Locate Anything 3B
mudler/locate-anything.cpp-gguf
published Jun 2026 · updated Jun 2026
Locate Anything 3B is an open-vocabulary detection and visual grounding model that locates objects in images based on text prompts.
specs
| Task | Open-vocabulary detection / visual grounding |
| Architecture | Qwen2.5-3B (LM) + MoonViT (vision) + 2-layer MLP projector |
| Parameters | 3B |
| License | NVIDIA license (weights); MIT (GGUF repo) |
about this model
locate-anything.cpp-gguf is an open-vocabulary detection model that localizes objects in images from natural-language prompts. It is a C++/ggml port of NVIDIA’s LocateAnything-3B, producing detections identical to the official PyTorch version while running faster on both CPU and GPU.
Performance
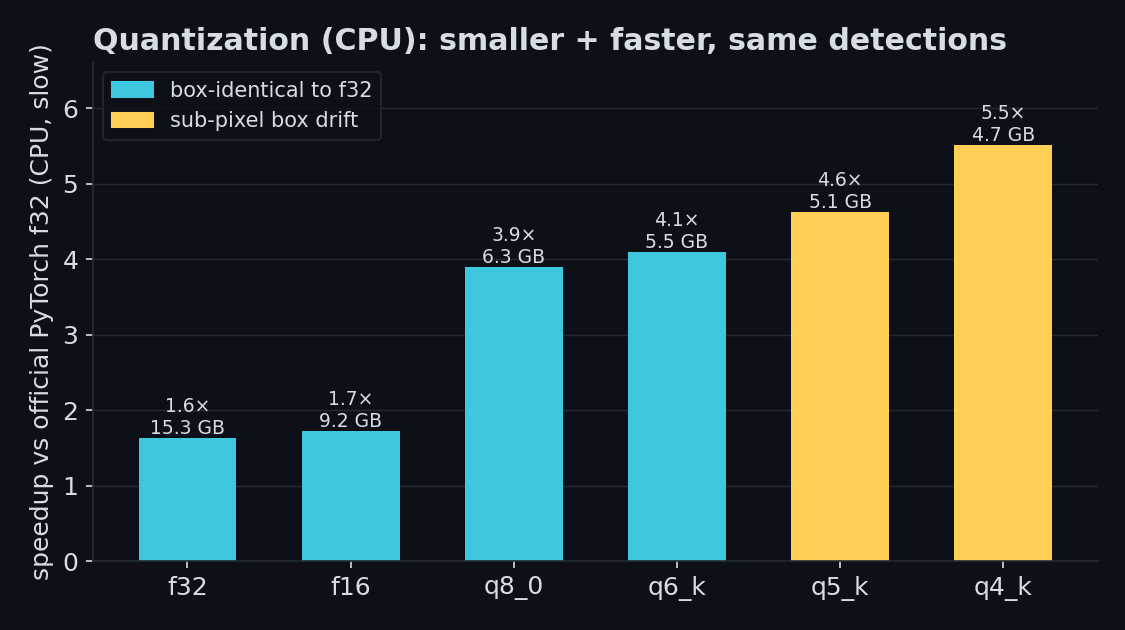
On a Ryzen 9 9950X3D (CPU, 16 threads, 448×448 fixture) the recommended q8_0 build (box-identical, 6.3 GB) delivers a 3.9× speedup over the official f32 model. q6_k (5.5 GB) is also box-identical at 4.1×. Lower-bit quantizations trade a small amount of box precision for further speed:
| dtype | size | infer | vs official f32 | boxes |
|---|---|---|---|---|
| f16 | 9.15 GB | 13.68 s | 1.7× | identical |
| q8_0 | 6.26 GB | 6.07 s | 3.9× | identical |
| q6_k | 5.51 GB | 5.77 s | 4.1× | identical |
| q5_k | 5.10 GB | 5.11 s | 4.6× | sub-pixel |
| q4_k | 4.72 GB | 4.29 s | 5.5× | sub-pixel |
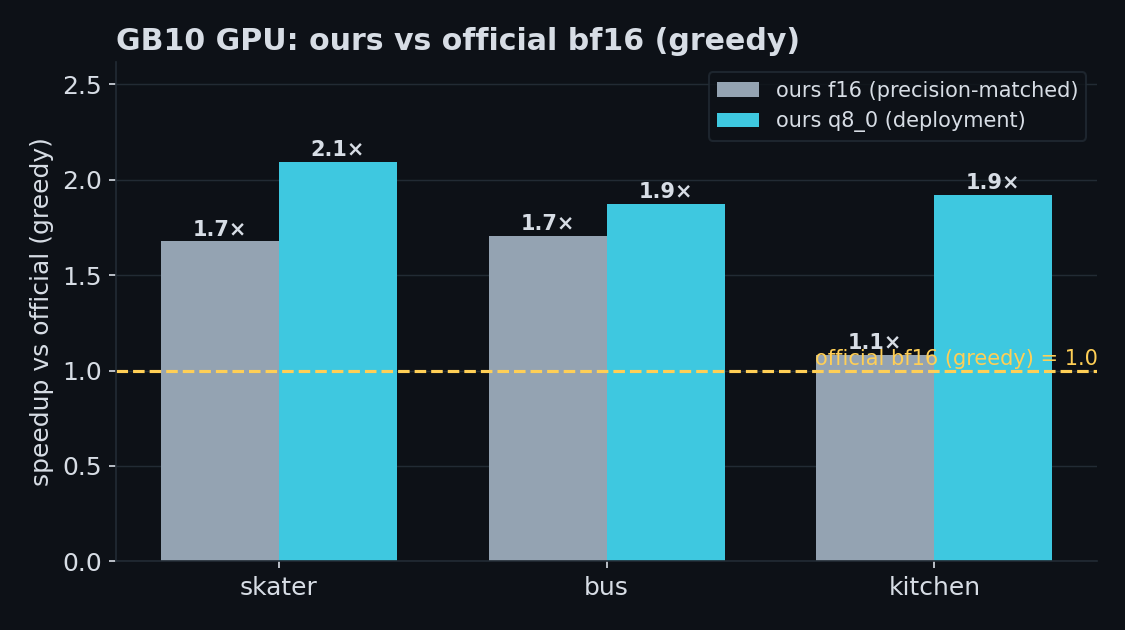
On an NVIDIA GB10 GPU (against the official bf16 model) the f16 build is ~1.7× faster; the box-identical q8_0 build is ~1.9–2.1× faster:
