Qwen3-VL 2B Instruct
Qwen/Qwen3-VL-2B-Instruct
published Oct 2025 · updated Oct 2025
Qwen3-VL 2B Instruct is a vision-language model that delivers advanced text understanding, visual perception, reasoning, and agent capabilities for images, videos, and documents.
specs
| Task | Vision-Language Understanding & Generation |
| Architecture | Dense Transformer with Interleaved-MRoPE, DeepStack, and Text–Timestamp Alignment |
| Parameters | 2B |
| License | Apache 2.0 |
about this model
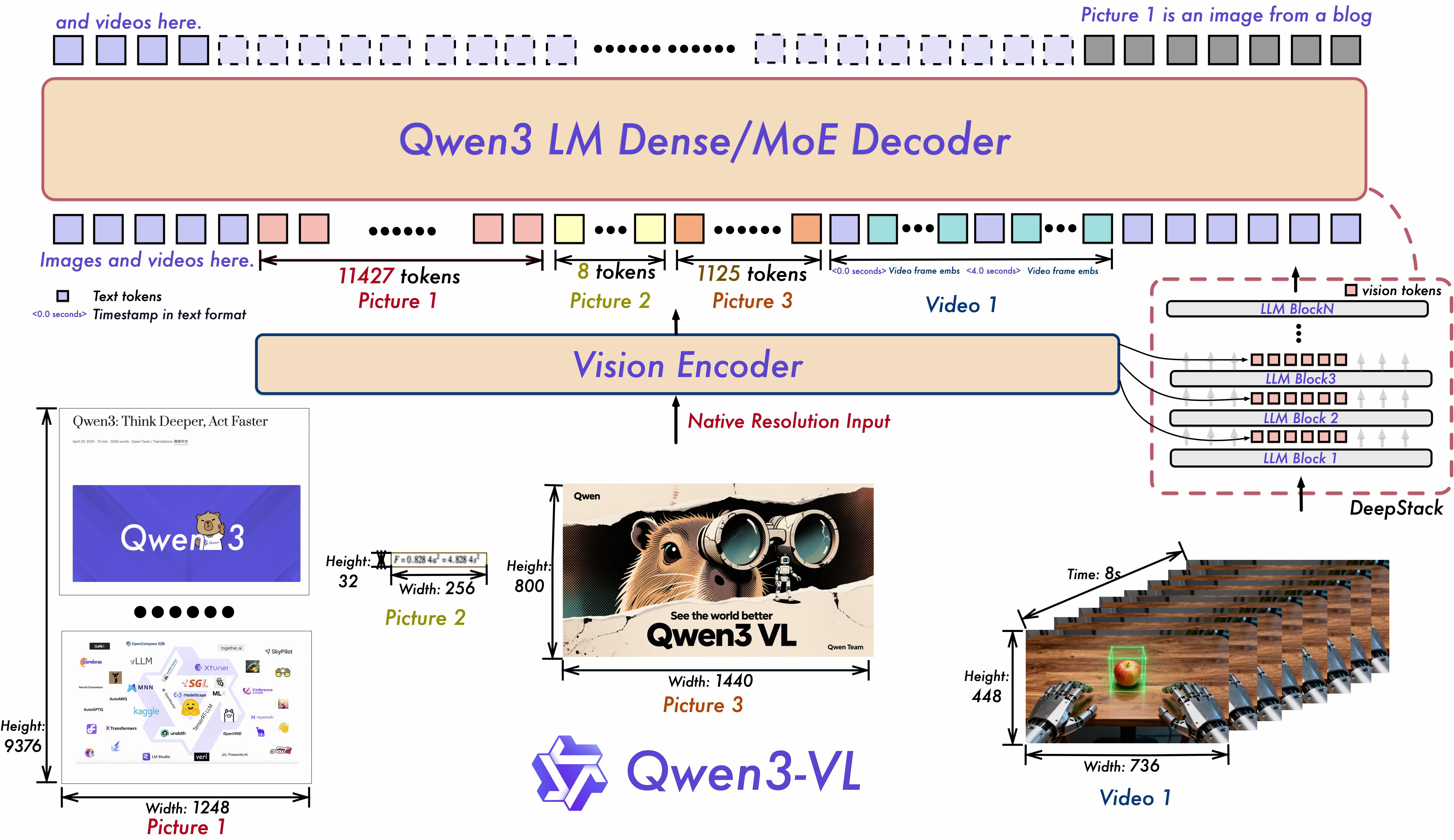
Architecture
The model incorporates three key architectural innovations:
- Interleaved-MRoPE – full-frequency positional embeddings over time, width, and height for improved video reasoning.
