UI-TARS 2B SFT
ByteDance-Seed/UI-TARS-2B-SFT
published Jan 2025 · updated Jan 2025
UI-TARS 2B SFT is a vision-language model that acts as a native GUI agent, perceiving screenshots and performing human-like interactions to automate tasks on graphical user interfaces.
specs
| Task | GUI agent (perception, grounding, and action) |
| Architecture | Vision-Language Model (VLM) |
| Parameters | 2B |
| License | Unknown |
about this model
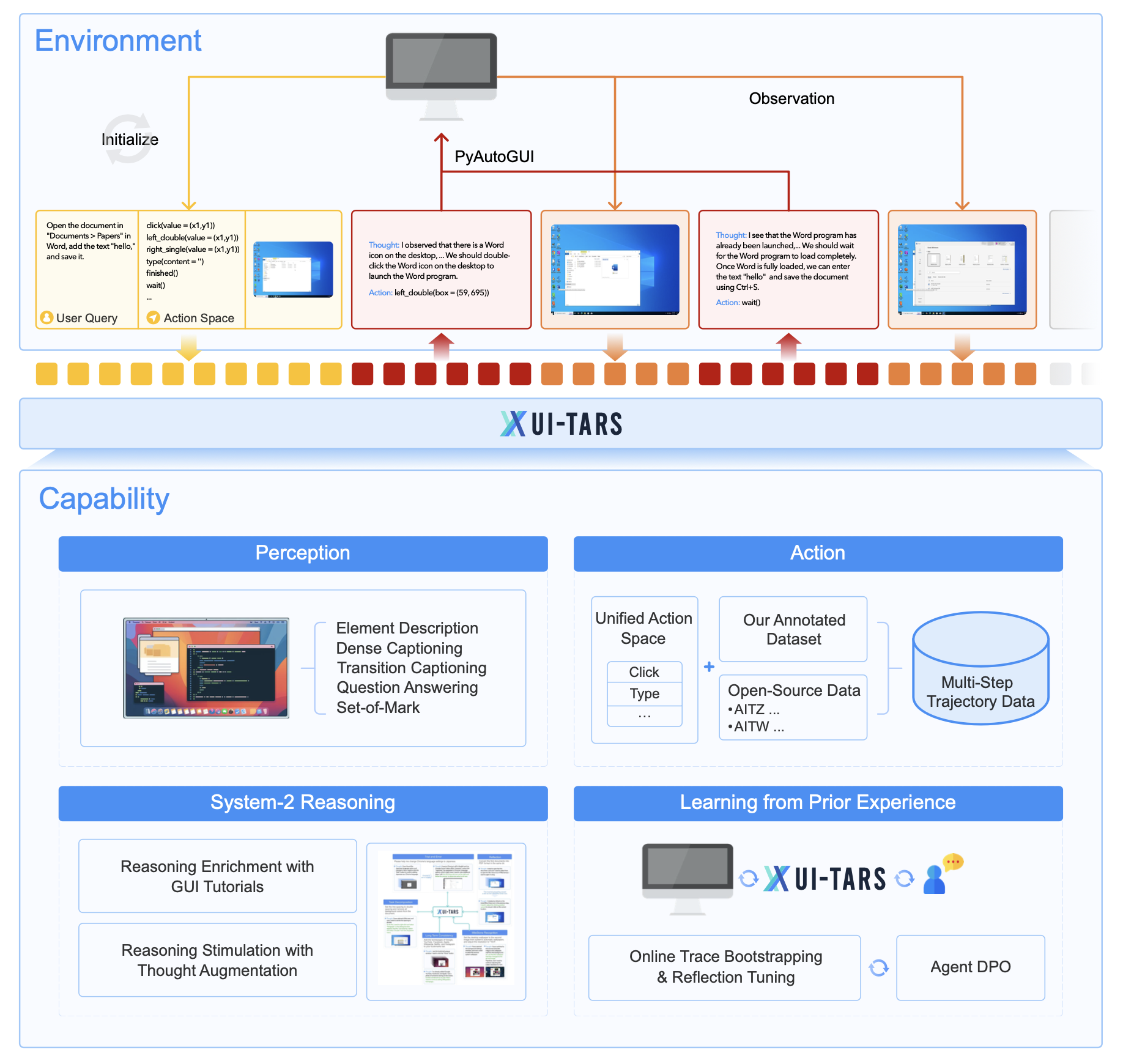
UI-TARS-2B-SFT is a vision-language model (VLM) designed as a native GUI agent that perceives screenshots and performs human-like interactions such as keyboard and mouse operations, integrating perception, reasoning, grounding, and memory within a single model.
Key Capabilities and Performance
UI-TARS-2B-SFT achieves competitive results across multiple GUI benchmarks, demonstrating strong perception, grounding, and task execution abilities without relying on external frameworks or hand-crafted prompts.
