WavLM Base Plus
microsoft/wavlm-base-plus
published Mar 2022 · updated Dec 2021
WavLM Base Plus is a self-supervised speech pre-trained model built on the HuBERT framework, designed for full-stack speech processing tasks including recognition, speaker verification, and audio classification.
specs
| Task | Speech Representation Learning (Self-Supervised Pre-training) |
| Architecture | HuBERT with gated relative position bias |
| Training Data | 94k hours: Libri-Light (60k), GigaSpeech (10k), VoxPopuli (24k) |
| Input | 16kHz mono waveform |
| License | MIT |
about this model
Microsoft WavLM-Base-Plus is a self-supervised speech embedding model that generates general-purpose representations from raw audio, optimized for 16 kHz sampled speech. Built on the HuBERT framework, it incorporates gated relative position bias in the Transformer layers to improve sequence modeling and an utterance mixing training strategy that overlays unsupervised speech segments to enhance speaker discrimination.
The model was pre-trained on 94,000 hours of English audio drawn from three large-scale corpora: Libri-Light (60,000 hours of audiobooks), GigaSpeech (10,000 hours of multi-domain transcribed speech), and VoxPopuli (24,000 hours of unlabeled speech from European Parliament proceedings). This diverse training setup enables the model to learn robust, multi-faceted representations that capture spoken content, speaker identity, and paralinguistic cues.
The WavLM architecture achieved state-of-the-art results on the SUPERB benchmark (with the Large variant), and the base-plus variant is well-suited for tasks such as speaker recognition, audio classification, and speech separation when fine-tuned or used as a feature extractor. As a hosted API through gigarouter, the model accepts 16 kHz audio input and returns high-dimensional embeddings without requiring local installation or GPU resources.
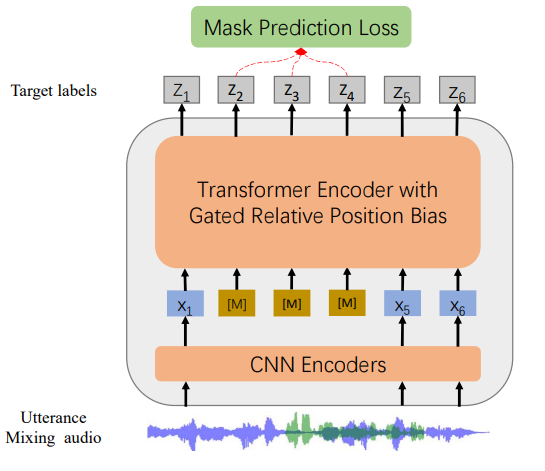
Refer to the WavLM paper and the official repository for further architectural details and evaluation protocols.
best for
- ·Fine-tuning for automatic speech recognition (ASR)
- ·Fine-tuning for speaker verification and diarization
- ·Fine-tuning for audio classification tasks
FAQ
It supports ASR, speaker verification, speaker diarization, and audio classification, as shown in the SUPERB benchmark.
It adds gated relative position bias for better content modeling and an utterance mixing training strategy for improved speaker discrimination.
Yes, on gigarouter via an OpenAI-compatible endpoint using an API key.
The model is released under the MIT License (see UniSpeech license).
We're benchmarking and onboarding WavLM Base Plus as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.