Depth Anything V2 Large
depth-anything/Depth-Anything-V2-Large-hf
published Jun 2024 · updated Jul 2024
Depth Anything V2 Large is a monocular depth estimation model that predicts dense depth maps from single images using a DPT architecture with a DINOv2 backbone.
specs
| Task | Monocular Depth Estimation |
| Architecture | DPT (Dense Prediction Transformer) with DINOv2 backbone |
| Training Data | ~600K synthetic labeled images + ~62M real unlabeled images |
about this model
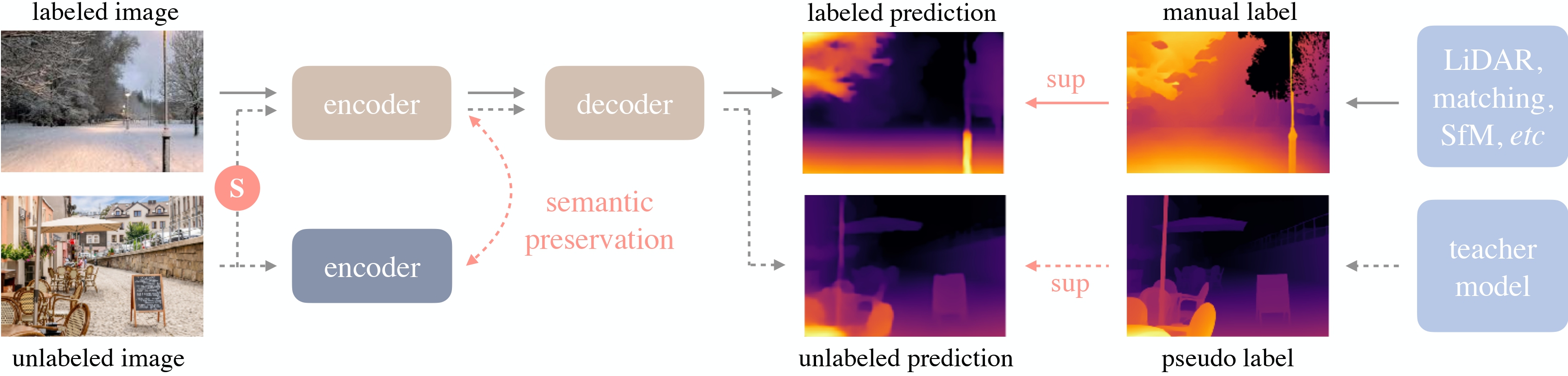
Depth-Anything-V2-Large is a monocular depth estimation model that produces fine-grained, robust depth predictions from a single image. It is trained on approximately 595K synthetic labeled images and over 62 million real unlabeled images, using a DPT architecture with a DINOv2 backbone.
Key strengths
- Delivers more detailed and robust depth maps than Depth Anything V1.
- Outperforms Stable Diffusion–based models (e.g., Marigold, Geowizard) in accuracy while being over 10× faster and more lightweight.
- Strong zero-shot generalization across diverse scenes and domains.
- Pre-trained weights enable impressive fine-tuned performance on metric depth estimation (e.g., NYUv2, KITTI).
Performance
On standard benchmarks, the model achieves state-of-the-art results for both relative and absolute depth estimation. The V2 pipeline replaces all labeled real images with synthetic data, scales the teacher model capacity, and uses large-scale pseudo-labeled real images for student training, yielding finer and more robust predictions than V1.
Availability
gigarouter hosts this model as a managed, OpenAI-compatible API. No local setup, pip installs, or GPU management required — simply call the API endpoint to run inference.
best for
- ·Zero-shot depth estimation on arbitrary images
- ·Fine-tuning for metric depth estimation on custom datasets
- ·Providing depth conditioning for image generation models like ControlNet
FAQ
It is designed for robust monocular depth estimation in zero-shot settings, producing finer and more robust depth predictions than V1 and SD-based models.
V2 produces much finer and more robust depth predictions by using synthetic labeled images, a larger teacher model, and large-scale pseudo-labeled real images.
Input: a single RGB image. Output: a depth map (same spatial resolution as the input after interpolation).
Use the gigarouter OpenAI-compatible endpoint with your API key; send an image URL or base64-encoded image and receive a depth map as response.
The model card does not specify a license; refer to the original repository for licensing details.
We're benchmarking and onboarding Depth Anything V2 Large as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.