- DeepStack – fuses multi-level ViT features to capture fine-grained details and sharpen image-text alignment.
- Text–Timestamp Alignment – enables precise, timestamp-grounded event localization for temporal video modeling.
Performance
Evaluated on standard multimodal and pure-text benchmarks, Qwen3-VL-2B-Instruct demonstrates competitive results within its size class.
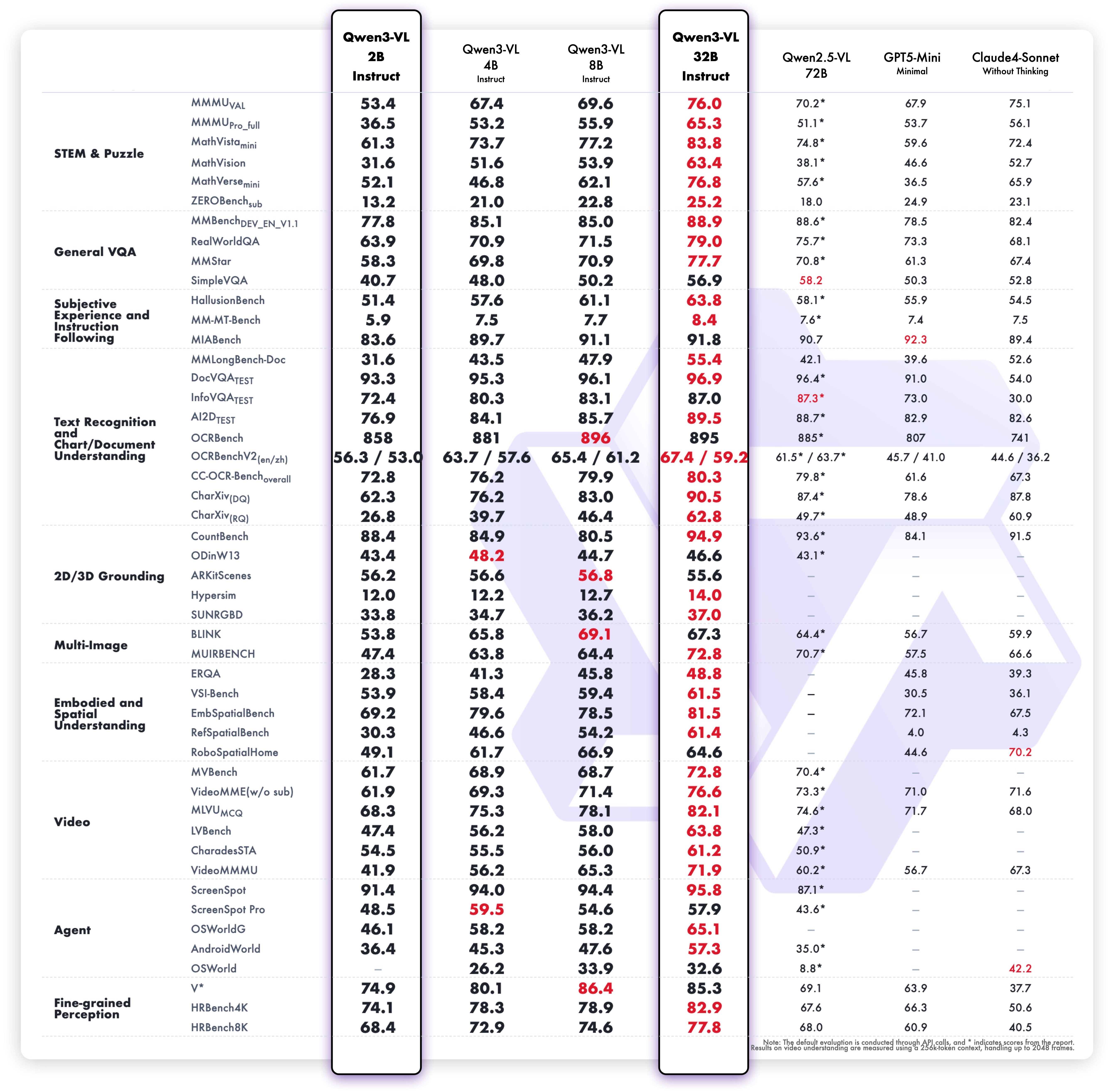
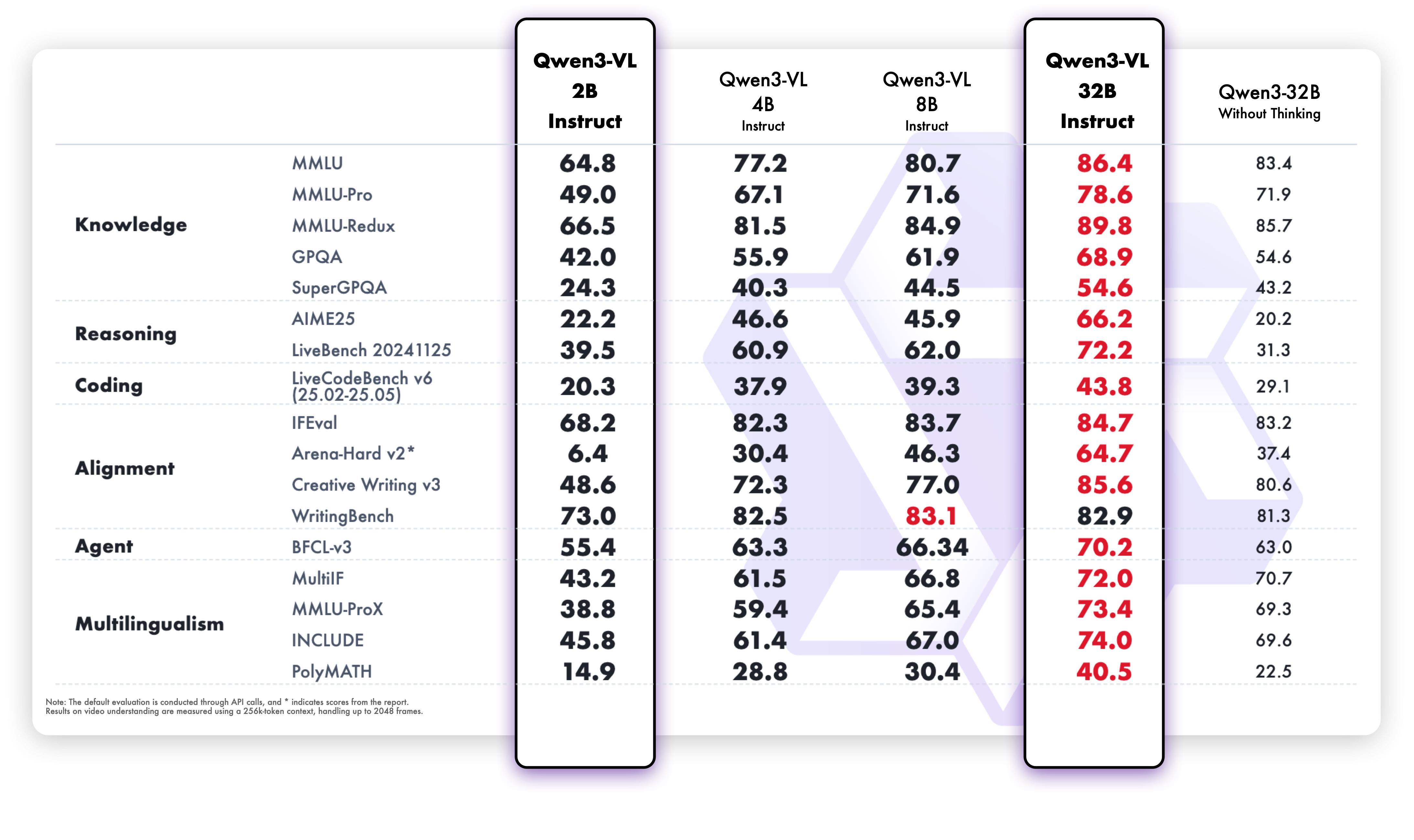
The model is released under the Apache 2.0 license. It supports a thinking budget mechanism for adaptive inference resource allocation, and its training leverages knowledge from larger flagship models to achieve strong performance with minimal computational overhead.
best for
- ·Visual GUI automation on PC and mobile devices (element recognition, tool invocation)
- ·Multilingual OCR and document parsing (32 languages, low-light/blur/tilt robust)
- ·Long-context video understanding (up to 256K tokens native, expandable to 1M)
- ·Spatial reasoning and 2D/3D grounding for embodied AI
FAQ
It supports native 256K tokens, expandable to 1M tokens for long documents and hours-long video.
It is the smallest dense variant in the Qwen3-VL family, optimized for edge and lightweight deployments while still offering strong vision-language capabilities.
It allows users to allocate computational resources adaptively during inference, balancing latency and performance based on task complexity.
OCR supports 32 languages; the underlying Qwen3 LLM supports 119 languages for text.
Use the OpenAI-compatible endpoint with your gigarouter API key, sending image and text inputs in the standard chat completion format.
We're benchmarking and onboarding Qwen3-VL 2B Instruct as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.