YOLOv8 Anime Face Detector
Fuyucchi/yolov8_animeface
published Oct 2024 · updated Oct 2024
YOLOv8 Anime Face Detector is a detection model that identifies and localizes anime character faces in images, based on the YOLOv8x architecture and trained on 10,000 manually annotated anime illustrations from safebooru.
specs
| Task | Object Detection (anime face detection) |
| Architecture | YOLOv8x (variant trained at 1280x1280 input) |
| Parameters | 68.2 million |
| License | AGPL-3.0 (Ultralytics YOLOv8 base) |
about this model
Architecture and Training
The model uses the YOLOv8x6 variant (a larger, non-standard input size variant of YOLOv8x) and was trained for 300 epochs at 1280x1280 pixel resolution. Training took approximately 110 hours on an RTX A4000 GPU. The dataset was split 70% training, 20% validation, and 10% testing.
Performance
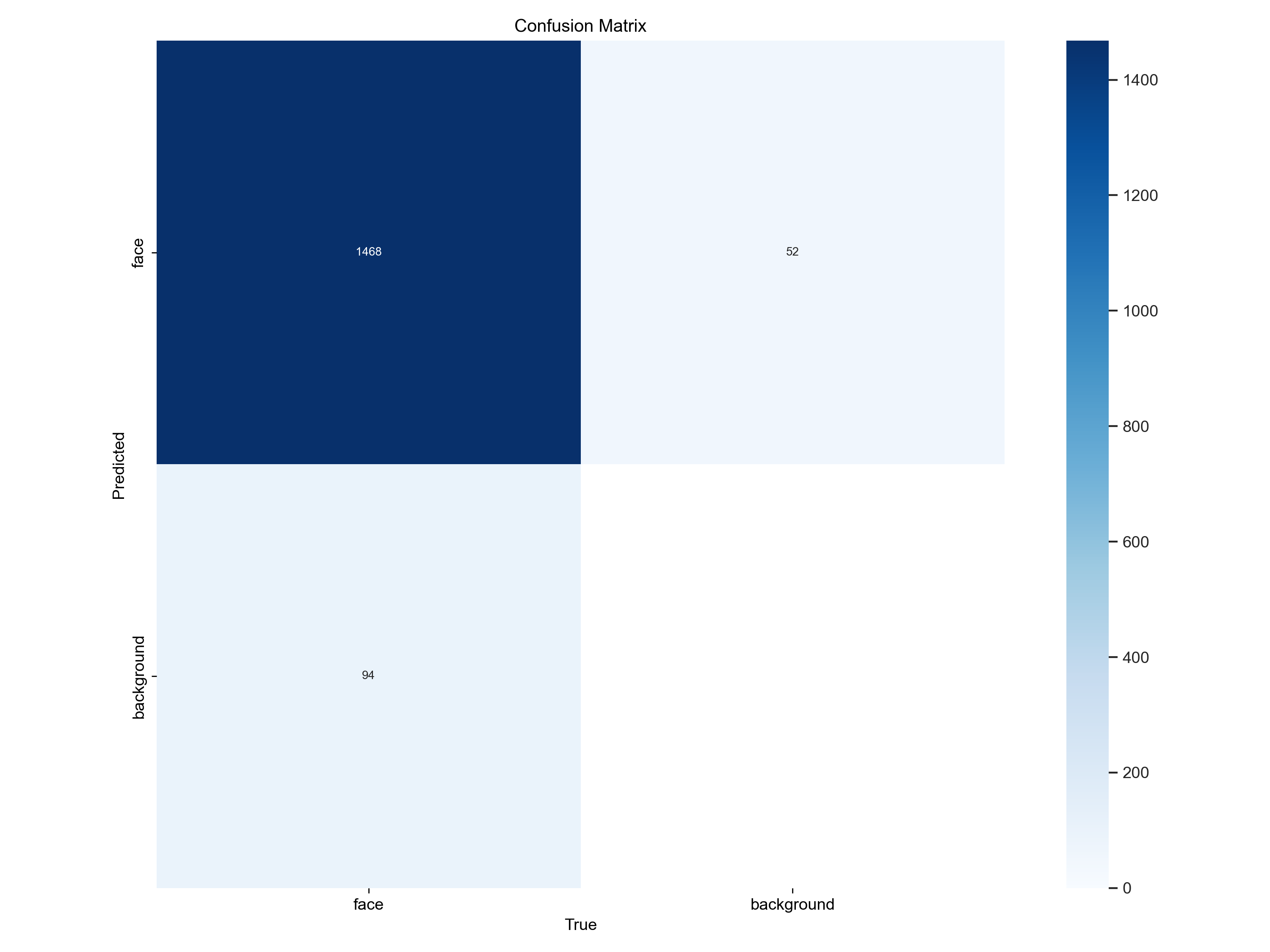
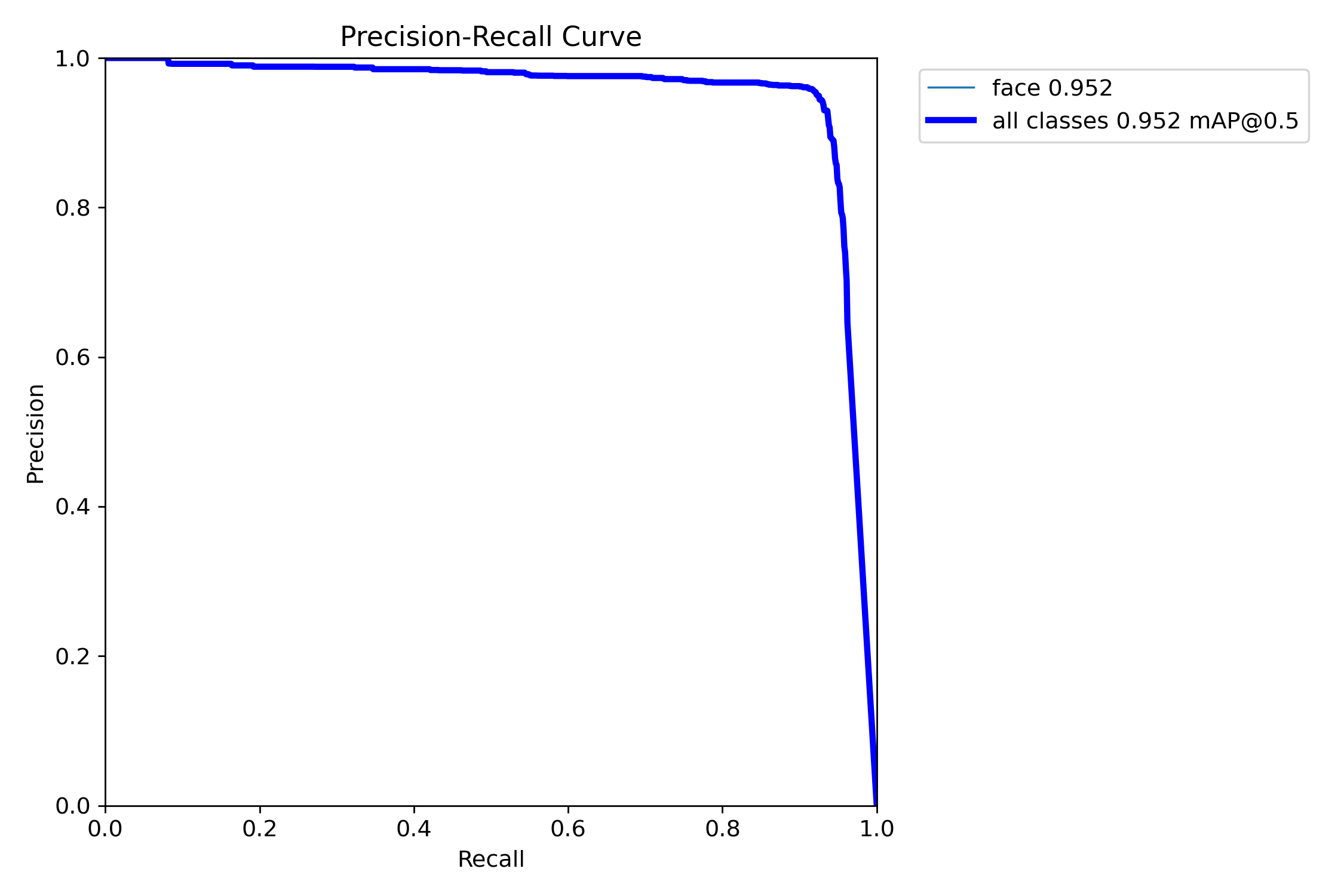
On the test set (1,002 images with 1,562 instances), the model achieves:
| Metric | Value |
|---|---|
| Box Precision (P) | 0.957 |
| Recall (R) | 0.924 |
| mAP50 | 0.955 |
| mAP50-95 | 0.534 |
Inference speed is 81.9ms per image at 1280x1280 resolution, with 1.3ms preprocessing and 0.8ms postprocessing.
