PP-DocLayoutV3
PaddlePaddle/PP-DocLayoutV3_safetensors
published Jan 2026 · updated Jun 2026
PP-DocLayoutV3 is a detection model that analyzes document layout by predicting multi-point bounding boxes and logical reading order, handling non-planar, skewed, and curved document images in a single forward pass.
specs
| Task | Document Layout Analysis (Object Detection) |
| Architecture | Transformer-based object detection (AutoModelForObjectDetection) |
| License | Apache 2.0 |
about this model
PP-DocLayoutV3 is a layout analysis model that detects and reads document elements on non-planar surfaces, predicting multi-point bounding boxes and logical reading orders for skewed, curved, or warped documents in a single forward pass.
Capabilities and Architecture
Designed to handle real-world document distortions such as scanning artifacts, skew, warping, screen-photography, and uneven illumination, PP-DocLayoutV3 reduces cascading errors by directly outputting multi-point polygon coordinates and reading order simultaneously. The model architecture is illustrated below.
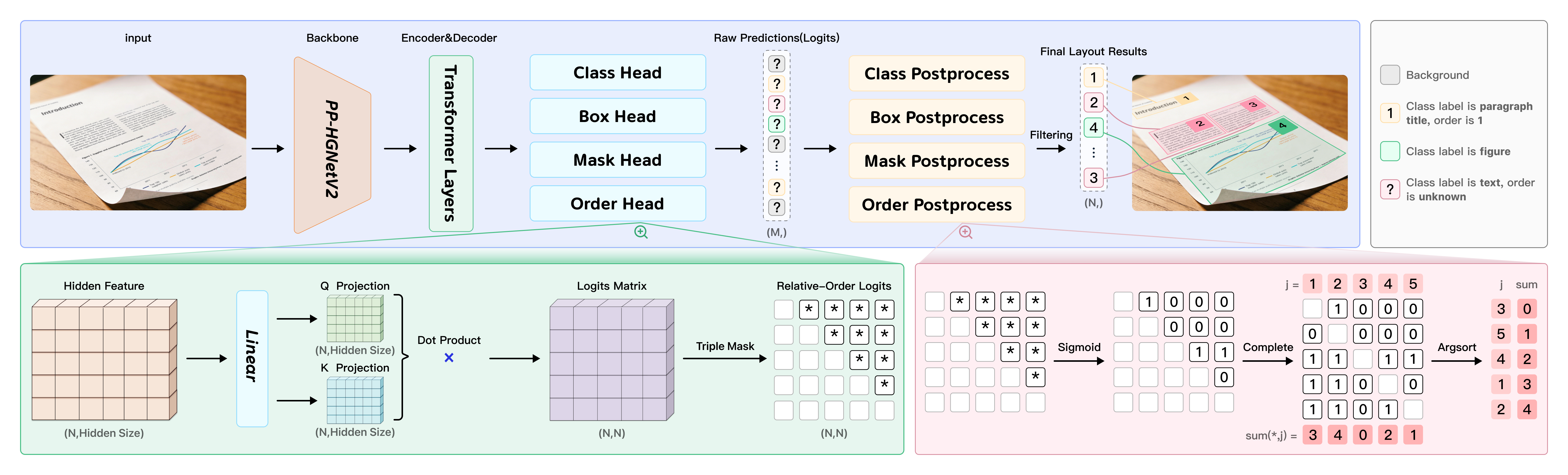
Benchmark Performance
PP-DocLayoutV3 achieves state-of-the-art accuracy of 94.5% on OmniDocBench v1.5 for document parsing and attains SOTA on the newly proposed Real5-OmniDocBench benchmark, which specifically tests robustness against physical distortions. The model is part of the PaddleOCR-VL-1.5 family and has been accepted to ECCV 2026. The broader PaddleOCR ecosystem is trusted by over 6,000 repositories.
Qualitative Examples
The following examples illustrate the model’s robustness under challenging conditions.


Ecosystem and Evolution
As a specialized layout analysis module, PP-DocLayoutV3 powers high-precision document parsing in PaddleOCR-VL-1.5. A subsequent version, PaddleOCR-VL-1.6 (0.9B parameters), extends accuracy to 96.3% on OmniDocBench v1.6.
best for
- ·Extracting layout structure from skewed or warped scanned documents
- ·Analyzing reading order on curved pages and non-planar surfaces
- ·Parsing document images captured under varying illumination or screen-photo conditions
FAQ
It is designed for robust document layout analysis on real-world images, including non-planar, skewed, and curved documents. It outputs multi-point bounding boxes and reading order, reducing cascading errors.
It directly predicts multi-point bounding boxes (instead of standard two-point boxes) and logical reading order in a single forward pass, handling skew, warping, and curved surfaces without additional correction steps.
Apache 2.0 license, as indicated in the model card.
Use the gigarouter OpenAI-compatible endpoint with your API key. Input an image URL or base64-encoded image; the model returns detection results with bounding boxes, polygon points, and labels.
It achieves 94.5% state-of-the-art accuracy on the OmniDocBench v1.5 benchmark for document parsing, and also SOTA on the Real5-OmniDocBench robustness benchmark.
We're benchmarking and onboarding PP-DocLayoutV3 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.