Nomic Embed Text V1.5
nomic-ai/nomic-embed-text-v1.5
published Feb 2024 · updated Apr 2026
Nomic Embed Text V1.5 is a text embedding model that uses Matryoshka Representation Learning to allow flexible dimensionality reduction while maintaining high performance.
specs
| Task | Text embedding |
| Architecture | BERT-based with Matryoshka Representation Learning |
| Context Length | 8192 tokens |
| Dimensions | 768 (native), adjustable from 64 to 768 |
| MTEB Score | 62.28 |
| License | Apache 2.0 |
about this model
nomic-embed-text-v1.5 is a text embedding model that produces fixed-size vector representations of text, supporting a maximum sequence length of 8192 tokens and utilizing Matryoshka Representation Learning to allow developers to trade off embedding size for a negligible reduction in performance.
The model requires a task instruction prefix to indicate the embedding use case: search_document for indexing documents, search_query for user queries, clustering for grouping texts, and classification for feature extraction. It natively supports scaling sequence length past 2048 tokens.
Key Strengths
- Matryoshka Representation Learning enables flexible dimensionality reduction from 768 down to 64 dimensions with minimal performance loss.
- Maximum sequence length of 8192 tokens.
- Fully reproducible, open-source, open-weights, and open-data model (Apache 2.0 license).
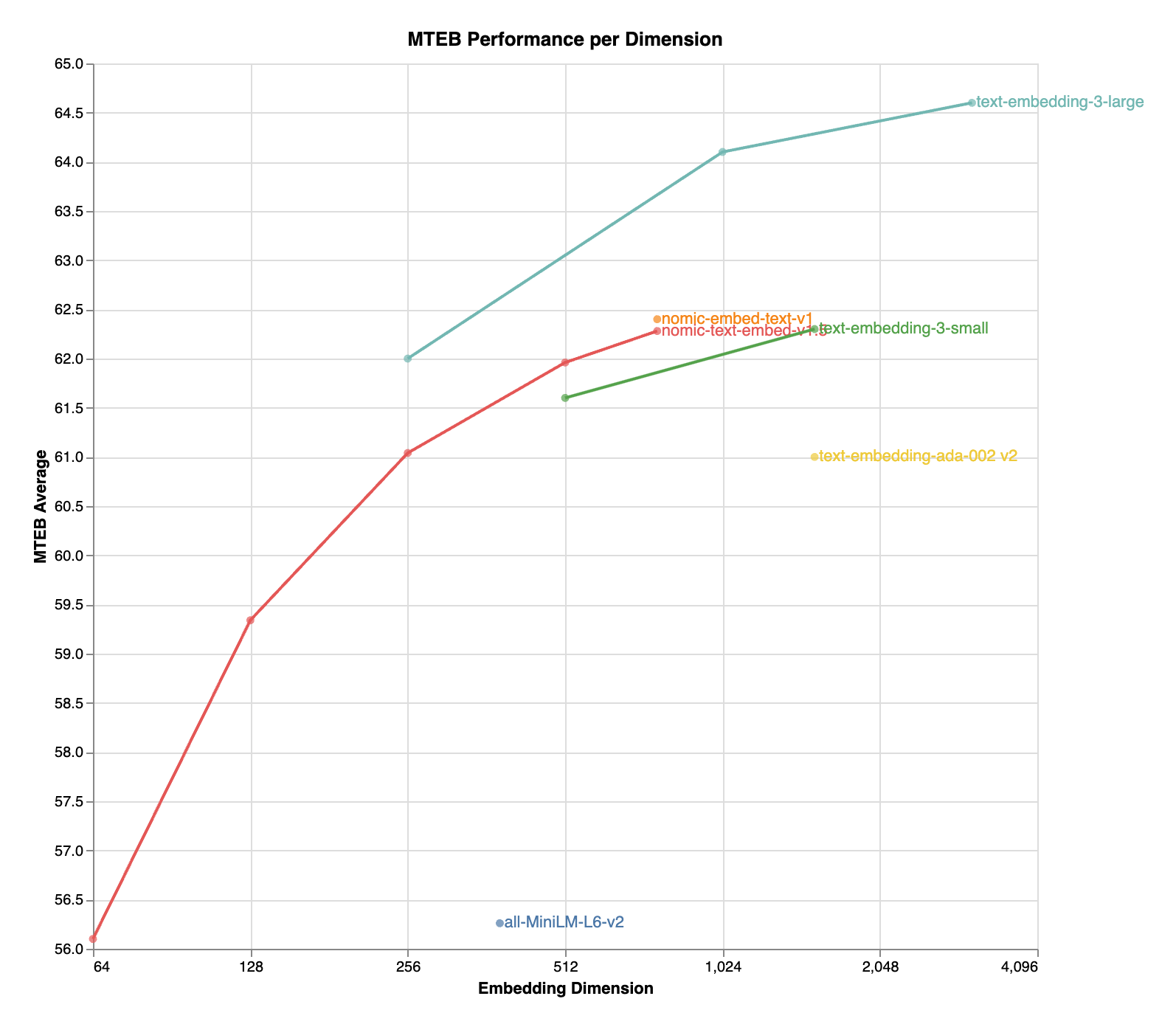
MTEB Performance by Dimension
| Model | SeqLen | Dimension | MTEB |
|---|---|---|---|
| nomic-embed-text-v1 | 8192 | 768 | 62.39 |
| nomic-embed-text-v1.5 | 8192 | 768 | 62.28 |
| nomic-embed-text-v1.5 | 8192 | 512 | 61.96 |
| nomic-embed-text-v1.5 | 8192 | 256 | 61.04 |
| nomic-embed-text-v1.5 | 8192 | 128 | 59.34 |
| nomic-embed-text-v1.5 | 8192 | 64 | 56.10 |
The model is trained using a multi-stage pipeline starting from a long-context BERT model. The first unsupervised contrastive stage trains on weakly related text pairs from sources such as StackExchange, Quora, Amazon reviews, and news article summarizations. The second finetuning stage leverages higher quality labeled datasets including search queries and answers from web searches, with emphasis on data curation and hard-example mining.
Training data and code are released in full under an Apache 2.0 license. For further details, see the technical report and the contrastors repository.
best for
- ·Building a retrieval-augmented generation (RAG) system with adjustable embedding size
- ·Clustering large text datasets with dimensionality reduction
- ·Multi-task classification and search using task-specific prefixes
FAQ
The model requires a task instruction prefix such as search_document, search_query, clustering, or classification to indicate the intended use.
Yes, you can adjust the dimension from 768 down to 64 using Matryoshka layer normalization and slicing with minimal performance loss.
The model natively supports up to 8192 tokens, and can be extended further with dynamic RoPE scaling.
It is released under the Apache 2.0 license, allowing free use, modification, and distribution.
Use the OpenAI-compatible endpoint with your gigarouter API key, specifying the model name nomic-ai/nomic-embed-text-v1.5 and the appropriate task prefix in the input.
We're benchmarking and onboarding Nomic Embed Text V1.5 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.