WavLM Large
microsoft/wavlm-large
published Mar 2022 · updated Feb 2022
WavLM Large is a speech embedding model that generates deep speech representations for a variety of downstream tasks.
specs
| Task | Speech Embedding |
| Architecture | HuBERT-based Transformer with gated relative position bias and utterance mixing |
| Pre-training Data | 94,000 hours (Libri-Light 60k, GigaSpeech 10k, VoxPopuli 24k) |
| License | CC BY-SA 3.0 |
about this model
WavLM-Large is a self-supervised speech embedding model that produces dense vector representations from 16 kHz audio input. It is designed to capture both spoken content and speaker identity, making it suitable for a wide range of downstream tasks such as speaker verification, speech recognition, and speech separation.
Pre-training Data
The model was pre-trained on 94,000 hours of English speech, composed of 60,000 hours from Libri-Light, 10,000 hours from GigaSpeech, and 24,000 hours from VoxPopuli. This large and diverse corpus enables robust generalization across speaking styles, recording conditions, and speaker characteristics.
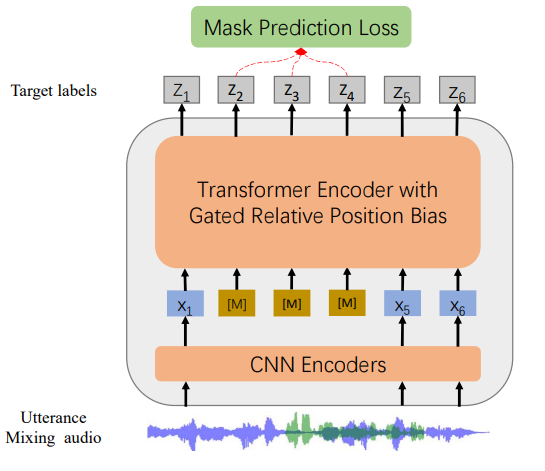
Architecture Highlights
Built on the HuBERT framework, WavLM incorporates a gated relative position bias in its Transformer structure to improve recognition tasks. An utterance mixing training strategy is used to enhance speaker discrimination by creating overlapping utterances during pre-training. The large variant contains approximately 300 million parameters.
Benchmark Performance
WavLM-Large achieves state-of-the-art results on the SUPERB benchmark and strong results on specialized tasks. Key results from the original repository include:
Speaker Verification on VoxCeleb1 (EER, lower is better)
| Dataset | EER (%) |
|---|---|
| Vox1-O | 0.330 |
| Vox1-E | 0.477 |
| Vox1-H | 0.984 |
Speech Separation on LibriCSS (WER, lower is better)
- Clean (0S): 4.3%
- Clean (0L): 4.2%
- Overlap 10% (OV10): 5.0%
- Overlap 20% (OV20): 6.3%
- Overlap 30% (OV30): 8.2%
- Overlap 40% (OV40): 8.8%
These results outperform prior systems including HuBERT large, Wav2Vec2.0 XLSR, and Conformer.
License
The model is released under the Creative Commons Attribution-ShareAlike 3.0 Unported (CC BY-SA 3.0) license.
best for
- ·Fine-tuning for automatic speech recognition (ASR)
- ·Fine-tuning for speaker verification and diarization
- ·Extracting speech features for audio classification
FAQ
The model expects mono audio sampled at 16 kHz. Input should be provided as raw audio waveforms.
Yes, you can extract frame-level speech representations from the pre-trained model and use them as embeddings for downstream tasks.
The model is licensed under Creative Commons Attribution-ShareAlike 3.0 Unported (CC BY-SA 3.0).
On VoxCeleb1, it achieves 0.33% equal error rate (EER) on the Vox1-O test set when fine-tuned.
Use the OpenAI-compatible endpoint with your gigarouter API key. Send a request with the audio file or base64-encoded audio.
We're benchmarking and onboarding WavLM Large as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.