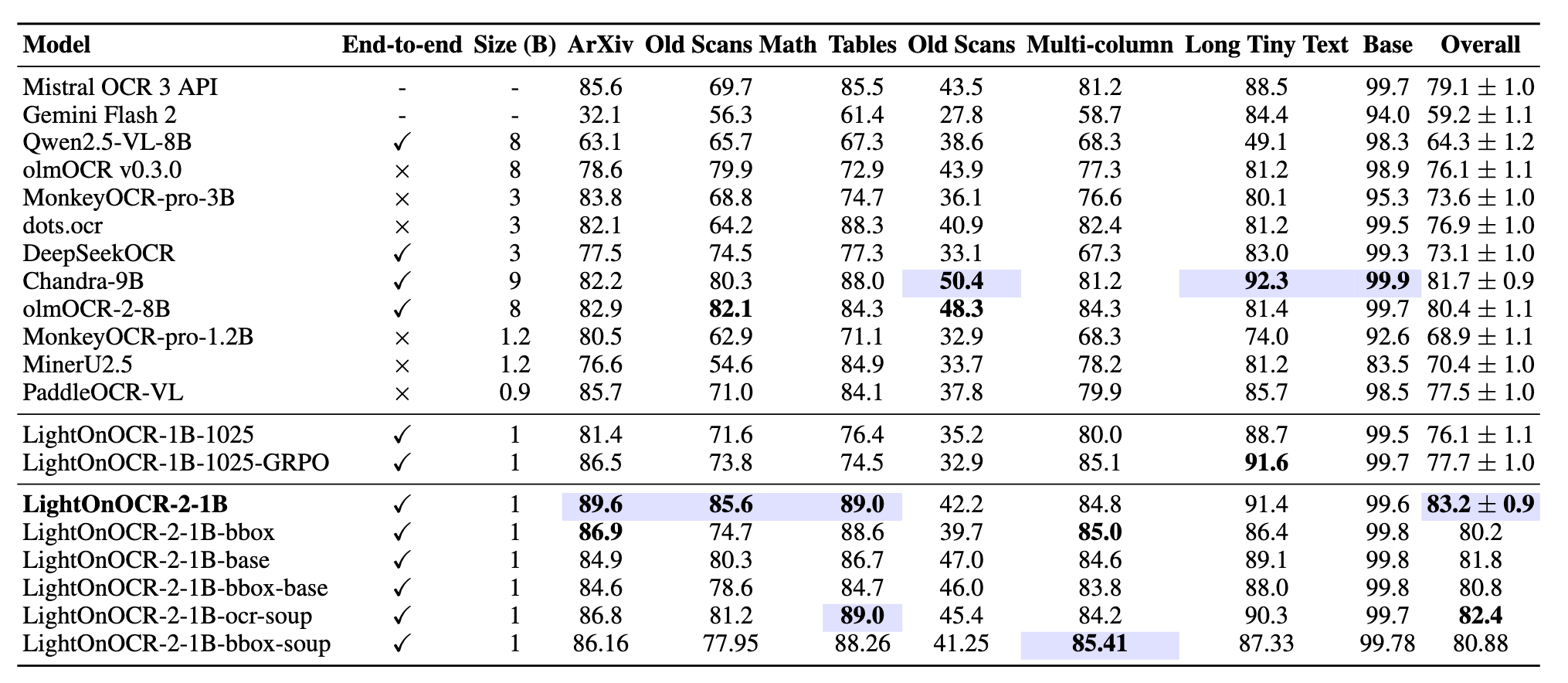
Full methodology and additional evaluations (including OmniDocBench) are available in the paper.
Variants
The model is released in several variants on Hugging Face: LightOnOCR-2-1B (best accuracy), -base (for fine-tuning), -bbox (with image bounding boxes), -bbox-base, and merged soup variants (-ocr-soup, -bbox-soup) that combine OCR and bounding-box strengths via checkpoint averaging and task-arithmetic merging.
Training Data
LightOnOCR-2 was trained on LightOnOCR-mix-0126, a dataset of over 16 million high-quality annotated document pages with strong coverage of scans, French documents, and scientific PDFs. A dedicated bbox dataset (~500k pages with bounding box annotations) is also available.
best for
- ·Extracting text from scanned documents and PDFs
- ·Processing multi-column layouts and tables
- ·Converting handwritten or printed math notation to LaTeX
FAQ
It is best for end-to-end OCR from document images, including PDFs, scans, receipts, forms, and scientific articles, with strong handling of multi-column layouts, tables, and math notation.
It is approximately 9x smaller than prior best-performing models and 3.3x faster than Chandra OCR, 1.7x faster than OlmOCR, and 5x faster than dots.ocr, while achieving state-of-the-art accuracy on OlmOCR-Bench.
The model checkpoint is released under Apache License 2.0. The training dataset and evaluation benchmarks are released under their respective licenses.
Use the gigarouter OpenAI-compatible endpoint with your API key. Send a chat completion request with an image URL or base64-encoded image as a user message, and receive the OCR text in the response.
It accepts one image per request, provided as a URL or base64 data URI. Images should be rendered at 200 DPI with a longest dimension of approximately 1540px for best results.
We're benchmarking and onboarding LightOnOCR-2 1B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.