Qwen2.5-VL 7B Instruct AWQ
Qwen/Qwen2.5-VL-7B-Instruct-AWQ
published Feb 2025 · updated Apr 2025
Qwen2.5-VL 7B Instruct AWQ is a vision-language model that understands images, videos, and text, supports agentic tool use, and provides structured outputs and visual localization.
specs
| Task | Vision-Language (VLM) |
| Architecture | Vision Transformer (ViT) with SwiGLU and RMSNorm, plus Qwen2.5 LLM |
| Parameters | 7B |
| License | Not specified in card |
about this model
Key Capabilities
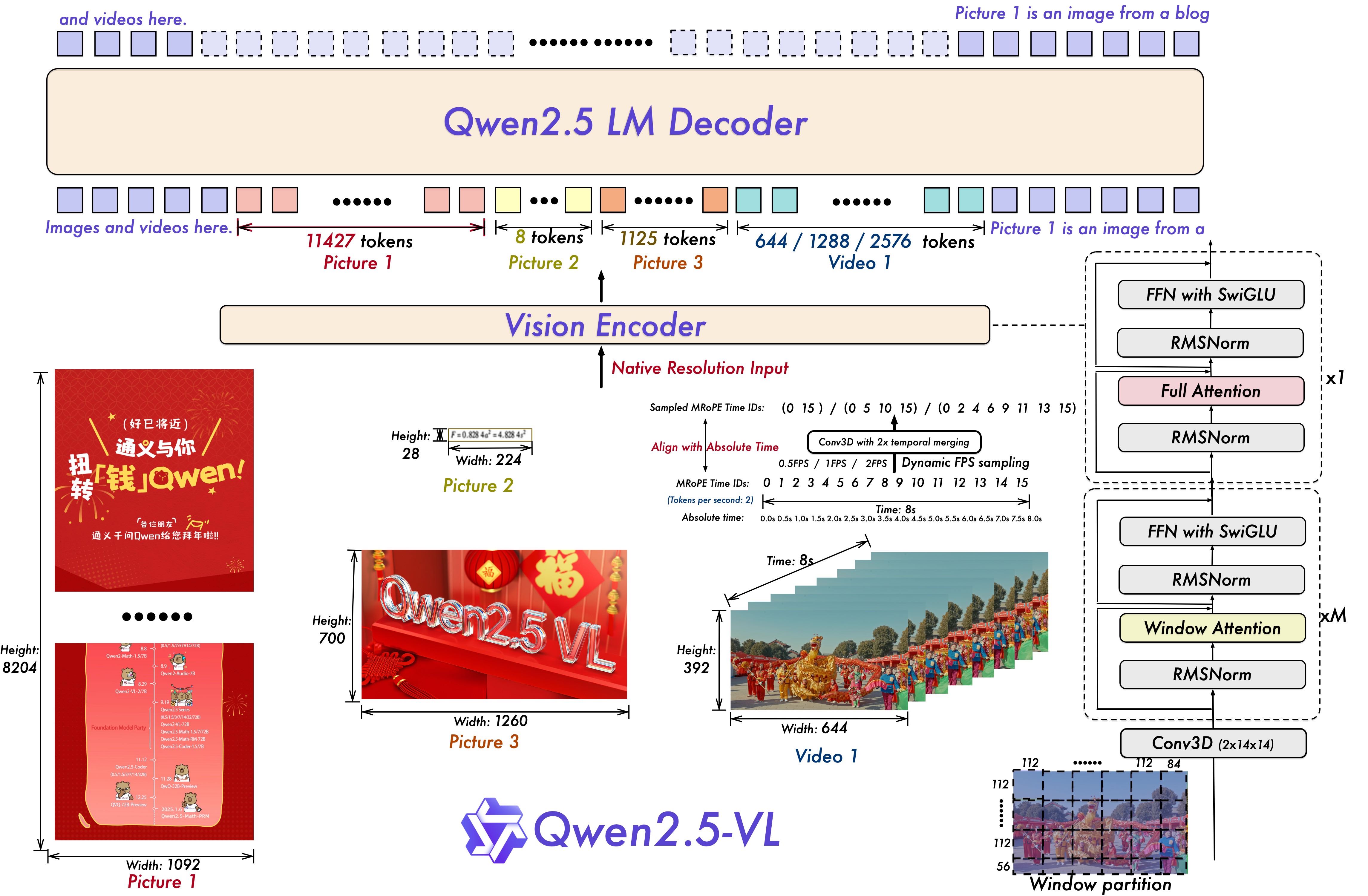
- Dynamic Resolution & Video Understanding: The model handles images at native resolution and supports variable frame rate sampling for videos, enabling comprehension of content over one hour long and pinpointing specific events.
- Visual Agent & Localization: It can act as a visual agent for computer and phone use, generate bounding boxes or points for object localization, and produce stable JSON outputs for coordinates and attributes.
- Structured Outputs: Scanned invoices, forms, tables, and similar documents are processed into structured data, benefiting finance, commerce, and document analysis workflows.
- Extended Context: The model supports YaRN for context extension beyond 32,768 tokens, allowing handling of longer sequences with a factor of 4.
Benchmark Performance (AWQ Quantized)
Evaluated using VLMEvalKit, the 7B AWQ model achieves the following scores:
| Benchmark | Score |
|---|---|
| MMMU_VAL (Accuracy) | 55.6 |
| DocVQA_VAL (Accuracy) | 94.6 |
| MMBench_DEV_EN (Accuracy) | 84.2 |
| MathVista_MINI (Accuracy) | 64.7 |
For comparison, the BF16 version of the same model achieves 58.4, 94.9, 84.1, and 67.9 respectively. The 7B model also outperforms GPT-4o-mini on several college-level, math, document understanding, and video understanding tasks (source: official blog).
Architecture
The vision encoder uses window attention, SwiGLU, and RMSNorm, aligned with the Qwen2.5 LLM. M-RoPE with absolute time alignment enables temporal sequence learning, and the model supports dynamic resolution for both spatial and temporal dimensions.
best for
- ·Visual question answering and image description
- ·Document and invoice data extraction with structured JSON output
- ·Long video understanding and event localization
FAQ
It accepts images (local files, URLs, base64), videos (local files), and text in a chat template.
Use the OpenAI-compatible endpoint with your API key, sending a chat completion request with image and text inputs.
Yes, it supports YaRN for extending context up to 4x the original 32,768 tokens, though this may affect spatial/temporal localization tasks.
AWQ reduces model size and speeds inference with minimal accuracy loss; e.g., on MMMU_VAL it scores 55.6 vs 58.4 for BF16.
We're benchmarking and onboarding Qwen2.5-VL 7B Instruct AWQ as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.