YOLO11 Document Layout
Armaggheddon/yolo11-document-layout
published Sep 2025 · updated Mar 2026
YOLO11 Document Layout is a detection model that identifies and classifies 11 document layout elements (text, tables, figures, titles, etc.) using the YOLOv11 architecture fine-tuned on the DocLayNet dataset.
specs
| Task | Document Layout Analysis (Object Detection) |
| Architecture | YOLOv11 (Nano, Small, Medium variants) |
| Parameters | Nano: 2.6M, Small: 9.4M, Medium: 20.1M |
| Training Dataset | DocLayNet (11 classes) |
| License | MIT |
about this model
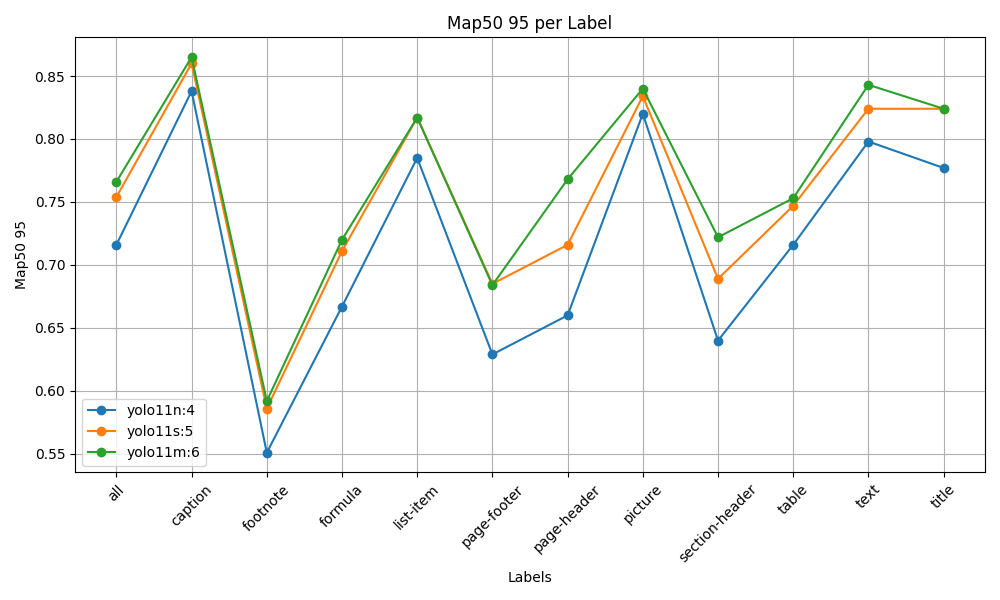
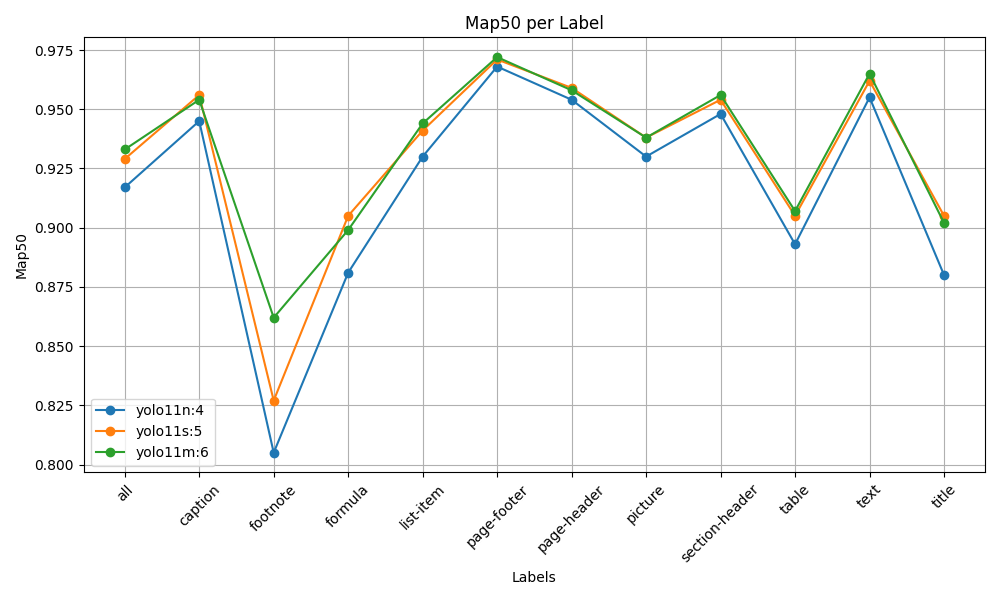
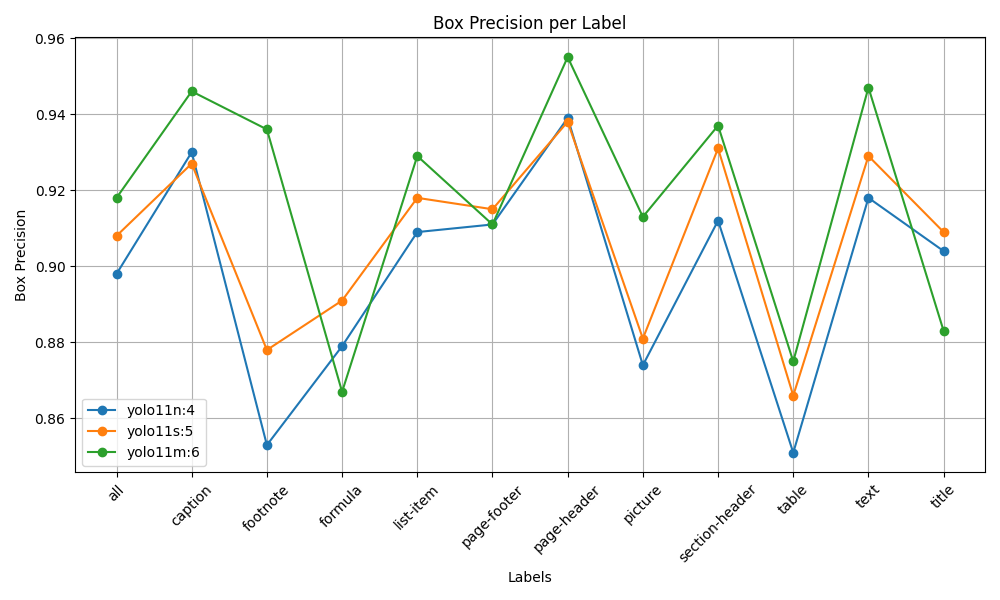
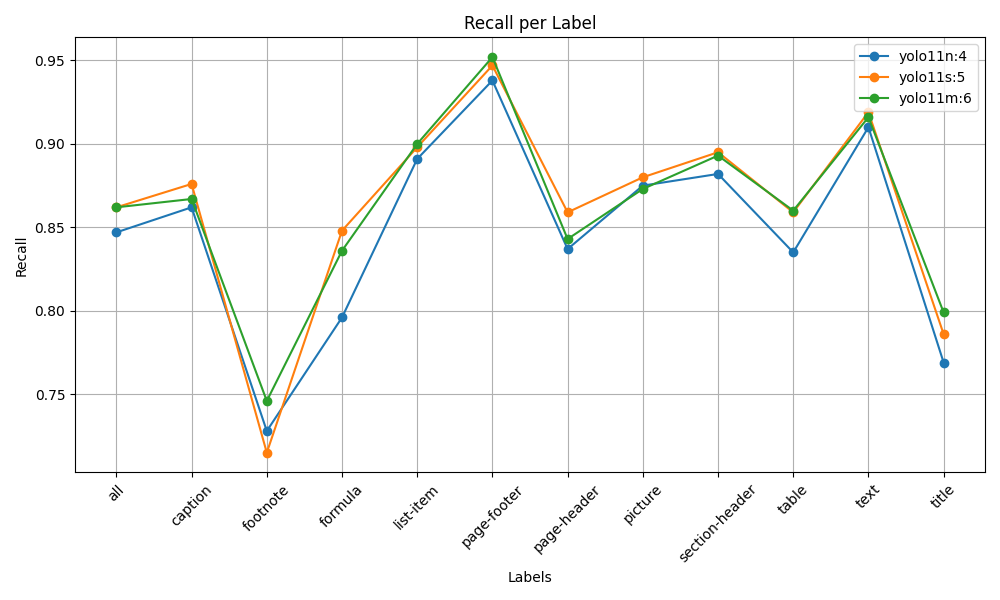
Performance Benchmarks
| Variant | Parameters | mAP50-95 | mAP50 |
|---|---|---|---|
| Nano | 2.6M | 0.732 | 0.841 |
| Small | 9.4M | 0.771 | 0.871 |
| Medium | 20.1M | 0.796 | 0.887 |
best for
- ·Automated document digitization and OCR preprocessing
- ·Intelligent document parsing for information extraction
- ·Layout-aware document classification and indexing
FAQ
Three sizes: nano (2.6M params, fastest), small (9.4M), medium (20.1M, highest accuracy). The nano is recommended for production due to best speed-accuracy balance.
MIT license.
Use the gigarouter OpenAI-compatible endpoint with your API key. Refer to gigarouter documentation for endpoint format.
11 classes: Text, Title, Section-header, Table, Picture, Caption, List-item, Formula, Page-header, Page-footer, Footnote.
Images at 1280x1280 resolution, preferably PNG or JPEG. The model outputs bounding boxes with class labels.
We're benchmarking and onboarding YOLO11 Document Layout as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.