DeepSeek OCR 2
deepseek-ai/DeepSeek-OCR-2
published Jan 2026 · updated Feb 2026
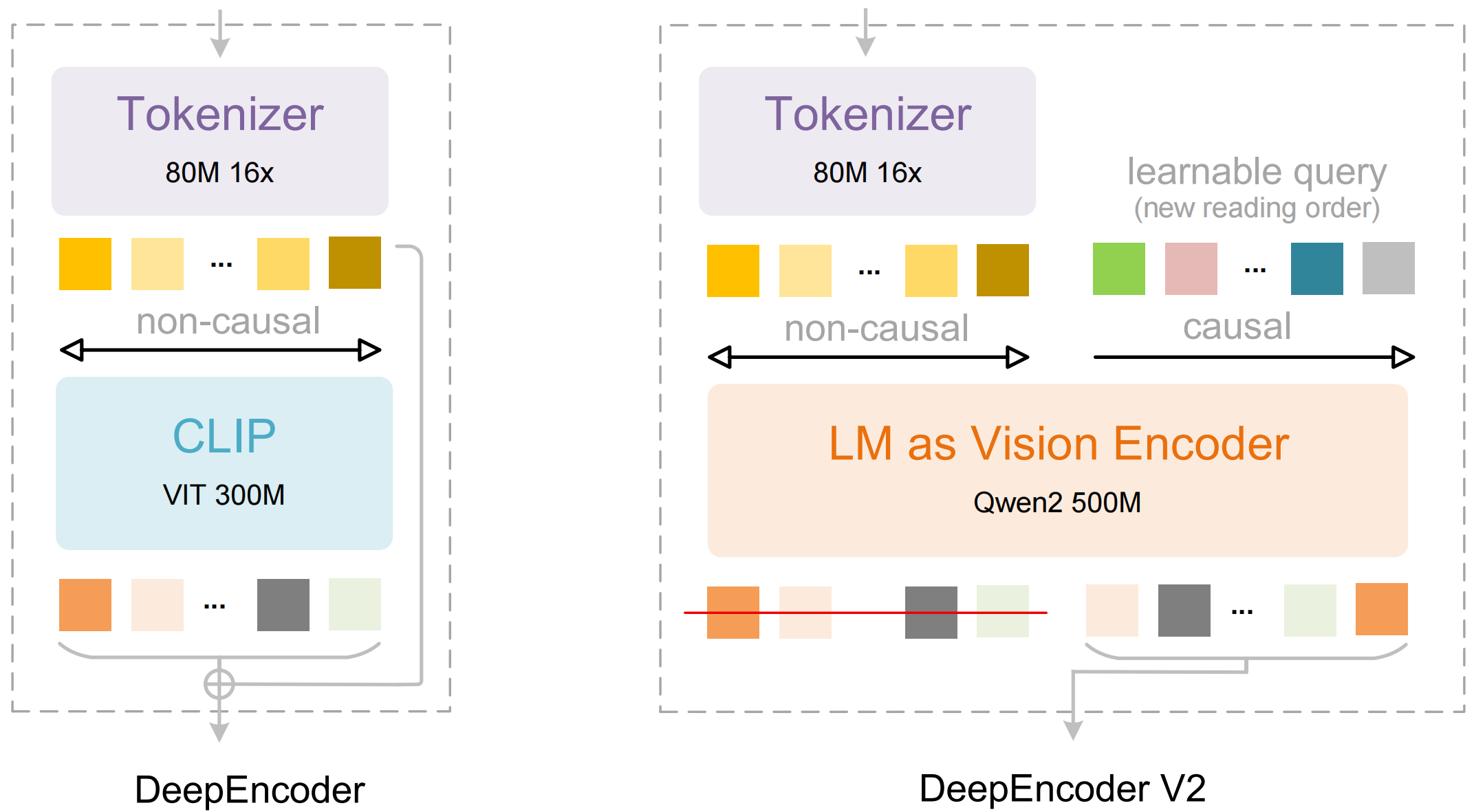
DeepSeek OCR 2 is a vision-language model that performs optical character recognition and document understanding using a novel encoder (DeepEncoder V2) that dynamically reorders visual tokens based on causal reasoning.
specs
| Task | OCR / Document Understanding |
| Architecture | DeepEncoder V2 with causal visual token reordering |
| Dynamic Resolution | (0-6)x768x768 + 1x1024x1024 pixels |
| Visual Tokens | (0-6)x144 + 256 tokens |
about this model
DeepSeek-OCR-2 is a vision-language model (VLM) that performs optical character recognition and document understanding by dynamically reordering visual tokens based on causal reasoning, inspired by human visual perception.
Core Innovation
Conventional VLMs process visual tokens in a rigid raster-scan order. DeepSeek-OCR-2 introduces DeepEncoder V2, which endows the encoder with causal reasoning capabilities to intelligently reorder visual tokens prior to LLM content interpretation. This enables two-cascaded 1D causal reasoning structures for effective 2D image understanding, particularly for complex layouts.
Benchmark Performance
On the olmOCR-bench, DeepSeek-OCR-2 achieves the following scores:
| Benchmark | Score |
|---|---|
| Overall | 76.3 |
| Arxiv Math | 82.0 |
| Old Scans Math | 72.0 |
| Table Tests | 77.4 |
| Old Scans | 33.8 |
| Multi Column | 79.0 |
| Long Tiny Text | 90.7 |
On OmniDocBench, it surpasses GOT-OCR2.0 (256 tokens/page) using only 100 vision tokens, and outperforms MinerU2.0 (6000+ tokens per page) while utilizing fewer than 800 tokens. In production, it can generate training data at a scale of 200k+ pages per day on a single A100-40G.
Model Capabilities
Supports dynamic resolution with a default mode of (0-6)×768×768 + 1×1024×1024, producing (0-6)×144 + 256 visual tokens. Two main prompt modes are available: for document conversion use <image>\n<|grounding|>Convert the document to markdown.; for OCR without layouts use <image>\nFree OCR.
For further details, see the paper on arXiv.
best for
- ·Document-to-markdown conversion with layout preservation
- ·High-accuracy OCR on complex layouts and multi-column documents
- ·Training data generation for multimodal LLMs and VLMs at scale
FAQ
It excels at OCR and document understanding, particularly converting documents to markdown while preserving layout, and achieving high accuracy with fewer visual tokens than prior models.
On OmniDocBench it surpasses GOT-OCR2.0 (256 tokens/page) using only 100 vision tokens and outperforms MinerU2.0 (6000+ tokens per page) with fewer than 800 tokens.
Input: an image plus a prompt (e.g., "<image>\n<|grounding|>Convert the document to markdown."). Output: extracted text or markdown.
Use the gigarouter OpenAI-compatible endpoint with your API key, specifying the model name "deepseek-ai/DeepSeek-OCR-2" in the request.
The model card does not specify a license; please check the official repository or contact DeepSeek AI for current licensing terms.
We're benchmarking and onboarding DeepSeek OCR 2 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.