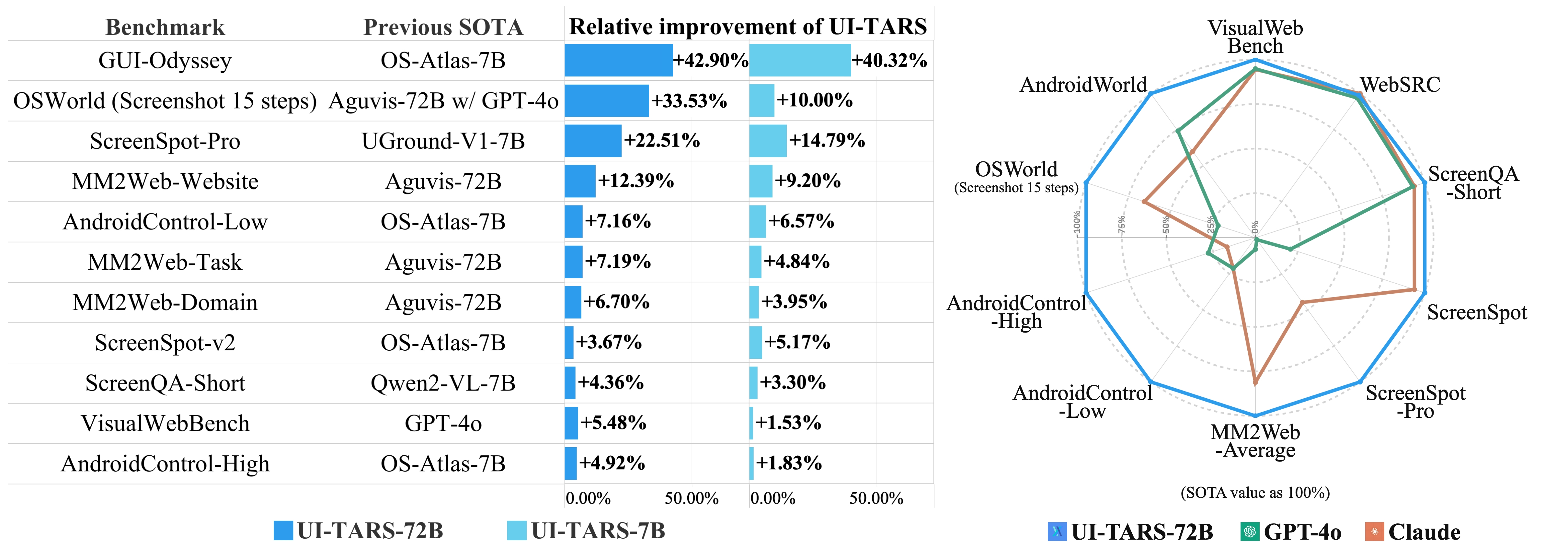
Benchmark Results
Perception
- VisualWebBench: 72.9
- WebSRC: 89.2
- SQAshort: 86.4
Grounding
- ScreenSpot Pro (overall): 27.7 — top performing model under 3B parameters on this leaderboard.
- ScreenSpot (overall): 82.3
- ScreenSpot v2 (overall): 84.7
Offline Agent Task Execution
| Benchmark | Metric | Score |
|---|---|---|
| Multimodal Mind2Web (Cross-Task) | Element Accuracy | 62.3 |
| Operation F1 | 90.0 | |
| Step Success Rate | 56.3 | |
| OSWorld (50 steps) | Success Rate | 24.6 |
| OSWorld (15 steps) | Success Rate | 22.7 |
| AndroidWorld | Success Rate | 46.6 |
On OSWorld, UI-TARS-2B-SFT outperforms Claude (22.0 and 14.9 respectively); on AndroidWorld, it surpasses GPT-4o (34.5), as reported in the associated paper.
Innovations
The model incorporates enhanced perception through large-scale GUI screenshot datasets, unified action modeling across platforms, System-2 reasoning (task decomposition, reflection, milestone recognition), and iterative training with reflective online traces collected from hundreds of virtual machines.
Note: Newer model versions (UI-TARS-1.5 and UI-TARS-2) with extended capabilities in games, code, and tool use have been released by the authors.
best for
- ·Automating GUI interactions on mobile, desktop, and web platforms
- ·Performing precise UI element grounding and captioning from screenshots
- ·End-to-end task automation without predefined workflows or manual rules
FAQ
It is best for automating GUI interactions by perceiving screenshots and performing human-like actions like clicking and typing on mobile, desktop, and web interfaces.
UI-TARS 2B SFT is the smallest model in the UI-TARS family. It achieves competitive performance on perception and grounding benchmarks (e.g., 82.3 on ScreenSpot, 27.7 on ScreenSpot Pro) while being faster and more lightweight than the 7B and 72B variants.
The model takes a screenshot image as input and outputs text describing the action to take (e.g., click, type) along with coordinates for grounding. It uses absolute coordinates based on the Qwen 2.5VL architecture.
Use the gigarouter OpenAI-compatible endpoint with your API key. Send a request with the screenshot image and a prompt describing the task, and the model will return the predicted action and coordinates.
UI-TARS integrates perception, reasoning, grounding, and memory into a single VLM. Key innovations include enhanced perception via large-scale GUI data, unified action modeling across platforms, System-2 reasoning (task decomposition, reflection), and iterative training with reflective online traces on virtual machines.
We're benchmarking and onboarding UI-TARS 2B SFT as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.