Qwen3.6 35B A3B
cyankiwi/Qwen3.6-35B-A3B-AWQ-4bit
published Apr 2026 · updated Jul 2026
Qwen3.6 35B A3B is a vision-language model that excels at agentic coding, repository-level reasoning, and frontend workflows with a 35B total parameter MoE architecture activating 3B per token.
specs
| Task | Vision-Language (Causal LM with Vision Encoder) |
| Architecture | Mixture of Experts (MoE) with Gated DeltaNet and Gated Attention |
| Parameters | 35B total, 3B activated per token |
| License | Not specified in card |
about this model
Qwen3.6-35B-A3B is a vision-language model (VLM) with a sparse mixture-of-experts architecture (35B total parameters, 3B activated) that excels at agentic coding, repository-level reasoning, and multimodal tasks. It is hosted on gigarouter as a managed, OpenAI-compatible API.
The model combines a vision encoder with a causal language model, supporting a native context length of 262,144 tokens, extensible to over 1 million. It is calibrated on STEM and agentic data and supports ten languages. Key upgrades include improved frontend workflow handling and a new option to retain reasoning context from historical messages.
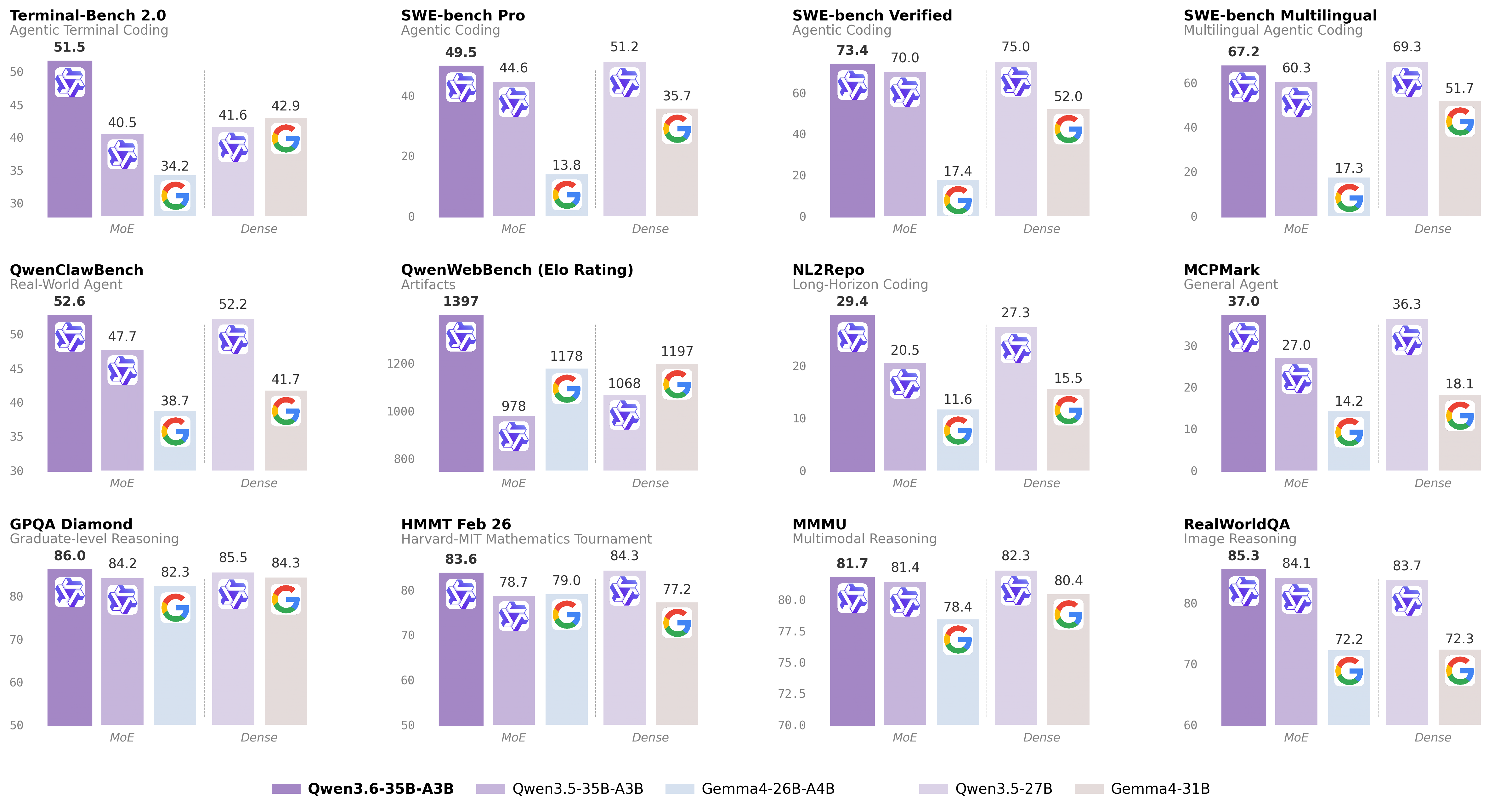
In coding agent benchmarks, Qwen3.6-35B-A3B achieves 73.4% on SWE-bench Verified (vs. 70.0% for Qwen3.5-35BA3B, 52.0% for Gemma4-31B), 67.2% on SWE-bench Multilingual, 49.5% on SWE-bench Pro, and 51.5% on Terminal-Bench 2.0. It scores 68.7% (Avg) and 50.0% (Pass) on Claw-Eval, 28.7% on SkillsBench Avg5, 29.4% on NL2Repo, and 1397 on QwenWebBench. These results demonstrate improvements in agentic coding, repository-level reasoning, and web interaction tasks. The AWQ 4-bit quantized variant enables efficient deployment with minimal quality loss.
best for
- ·Agentic coding and repository-level reasoning (e.g., SWE-bench tasks)
- ·Frontend workflow automation and web-based agent tasks
- ·Multilingual code generation and debugging across 10 languages
FAQ
It supports 262,144 tokens natively, extensible up to 1,010,000 tokens.
3B parameters are activated per token out of 35B total, using a Mixture of Experts architecture with 256 experts (8 routed + 1 shared).
It supports EN, ZH, HI, AR, RU, JA, KO, NL, FR, and ES.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending requests in the standard chat completions format.
The AWQ 4-bit quantized version is 24.97 GB.
We're benchmarking and onboarding Qwen3.6 35B A3B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.