Qwen2-VL 7B Instruct
Qwen/Qwen2-VL-7B-Instruct
published Aug 2024 · updated Feb 2025
Qwen2-VL 7B Instruct is a vision-language model that understands images, videos, and text with state-of-the-art performance on visual understanding benchmarks.
specs
| Task | Multimodal Understanding (Image, Video, Text) |
| Architecture | Vision-Language Model with Naive Dynamic Resolution and Multimodal Rotary Position Embedding (M-ROPE) |
| Parameters | 7 billion |
| License | Apache 2.0 |
about this model
Qwen2-VL-7B-Instruct is a vision-language model (VLM) that processes images and videos at arbitrary resolutions, supporting text-based question answering, document parsing, video understanding, and visual agent tasks.
Capabilities and Architecture
The model introduces Naive Dynamic Resolution, mapping images of varying sizes into a dynamic number of visual tokens for efficient representation. Multimodal Rotary Position Embedding (M-RoPE) captures 1D textual, 2D visual, and 3D video positional information, enabling coherent multimodal processing. Qwen2-VL-7B-Instruct can understand videos over 20 minutes and supports multilingual text within images, including European languages, Japanese, Korean, Arabic, and Vietnamese.
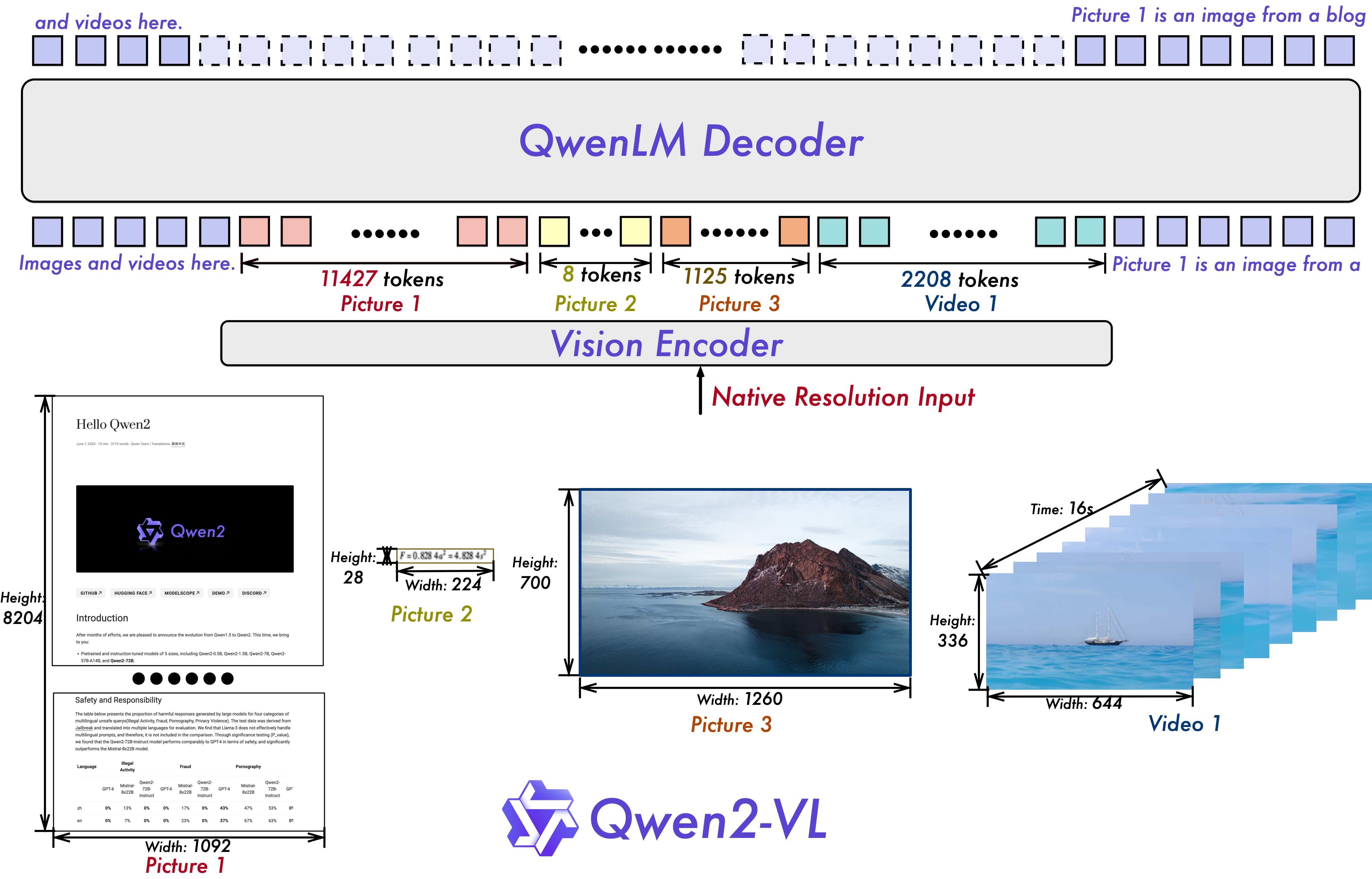

Benchmark Performance
On image understanding benchmarks, Qwen2-VL-7B-Instruct achieves strong results:
| Benchmark | Score | Comparison |
|---|---|---|
| DocVQA | 94.5 | Outperforms InternVL2-8B (91.6) and MiniCPM-V 2.6 (90.8) |
| MTVQA | 26.3 | No comparable scores listed for other models |
| RealWorldQA | 70.1 | Outperforms InternVL2-8B (64.4) |
| TextVQA | 84.3 | Outperforms InternVL2-8B (77.4) and MiniCPM-V 2.6 (80.1) |
| MMMU | 54.1 | Below GPT-4o-mini (60) but competitive |
| MMVet | 62.0 | Below GPT-4o-mini (66.9) but above InternVL2-8B (54.2) |
On video benchmarks, the model leads in its size class:
| Benchmark | Score | Comparison |
|---|---|---|
| Video-MME | 63.3 / 69.0 | Outperforms InternVL2-8B (54.0/56.9) and MiniCPM-V 2.6 (60.9/63.6) |
| MVBench | 67.0 | Outperforms InternVL2-8B (66.4) and LLaVA-OneVision-7B (56.7) |
Additional benchmarks include MMBench-EN (83.0), MMBench-V1.1 (80.7), and HallBench (50.6). The model is released under the Apache 2.0 license.
best for
- ·Document and chart understanding (e.g., DocVQA, ChartQA)
- ·Long-form video question answering (20+ minutes)
- ·Visual agent for operating mobile phones and robots
FAQ
It is released under the Apache 2.0 license.
It supports images, videos, and text. It can handle arbitrary image resolutions via Naive Dynamic Resolution.
It outperforms GPT-4o-mini on many benchmarks, including MMMU, DocVQA, TextVQA, and RealWorldQA.
Yes, it supports text understanding in multiple languages including English, Chinese, most European languages, Japanese, Korean, Arabic, and Vietnamese.
Use the OpenAI-compatible endpoint with your API key. The model accepts text, image URLs, and video inputs in the standard chat format.
We're benchmarking and onboarding Qwen2-VL 7B Instruct as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.