Unlimited OCR
baidu/Unlimited-OCR
published Jun 2026 · updated Jul 2026
Unlimited OCR is a vlm model that performs one-shot long-horizon document parsing and text recognition using a constant KV cache attention mechanism.
specs
| Task | Optical Character Recognition (OCR) / Document Parsing |
| Architecture | VLM with Reference Sliding Window Attention (R-SWA) |
| Context Length | 32,768 tokens |
| Input | Single image or multi-page PDF (up to 32K tokens) |
about this model
Key Capabilities
- Single-image parsing with two configuration modes: gundam (base_size=1024, image_size=640, crop_mode=True) for detailed document regions, and base (base_size=1024, image_size=1024) for full-page processing.
- Multi-page and PDF parsing using the base configuration, converting PDF pages to images at configurable DPI.
- Structured Markdown output for parsed document content.
Benchmark Performance
On the ParseBench benchmark, Unlimited-OCR achieves the following scores:
| Metric | Score | Rank |
|---|---|---|
| Mean | 46.17 | #13 |
| Text Content | 86.81 | #9 |
| Text Formatting | 0.97 | #18 |
| Layout | 71.52 | #6 |
| Chart | 1.34 | #13 |
| Table | 70.21 | #12 |
The model has received 885,040 total downloads and 1,690 likes on Hugging Face. R-SWA is a general-purpose parsing attention mechanism applicable beyond OCR to tasks such as ASR and translation.

best for
- ·Extracting text from multi-page scanned documents
- ·Parsing complex layouts with tables and charts
- ·One-shot transcription of lengthy PDF reports
FAQ
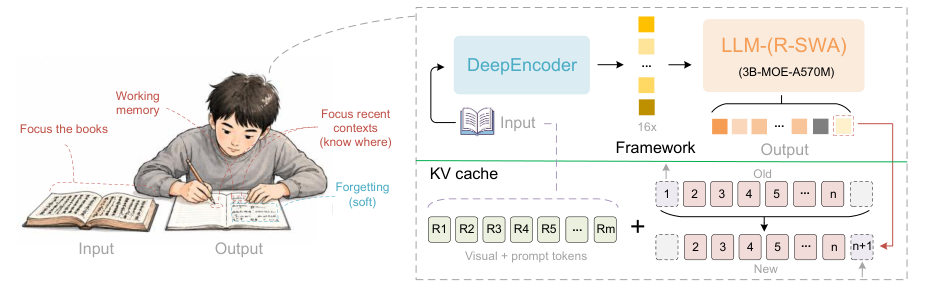
Unlimited OCR is designed for one-shot long-horizon document parsing, capable of transcribing dozens of pages in a single forward pass with constant KV cache memory.
It uses Reference Sliding Window Attention (R-SWA) to maintain a constant KV cache throughout decoding, avoiding the memory growth and slowdown that plagues standard transformers on long sequences.
The model accepts single images (with two modes: gundam and base) and multi-page PDFs (converted to images, base mode only). All inputs are processed under a 32K token context length.
Use the OpenAI-compatible endpoint at gigarouter with your API key. Send a chat completion request containing a user message with an image_url and text prompt, then set the model parameter to 'Unlimited-OCR'.
Gundam mode uses base_size=1024, image_size=640 with cropping for single images. Base mode uses image_size=1024 without cropping and is required for multi-page or PDF inputs.
We're benchmarking and onboarding Unlimited OCR as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.