Nomic Embed V2 MoE
nomic-ai/nomic-embed-text-v2-moe
published Feb 2025 · updated Apr 2025
Nomic Embed V2 MoE is a multilingual mixture-of-experts text embedding model optimized for retrieval, supporting flexible embedding dimensions via Matryoshka representation learning.
specs
| Task | Text Embedding & Retrieval |
| Architecture | Mixture of Experts (MoE) with 8 experts, top-2 routing |
| Parameters | 475M total, 305M active |
| Embedding Dimension | 768 (flexible down to 256 via Matryoshka) |
| Max Sequence Length | 512 tokens |
about this model
nomic-embed-text-v2-moe is a multilingual Mixture of Experts (MoE) text embedding model that produces high-quality vector representations for retrieval and search tasks. It is the first general-purpose MoE text embedding model, designed to deliver state-of-the-art multilingual performance while maintaining inference efficiency through sparse expert routing.
Architecture and Efficiency
The model uses a MoE architecture with 8 experts and top-2 routing, totaling 475M parameters but activating only 305M during inference. This design reduces inference latency and memory usage compared to dense models of equivalent capability, addressing deployment challenges in retrieval-augmented generation (RAG) applications. The model supports flexible embedding dimensions from 768 down to 256 through Matryoshka Representation Learning, enabling up to 3x reductions in storage cost with minimal performance degradation. Maximum sequence length is 512 tokens.
Multilingual Performance
Trained on over 1.6 billion high-quality pairs across approximately 100 languages, the model achieves state-of-the-art multilingual results against models in the ~300M parameter class and remains competitive with models twice its size. Key benchmark results include:
| Model | Params (M) | Emb Dim | BEIR | MIRACL |
|---|---|---|---|---|
| Nomic Embed v2 | 305 | 768 | 52.86 | 65.80 |
| mE5 Base | 278 | 768 | 48.88 | 62.30 |
| mGTE Base | 305 | 768 | 51.10 | 63.40 |
| Arctic Embed v2 Base | 305 | 768 | 55.40 | 59.90 |
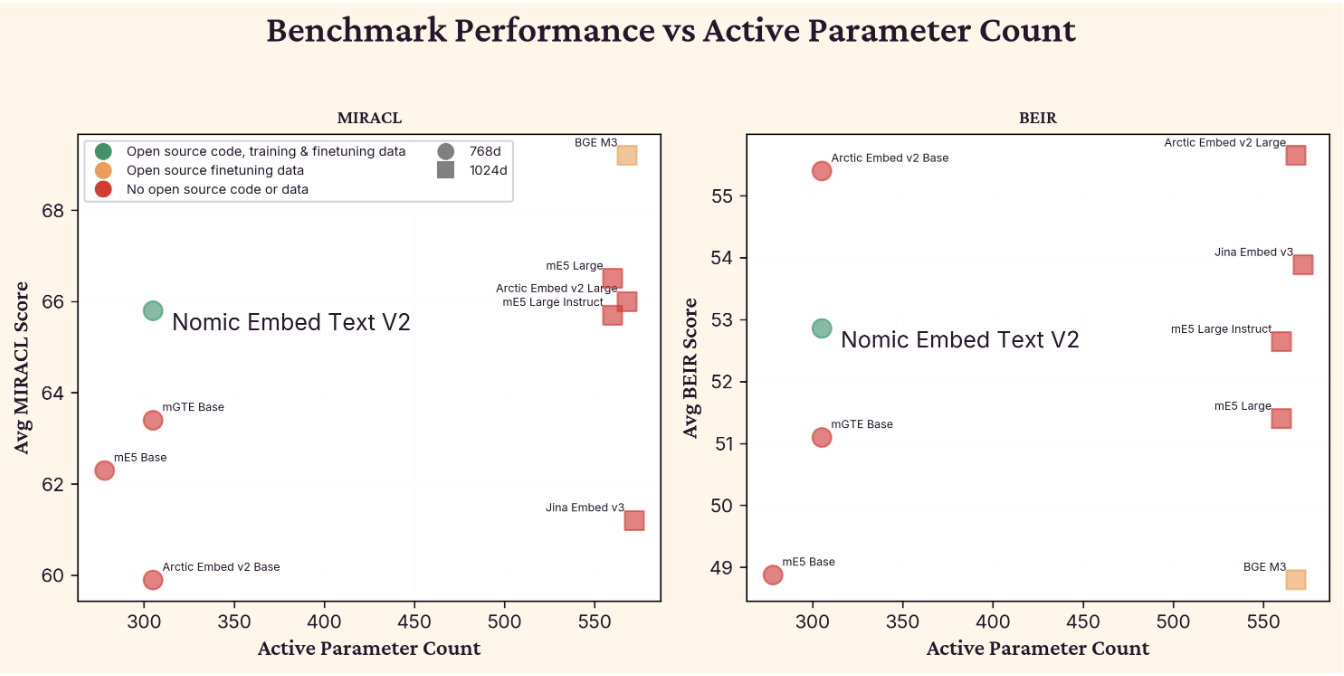
For larger models in the 560-568M parameter range, nomic-embed-text-v2-moe (305M active) achieves a BEIR score of 52.86 and MIRACL score of 65.80, competitive with models twice its size.
