RT-DETR R50
PekingU/rtdetr_r50vd_coco_o365
published May 2024 · updated Jul 2024
RT-DETR R50 is a real-time end-to-end object detection model that uses a Transformer-based architecture with a ResNet-50 backbone, pretrained on COCO and Objects365.
specs
| Task | Object Detection |
| Architecture | RT-DETR (ResNet-50 backbone) |
| Parameters | 42M |
| License | Apache-2.0 |
about this model
PekingU/rtdetr_r50vd_coco_o365 is a detection model that performs real-time end-to-end object detection using the RT-DETR architecture, eliminating the need for non-maximum suppression (NMS) while achieving a competitive speed-accuracy trade-off. It is built on a hybrid encoder that decouples intra-scale interaction and cross-scale fusion to process multi-scale features efficiently, and it employs uncertainty-minimal query selection to provide high-quality initial queries to the decoder. The model supports flexible speed tuning by adjusting the number of decoder layers without retraining, making it adaptable to various deployment scenarios.
Key Results
The following table reports COCO val2017 metrics and inference throughput on a single T4 GPU (batch size 1, TensorRT FP16). The model is evaluated at 640×640 resolution after training on COCO train2017 with an additional pre-training stage on Objects365.
| Model variant | Epochs | Params (M) | GFLOPs | FPS | AP | AP50 | AP75 | AP_s | AP_m | AP_l |
|---|---|---|---|---|---|---|---|---|---|---|
| RT-DETR-R50 | 72 | 42 | 136 | 108 | 53.1 | 71.3 | 57.7 | 34.8 | 58.0 | 70.0 |
| RT-DETR-R101 | 72 | 76 | 259 | 74 | 54.3 | 72.7 | 58.6 | 36.0 | 58.8 | 72.1 |
| RT-DETR-R50 (Objects365) | 24 | 42 | 136 | 108 | 55.3 | 73.4 | 60.1 | 37.9 | 59.9 | 71.8 |
| RT-DETR-R101 (Objects365) | 24 | 76 | 259 | 74 | 56.2 | 74.6 | 61.3 | 38.3 | 60.5 | 73.5 |
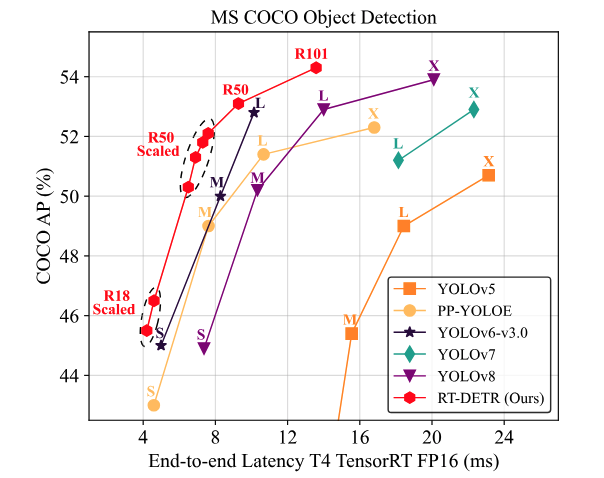
After pre-training on Objects365, the RT-DETR-R50 model achieves 55.3% AP (a +2.2% gain over the COCO-only variant) while maintaining 108 FPS. Compared to DINO-R50, RT-DETR-R50 improves AP by 2.2% and throughput by approximately 21×. The paper was accepted to CVPR 2024.
Architecture Overview
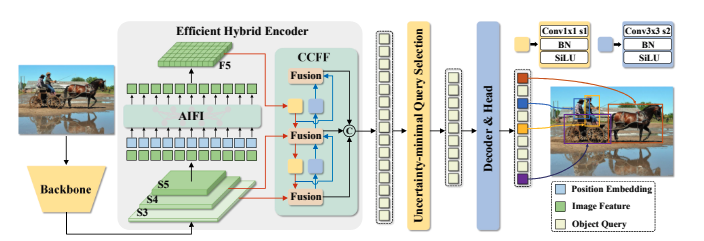
The efficient hybrid encoder combines Attention-based Intra-scale Feature Interaction (AIFI) and CNN-based Cross-scale Feature Fusion (CCFF) to transform multi-scale backbone features into a compact sequence. A fixed number of encoder features are then selected via uncertainty-minimal query selection to serve as initial object queries for the Transformer decoder, which iteratively refines them to predict categories and bounding boxes.
best for
- ·Real-time object detection in video streams (e.g., surveillance, autonomous driving)
- ·High-accuracy detection with low latency for industrial inspection
- ·Applications that benefit from eliminating NMS post-processing for simplified deployment
FAQ
The model expects images resized to 640x640 pixels, normalized with mean=[0.485, 0.456, 0.406] and std=[0.229, 0.224, 0.225]. It returns bounding boxes, class labels, and confidence scores.
On a T4 GPU with batch size 1 using TensorRT FP16, RT-DETR R50 achieves 108 FPS while maintaining 55.3 AP on COCO val2017.
It is licensed under Apache 2.0, allowing commercial and research use.
No, it is an end-to-end detector that eliminates NMS, simplifying the inference pipeline and improving speed.
Send a POST request to the gigarouter OpenAI-compatible endpoint with your API key and either an image URL or a base64-encoded image. The response will contain detection results.
We're benchmarking and onboarding RT-DETR R50 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.