Qwen2-VL 7B Instruct
Qwen/Qwen2-VL-7B-Instruct-AWQ
published Aug 2024 · updated Sep 2024
Qwen2-VL 7B Instruct is a vision-language model that understands images, videos, and text, supporting dynamic resolution, multilingual text, and agent operations.
specs
| Task | Image-text-to-text (Vision-Language Understanding) |
| Architecture | Transformer with Multimodal Rotary Position Embedding (M-ROPE) and Naive Dynamic Resolution |
| Parameters | 7 billion |
| License | Apache 2.0 |
about this model
Qwen2-VL-7B-Instruct-AWQ is a vision-language model (VLM) that processes images, videos, and text for tasks such as visual question answering, document understanding, and multimodal reasoning. It is the instruction-tuned 7B-parameter variant of the Qwen2-VL series, quantized with AWQ for efficient deployment under an Apache 2.0 license. The model is associated with the paper Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution (arXiv:2409.12191) and is categorized as an image-text-to-text pipeline.
Key Capabilities
- Dynamic resolution: The Naive Dynamic Resolution mechanism maps arbitrary image resolutions to a variable number of visual tokens, adapting to content complexity.
- Multimodal positional encoding: Multimodal Rotary Position Embedding (M-RoPE) decomposes positional information into 1D textual, 2D visual, and 3D video components.
- Extended video understanding: Capable of comprehending videos longer than 20 minutes for QA, dialog, and content creation.
- Agentic operation: Can be integrated with mobile phones, robots, and other devices to perform actions based on visual input and text instructions.
- Multilingual image text: Supports reading text in images across English, Chinese, most European languages, Japanese, Korean, Arabic, Vietnamese, and others.
Architecture
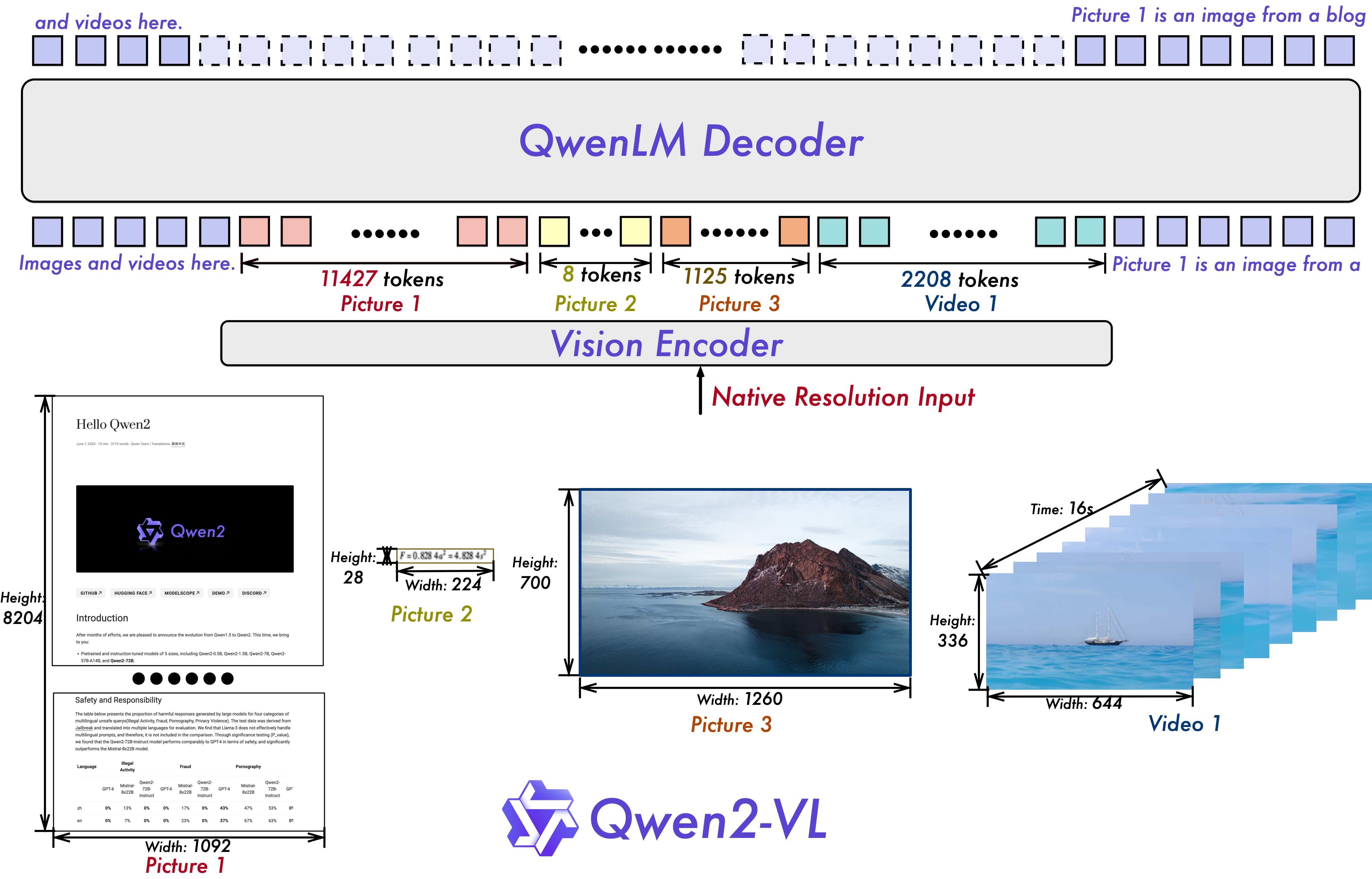

Benchmark Performance (AWQ Quantization)
| Benchmark | Accuracy |
|---|---|
| MMMU_VAL | 53.66 |
| DocVQA_VAL | 93.10 |
| MMBench_DEV_EN | 81.61 |
| MathVista_MINI | 56.80 |
Inference Speed (AWQ, single A100 80GB, batch size 1)
| Input Length | Speed (tokens/s) | GPU Memory (GB) |
|---|---|---|
| 1 | 32.08 | 7.07 |
| 6144 | 32.66 | 12.56 |
| 14336 | 31.42 | 20.07 |
| 30720 | 19.95 | 35.08 |
best for
- ·Document and chart question answering
- ·Video content analysis and summarization
- ·Visual agent for GUI automation and mobile operation
- ·Multilingual text extraction from images
FAQ
It excels at visual understanding, document QA, video comprehension, and agent tasks, achieving state-of-the-art on benchmarks like DocVQA, MTVQA, and MathVista.
The model is released under the Apache 2.0 license.
It supports images (URLs, base64, file paths), videos (as frame lists or video files), and text, with dynamic resolution handling.
Use the OpenAI-compatible endpoint with your API key, sending image and text inputs as specified in the gigarouter documentation.
It achieves competitive performance against leading models, with state-of-the-art results on DocVQA and MTVQA, and matches GPT-4o and Claude 3.5 on several benchmarks.
We're benchmarking and onboarding Qwen2-VL 7B Instruct as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.