UI-Venus Ground 7B
inclusionAI/UI-Venus-Ground-7B
published Aug 2025 · updated Aug 2025
UI-Venus Ground 7B is a vision-language model that performs precise GUI element grounding and navigation using only screenshots as input.
specs
| Task | GUI grounding and navigation |
| Architecture | Qwen2.5-VL based multimodal LLM |
| Parameters | 7B |
| License | Apache 2.0 |
| Training Data | 350K high-quality samples |
about this model
UI-Venus-Ground-7B is a vision-language model (VLM) that performs precise GUI element grounding and effective navigation using only screenshots as input, built on the Qwen2.5-VL multimodal large language model. It achieves state-of-the-art performance through Reinforcement Fine-Tuning (RFT) with 350K high-quality, professionally annotated training samples.
Key Capabilities
The model takes a screenshot and a natural language instruction (e.g., "Outline the position corresponding to the instruction") and outputs a bounding box in normalized coordinates. It is designed for both grounding (identifying UI elements) and navigation (planning and executing multi-step actions) tasks across mobile, desktop, and web interfaces.
Benchmark Performance
UI-Venus-Ground-7B achieves state-of-the-art results on multiple UI understanding benchmarks:
- ScreenSpot-v2: 94.1% average accuracy, surpassing prior models including UI-TARS-1.5 (94.2%) and GPT-4o (20.1%).
- ScreenSpot-Pro: 50.8% overall, outperforming GTA1-7B (50.1%) and UI-TARS-1.5-7B (49.6%).
- AndroidWorld: 49.1% success rate on online UI navigation tasks.
The 72B variant further extends performance to 95.3% on ScreenSpot-v2, 61.9% on ScreenSpot-Pro, and 65.9% on AndroidWorld, surpassing closed-source models including UI-TARS-1.5.
Technical Approach
UI-Venus is trained using Reinforcement Fine-Tuning (RFT) with carefully designed reward functions for both grounding and navigation tasks. The training data undergoes a three-stage refinement pipeline: prompt rewrite, trace editing, and trace generation. For navigation, the model employs action-level reward design for better credit assignment, along with Self-Evolving Trajectory History Alignment and Sparse Action Enhancement to improve long-horizon planning coherence.
Performance Overview
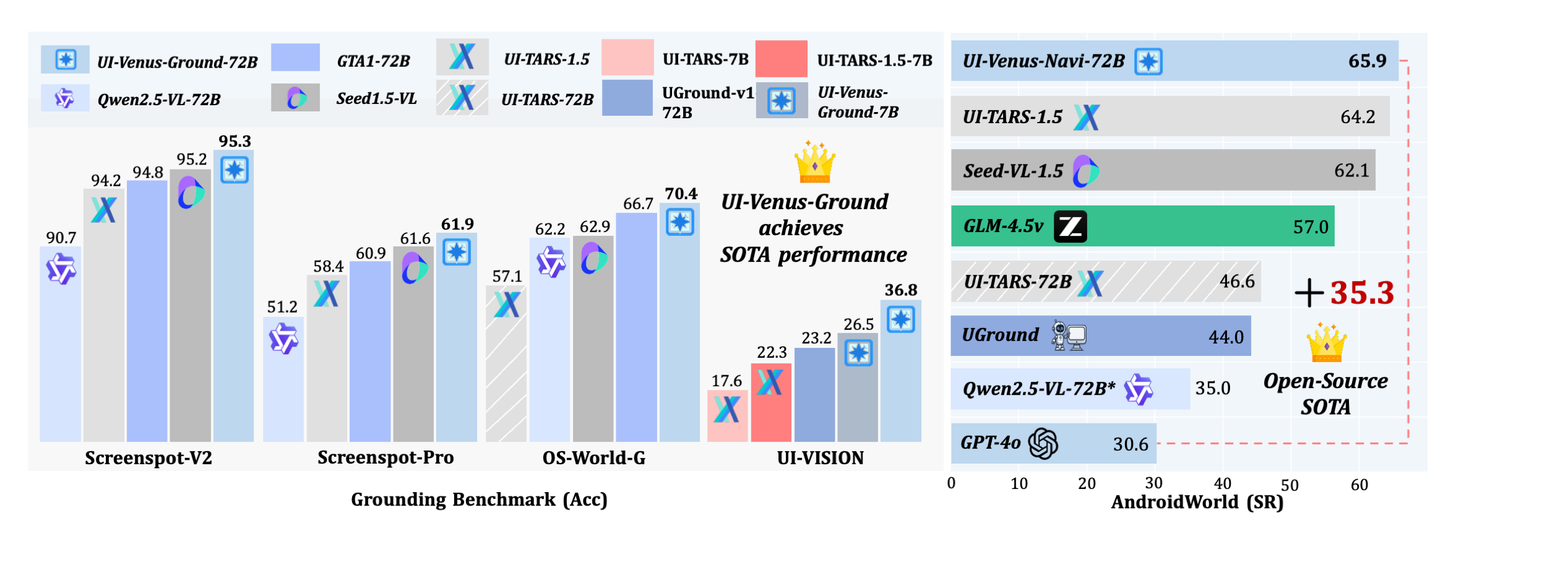
ScreenSpot-v2 Results
| Model | Mobile Text | Mobile Icon | Desktop Text | Desktop Icon | Web Text | Web Icon | Avg. |
|---|---|---|---|---|---|---|---|
| GPT-4o | 26.6 | 24.2 | 24.2 | 19.3 | 12.8 | 11.8 | 20.1 |
| Qwen2.5-VL-7B | 97.6 | 87.2 | 90.2 | 74.2 | 93.2 | 81.3 | 88.8 |
| UI-TARS-7B | 96.9 | 89.1 | 95.4 | 85.0 | 93.6 | 85.2 | 91.6 |
| UI-Venus-Ground-7B | 99.0 | 90.0 | 97.0 | 90.7 | 96.2 | 88.7 | 94.1 |
ScreenSpot-Pro Results
| Model | Overall | Type |
|---|---|---|
| UI-TARS-1.5 | 61.6 | Closed |
| GTA1-7B | 50.1 | RL |
| GTA1-72B | 58.4 | RL |
| UI-Venus-Ground-7B | 50.8 | RL |
| UI-Venus-Ground-72B | 61.9 | RL |
best for
- ·Automating UI testing by grounding elements in screenshots
- ·Building GUI agents for mobile, desktop, and web navigation
- ·Enhancing accessibility tools with screen element detection
FAQ
It excels at visual grounding and navigation in UI screenshots, achieving state-of-the-art performance on ScreenSpot-v2 and ScreenSpot-Pro benchmarks.
UI-Venus Ground 7B surpasses prior SOTA models such as GTA1 and UI-TARS-1.5 on ScreenSpot-v2 (94.1%) and ScreenSpot-Pro (50.8%).
Input: a screenshot image and an instruction text. Output: a bounding box in normalized coordinates [x1,y1,x2,y2] and a center point.
Use the gigarouter OpenAI-compatible endpoint with an API key. Send a POST request with a prompt including an image URL and instruction.
The model is licensed under Apache 2.0.
We're benchmarking and onboarding UI-Venus Ground 7B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.