Comparison with YOLOv5-based Model
Compared to the earlier YOLOv5-based anime face detector (zymk9/yolov5_anime, now unavailable), this model shows significant improvements on the same test set:
| Metric | YOLOv8-animeface | YOLOv5-anime |
|---|---|---|
| Precision | 0.956 | 0.778 |
| Recall | 0.919 | 0.685 |
| mAP50 | 0.953 | 0.633 |
| mAP50-95 | 0.532 | 0.232 |
The YOLOv8-based model demonstrates higher precision and recall with fewer false positives, though the YOLOv5 model showed higher confidence in its predictions.
Visual Results
Comparison of manual annotations (left) and model predictions (right):


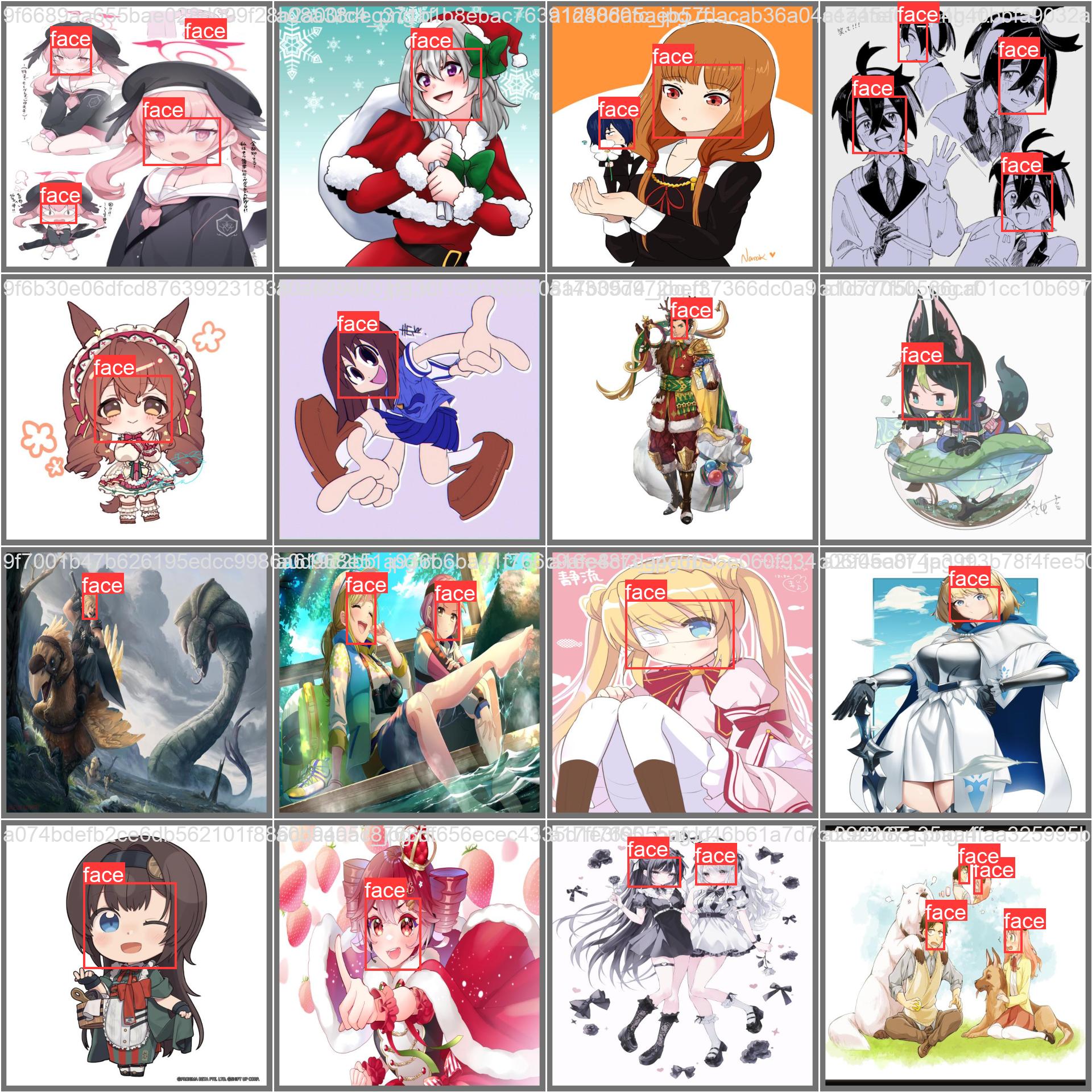
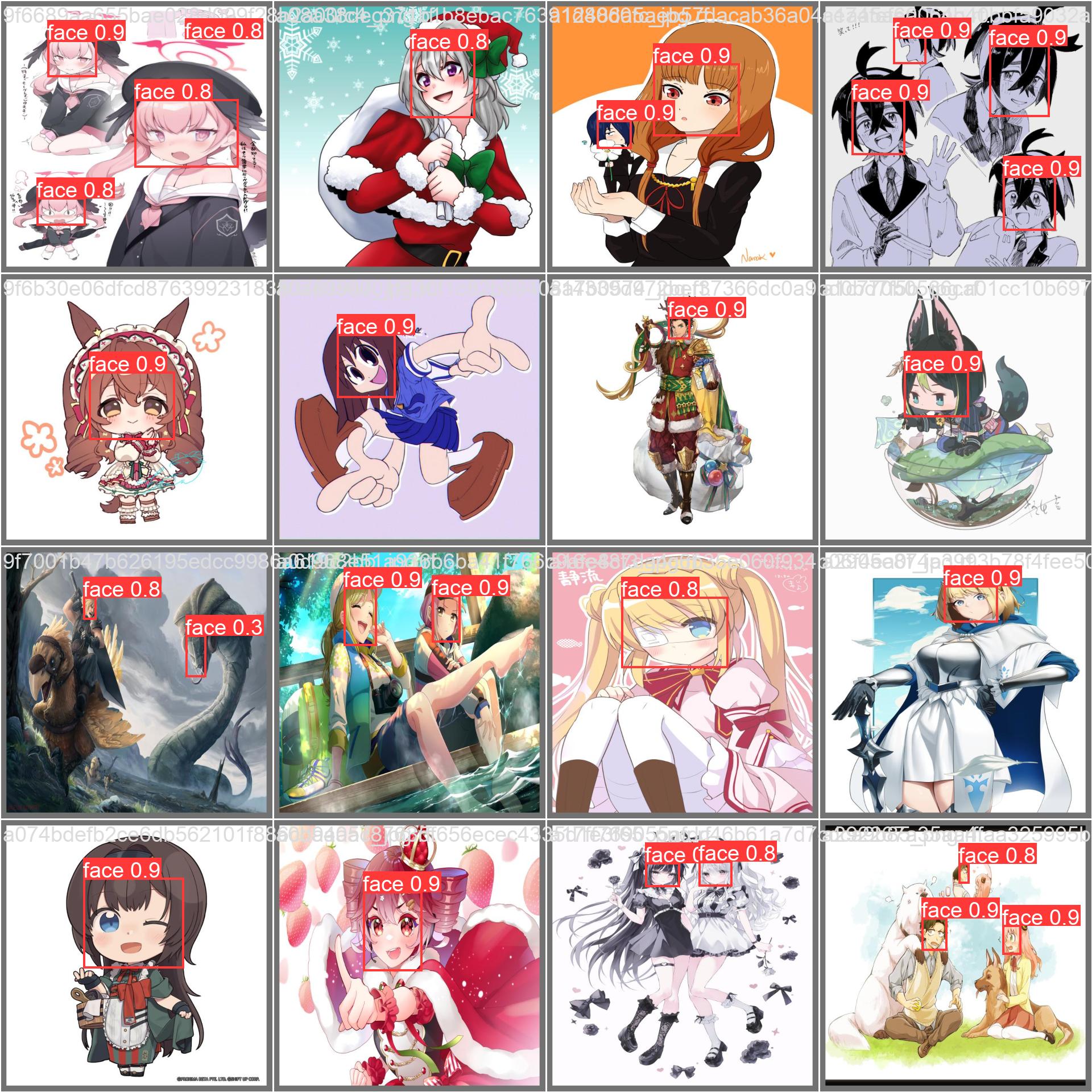
The base YOLOv8x model (from which this is fine-tuned) has 68.2M parameters and 257.8B FLOPs, achieving 53.9 mAP50-95 on COCO at 640px input. This fine-tuned model trades some general object detection capability for specialized anime face detection performance at higher resolution.
best for
- ·Detecting anime faces in illustrations from safebooru and similar sources
- ·Automatic face cropping or tagging in anime image datasets
- ·Face detection in screenshots from anime games or visual novels
FAQ
On the test set it achieves 0.955 mAP50 and 0.534 mAP50-95 at 1280x1280 input.
It significantly outperforms YOLOv5-anime on the same dataset: mAP50 0.953 vs 0.633, mAP50-95 0.532 vs 0.232.
It expects images resized to 1280x1280 pixels, in standard RGB format.
It outputs bounding boxes with confidence scores for each detected anime face.
Use the gigarouter OpenAI-compatible endpoint with your API key; refer to the gigarouter documentation for the specific endpoint and request schema.
We're benchmarking and onboarding YOLOv8 Anime Face Detector as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.