BLIP-2 OPT 2.7B
Salesforce/blip2-opt-2.7b
published Feb 2023 · updated Feb 2025
BLIP-2 OPT 2.7B is a vision-language model that uses a frozen CLIP-like image encoder and a frozen OPT-2.7B language model bridged by a lightweight Querying Transformer for tasks like image captioning and visual question answering.
specs
| Task | Vision-Language Pretraining (image captioning, visual question answering) |
| Architecture | CLIP-like image encoder + Querying Transformer (Q-Former) + OPT-2.7B language model |
| Parameters | 2.7 billion (OPT-2.7B) plus Q-Former |
| License | BSD-3-Clause |
about this model
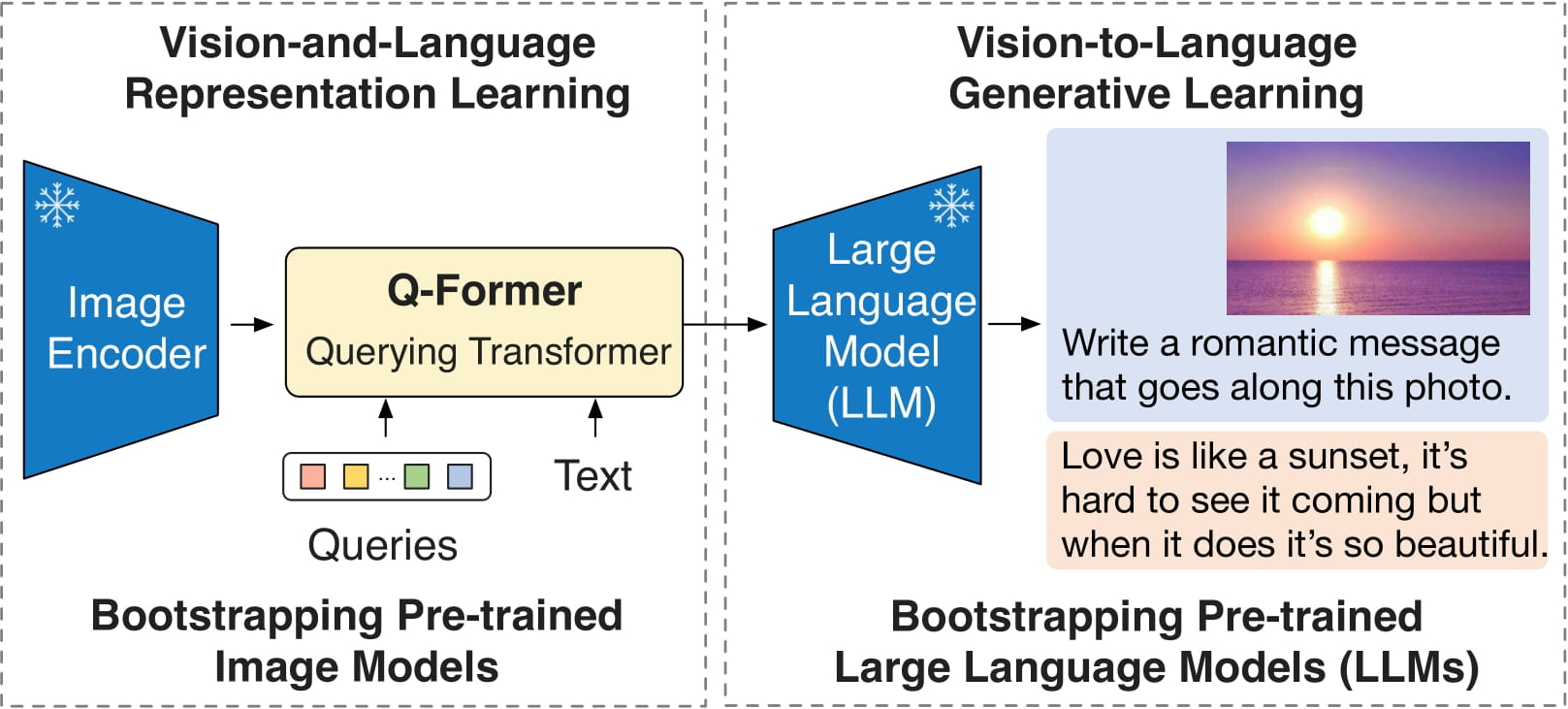 The model inherits limitations common to large language models, such as potential bias, hallucination, and sensitivity to training data quality. It has not been tested in real-world applications and is intended for research purposes. The pre-trained checkpoint is available through gigarouter’s hosted API, enabling access without local infrastructure.
The model inherits limitations common to large language models, such as potential bias, hallucination, and sensitivity to training data quality. It has not been tested in real-world applications and is intended for research purposes. The pre-trained checkpoint is available through gigarouter’s hosted API, enabling access without local infrastructure.best for
- ·Generating captions for images
- ·Answering natural language questions about images
FAQ
Image captioning and visual question answering (VQA).
An image (via URL or base64) and an optional text prompt.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending a request with image and optional prompt.
About 7.21 GB total size.
Yes, it can be used for chat-like conversations by feeding the image and previous conversation as prompt.
We're benchmarking and onboarding BLIP-2 OPT 2.7B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.