DPT Large
Intel/dpt-large
published Mar 2022 · updated Feb 2024
DPT Large is a monocular depth estimation model that uses a Vision Transformer backbone to predict a depth map from a single RGB image.
specs
| Task | Monocular Depth Estimation |
| Architecture | Dense Prediction Transformer (Vision Transformer backbone with convolutional decoder) |
| License | Apache 2.0 |
about this model
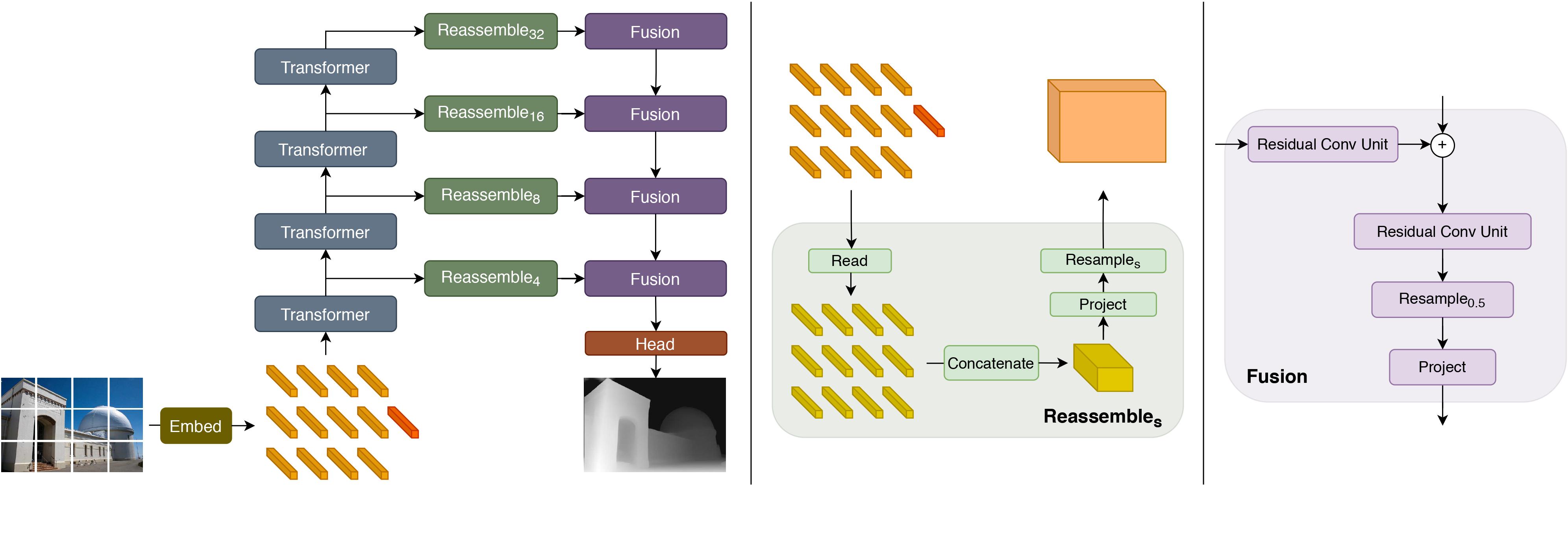
Key strengths
The transformer backbone processes representations at a constant high resolution and maintains a global receptive field at every stage, enabling finer-grained and more globally coherent depth predictions compared to fully-convolutional networks. Trained on the MIX 6 dataset (1.4 million images), the model achieves up to 28% relative improvement over state-of-the-art fully-convolutional networks for monocular depth estimation (per the paper). For semantic segmentation on ADE20K, DPT set a new state of the art with 49.02% mIoU.
Zero-shot cross-dataset benchmark results
The table below compares DPT-Large with prior methods on zero-shot transfer across six datasets. Lower is better for all metrics.
| Model | Training set | DIW WHDR | ETH3D AbsRel | Sintel AbsRel | KITTI δ>1.25 | NYU δ>1.25 | TUM δ>1.25 |
|---|---|---|---|---|---|---|---|
| DPT-Large | MIX 6 | 10.82 | 0.089 | 0.270 | 8.46 | 8.32 | 9.97 |
| DPT-Hybrid | MIX 6 | 11.06 | 0.093 | 0.274 | 11.56 | 8.69 | 10.89 |
| MiDaS | MIX 6 | 12.95 | 0.116 | 0.329 | 16.08 | 8. |
best for
- ·Zero-shot depth estimation on any RGB image
- ·Fine-tuning for domain-specific depth tasks (e.g., autonomous driving, indoor scenes)
- ·Integration into 3D reconstruction pipelines
FAQ
DPT Large is designed for zero-shot monocular depth estimation — predicting depth from a single image without fine-tuning.
DPT Large uses a Vision Transformer backbone instead of a convolutional one, achieving up to 28% relative improvement over MiDaS on depth estimation benchmarks.
The model expects a single RGB image. The image is resized so that the longer side is 384 pixels and then a 384x384 crop is used during training; at inference, the DPTImageProcessor handles preprocessing.
The model is released under the Apache 2.0 license according to the Hugging Face model card.
You can call the model through gigarouter's OpenAI-compatible endpoint using your API key, sending an image and receiving a depth map in response.
We're benchmarking and onboarding DPT Large as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.