Matryoshka Embeddings and Flexibility
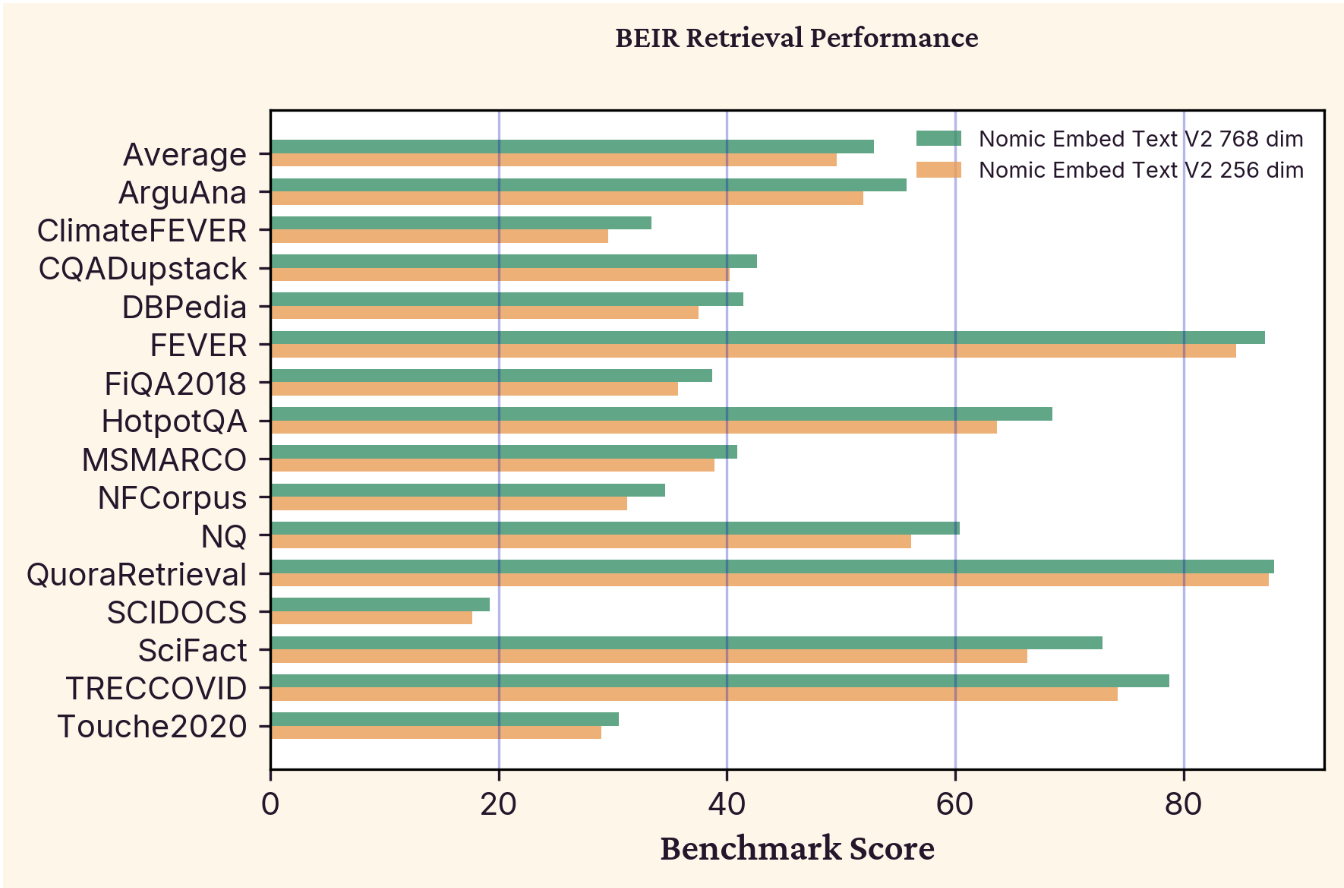
The model supports Matryoshka Representation Learning, enabling flexible embedding dimensions from 768 down to 256. This allows developers to trade off between embedding size and accuracy: truncating to 256 dimensions can reduce storage costs by 3x with minimal performance degradation, as shown in the figure below.
Multilingual Capabilities
Trained on over 1.6 billion high-quality pairs across approximately 100 languages, the model supports dozens of languages for retrieval tasks. Performance on BEIR and MIRACL benchmarks is shown below relative to other open-weight embedding models.
Training and Data
The model was trained on over 1.6 billion high-quality pairs across multiple languages using consistency filtering, with both weakly-supervised contrastive pretraining and supervised finetuning. The training pipeline and all model weights are fully open-source. For further details, see the blog post and technical report.
best for
- ·Multilingual semantic search and retrieval
- ·Document indexing with reduced storage using Matryoshka embeddings
- ·Retrieval-augmented generation (RAG) pipelines
FAQ
Total parameters are 475M, but only 305M are active per forward pass due to MoE sparsity (top-2 expert routing), enabling faster inference.
The model outputs 768-dimensional embeddings by default, but can be truncated to any dimension from 768 down to 256 with minimal performance loss (Matryoshka representation learning).
Use "search_query: " before queries and "search_document: " before documents. This task instruction is mandatory.
Use the OpenAI-compatible endpoint with your gigarouter API key, sending the input with the required prefix.
It supports approximately 100 languages, trained on over 1.6 billion multilingual pairs.
We're benchmarking and onboarding Nomic Embed V2 MoE as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.