Quantization Policy
Only the Qwen2 language-model matmuls are quantized; the MoonViT vision tower, projector, norms, and biases remain in f32. This preserves box parity through q6_k. The model can also run in three decode modes (slow, hybrid, fast) with IoU ≥0.999 against official outputs.
best for
- ·Detecting arbitrary objects in images from natural language descriptions
- ·Visual grounding tasks where you need bounding boxes for specific text queries
- ·Building lightweight, dependency-free detection pipelines without Python at inference
FAQ
Input: an image and a text prompt (e.g., "Locate all the instances that matches the following description: person</c>car."). Output: a JSON list of detections with labels and bounding boxes, plus an optional annotated PNG.
On CPU, the recommended q8_0 GGUF is ~3.9× faster than official PyTorch f32 and box-identical. On GPU (NVIDIA GB10), it is ~1.9–2.1× faster than official bf16.
Available: f16, q8_0, q6_k, q5_k, q4_k. The q8_0 GGUF is recommended as the sweet spot: box-identical to f32, less than half the size, and ~3.9× faster than official PyTorch.
The model weights are under NVIDIA's license (not standard open-source). The GGUF repository is MIT-licensed. You must comply with NVIDIA's license for the weights.
Use the gigarouter OpenAI-compatible endpoint with your API key. Send a request with the image and prompt to the hosted model endpoint.
We're benchmarking and onboarding Locate Anything 3B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.