Lotus Depth G V1-0
jingheya/lotus-depth-g-v1-0
published Oct 2024 · updated Oct 2024
Lotus Depth G V1-0 is a diffusion-based depth estimation model that directly predicts annotations in a single step, achieving high-quality zero-shot depth estimation.
specs
| Task | Depth Estimation |
| Architecture | Diffusion-based (x₀-prediction, single-step reformulation, Detail Preserver) |
| Parameters | Not specified in card |
| License | Not specified in card |
about this model
Lotus-depth-g-v1-0 is a diffusion-based visual foundation model for high-quality monocular depth estimation, hosted as a managed API on gigarouter. The model is part of the Lotus family, accepted at ICLR 2025, and reformulates the diffusion process to directly predict depth annotations (x₀-prediction) instead of noise (ε-prediction), which the authors demonstrate is harmful for dense prediction. This single-step diffusion procedure at time-step t=T simplifies optimization and significantly boosts inference speed compared to existing diffusion-based methods.
Key Strengths
- Zero-shot generalization: Achieves state-of-the-art performance in zero-shot depth estimation across diverse datasets without scaling training data or model capacity.
- Efficiency: The single-step reformulation makes Lotus substantially faster than most diffusion-based dense prediction models.
- Detail Preserver mechanism: A novel tuning strategy (a switcher s) that toggles between image reconstruction and dense prediction, enabling more accurate and fine-grained depth maps.
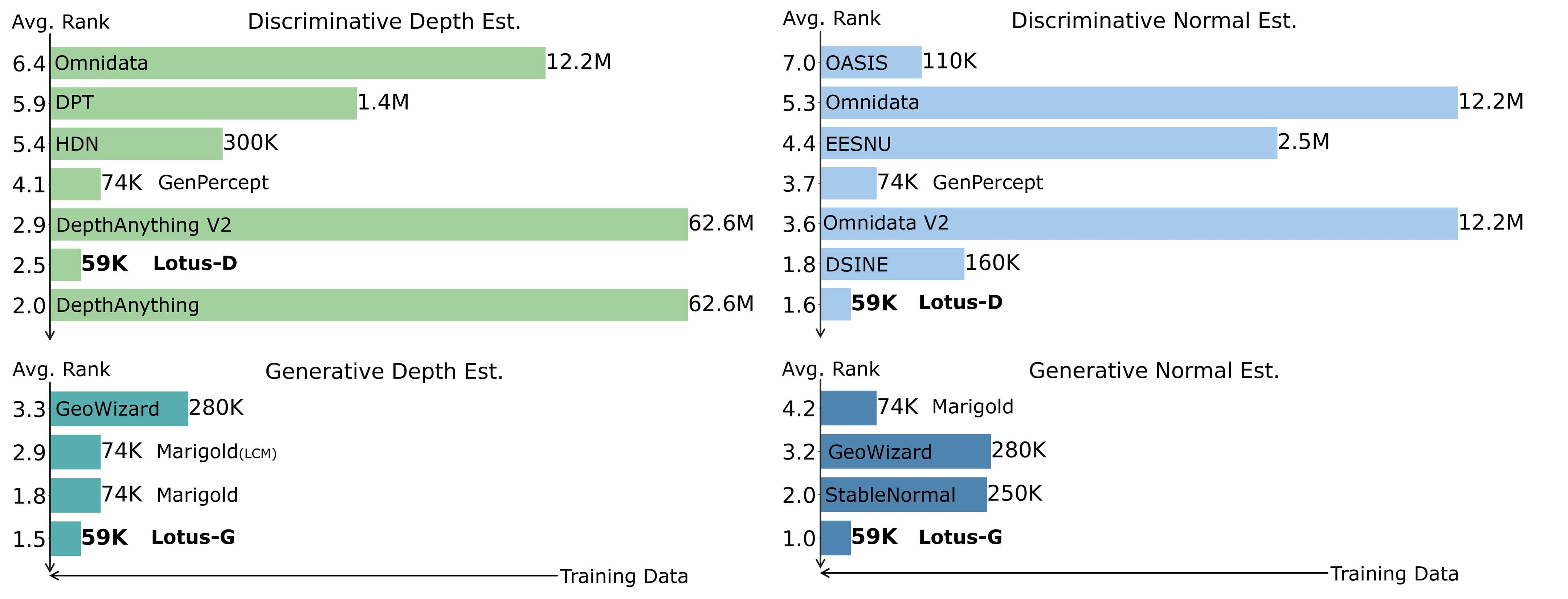
- Data efficiency: Trained on only 59,000 images, compared to 62.6 million images used by DepthAnything.
Benchmark Results
In zero-shot depth estimation, the generative Lotus-G variant outperforms all other methods. The discriminative Lotus-D variant is slightly inferior to DepthAnything but still competitive. The model leverages Stable Diffusion's pre-trained VAE encoder and denoiser U-Net as its backbone.
Visual Examples
The following images illustrate the model's depth estimation quality:

best for
- ·Zero-shot monocular depth estimation from a single image
- ·High-quality depth prediction for downstream 3D reconstruction tasks
FAQ
It uses a diffusion-based approach with x₀-prediction (predicting annotations directly instead of noise) and a single-step reformulation for faster inference.
The model takes a single RGB image as input.
Use the gigarouter OpenAI-compatible endpoint with your API key and the model ID jingheya/lotus-depth-g-v1-0.
Yes, the single-step diffusion reformulation significantly boosts inference speed compared to multi-step diffusion methods.
The license is not specified in the model card.
We're benchmarking and onboarding Lotus Depth G V1-0 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.