DPT-Hybrid MiDaS
Intel/dpt-hybrid-midas
published Dec 2022 · updated Feb 2024
DPT-Hybrid MiDaS is a monocular depth estimation model that uses a Vision Transformer hybrid backbone to predict depth from a single image.
specs
| Task | Monocular Depth Estimation |
| Architecture | Dense Prediction Transformer (DPT) with ViT-hybrid backbone |
| Parameters | Not specified in card |
| License | MIT (per GitHub repo) |
about this model
DPT-Hybrid (Intel/dpt-hybrid-midas) is a monocular depth estimation model that uses a Vision Transformer (ViT) backbone with a hybrid architecture to predict depth from a single image. Introduced in Ranftl et al. (2021), the model was trained on the MIX 6 dataset (1.4 million images).
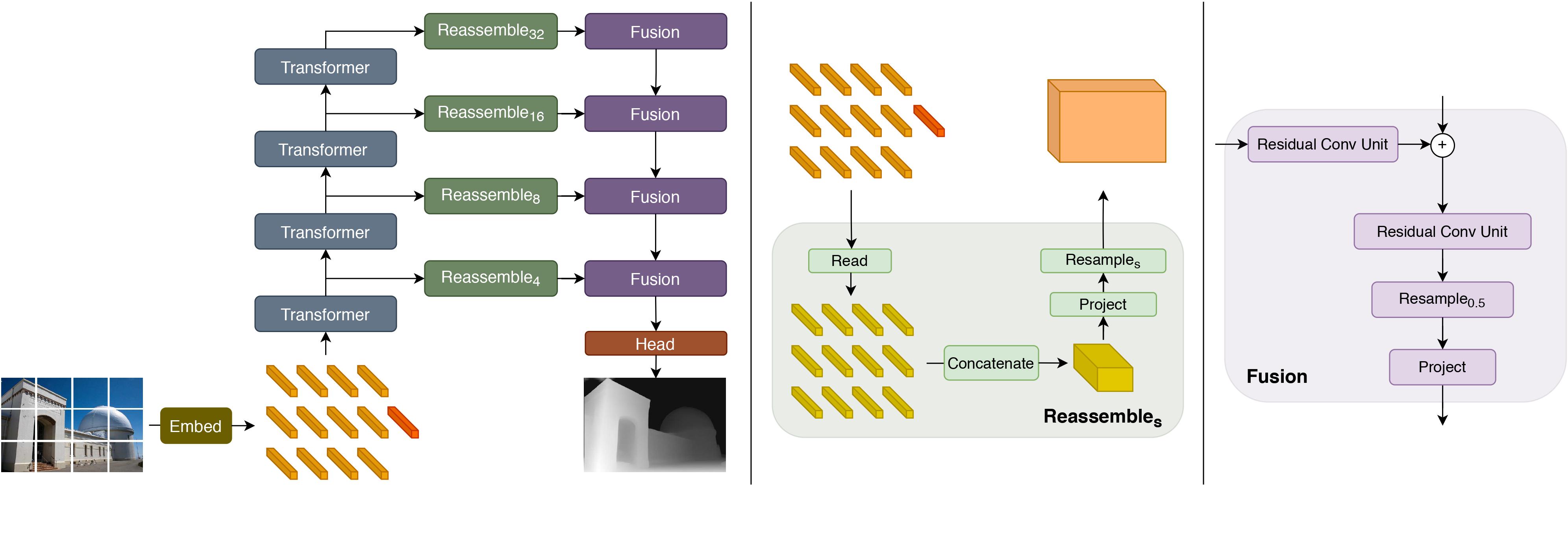
The model demonstrates strong zero-shot cross-dataset transfer performance. The following table compares DPT-Hybrid against prior methods on multiple datasets, with lower values being better for all metrics.
| Model | Training set | DIW WHDR | ETH3D AbsRel | Sintel AbsRel | KITTI δ>1.25 | NYU δ>1.25 | TUM δ>1.25 |
|---|---|---|---|---|---|---|---|
| DPT – Large | MIX 6 | 10.82 | 0.089 | 0.270 | 8.46 | 8.32 | 9.97 |
| DPT – Hybrid | MIX 6 | 11.06 | 0.093 | 0.274 | 11.56 | 8.69 | 10.89 |
| MiDaS | MIX 6 | 12.95 | 0.116 | 0.329 | 16.08 | 8.71 | 12.51 |
Fine-tuned variants of DPT-Hybrid have achieved additional results: on the KITTI Eigen split, the model fine-tuned on KITTI reports d1=0.959, AbsRel=0.062, RMSE=2.575. On NYUv2, the fine-tuned model achieves d1=0.904, AbsRel=0.109, RMSE=0.357 (SILog=9.521).
Note that the original project is no longer actively maintained by Intel, as stated in the official repository. Gigarouter hosts this model as a managed, OpenAI-compatible API, removing infrastructure concerns for developers.
best for
- ·Zero-shot monocular depth estimation from a single image
- ·Fine-tuning for domain-specific depth prediction (e.g., KITTI, NYUv2)
- ·Robust depth prediction with global context via Vision Transformer
FAQ
It is best for zero-shot monocular depth estimation from a single image, and can be fine-tuned for specific datasets like KITTI or NYUv2.
The model is licensed under MIT, according to the official GitHub repository.
The model expects a single RGB image, typically resized so the longer side is 384 pixels, processed via the DPTImageProcessor.
Use the gigarouter OpenAI-compatible endpoint with your API key to send an image URL or base64-encoded image and receive depth map output.
No, Intel has ceased development and the project is no longer actively maintained.
We're benchmarking and onboarding DPT-Hybrid MiDaS as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.