VibeVoice Realtime 0.5B
microsoft/VibeVoice-Realtime-0.5B
published Dec 2025 · updated Dec 2025
VibeVoice Realtime 0.5B is a lightweight real-time text-to-speech model that supports streaming text input and robust long-form speech generation.
specs
| Task | Text-to-Speech (TTS) |
| Architecture | Interleaved windowed design with Qwen2.5-0.5B LLM, σ-VAE acoustic tokenizer, and diffusion decoding head |
| Parameters | 0.5B |
| License | MIT |
| Context Length | 8,192 tokens |
| Generation Length | ~10 minutes |
about this model
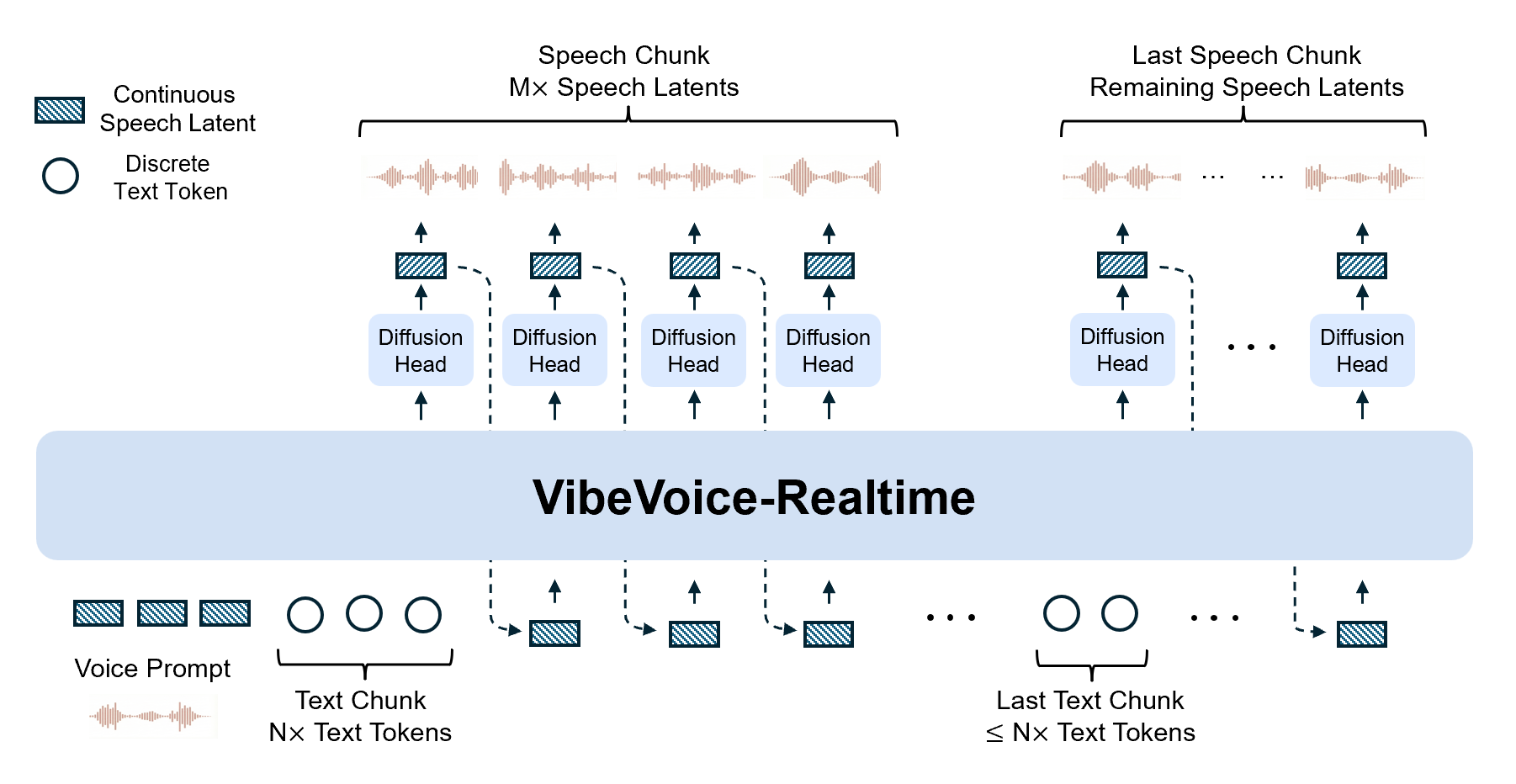
VibeVoice-Realtime-0.5B is a lightweight, real-time text-to-speech (TTS) model that supports streaming text input and robust long-form speech generation, producing initial audible speech in approximately 300 milliseconds (hardware dependent).
The model uses an interleaved, windowed design that incrementally encodes incoming text chunks while continuing diffusion-based acoustic latent generation from prior context. It relies on an efficient acoustic tokenizer operating at an ultra-low frame rate (7.5 Hz) and removes the semantic tokenizer used in multi-speaker variants. The architecture integrates a Qwen2.5-0.5B language model with a σ-VAE-based acoustic tokenizer (3200× downsampling from 24 kHz) and a lightweight diffusion head (4 layers, ~40M parameters) conditioned on LLM hidden states. The context length is 8,192 tokens, supporting speech generation up to approximately 10 minutes.
While primarily built for English, the model exhibits some multilingual capability for German, French, Italian, Japanese, Korean, Dutch, Polish, Portuguese, and Spanish, though other languages may produce unpredictable results.
Benchmark Performance
| Benchmark | Metric | Value |
|---|---|---|
| LibriSpeech test-clean (zero-shot) | WER (%) ↓ | 2.00 |
| LibriSpeech test-clean (zero-shot) | Speaker Similarity ↑ | 0.695 |
| SEED test-en (zero-shot) | WER (%) ↓ | 2.05 |
| SEED test-en (zero-shot) | Speaker Similarity ↑ | 0.633 |
Comparisons on LibriSpeech: WER of 2.00% outperforms VALL-E 2 (2.40%) and MELLE (2.10%), while speaker similarity of 0.695 exceeds all listed models including Voicebox (0.662). On SEED, the model achieves competitive WER and speaker similarity against systems such as SparkTTS and CosyVoice2.
For further details, refer to the technical report, project page, and code repository.
best for
- ·Real-time streaming speech synthesis for live data feeds
- ·Long-form speech generation for audiobooks or podcasts
- ·Enabling conversational AI to speak with low latency from first tokens
FAQ
Approximately 300 ms, hardware dependent.
No, it supports only a single speaker. Use the multi-speaker VibeVoice variants for conversational speech.
Primarily English. It has some multilingual capability for nine additional languages (German, French, Italian, Japanese, Korean, Dutch, Polish, Portuguese, Spanish) but results may be unpredictable.
Generated speech audio. The model also embeds an audible disclaimer and an imperceptible watermark for provenance.
Use the gigarouter OpenAI-compatible endpoint with your API key, specifying the model as microsoft/VibeVoice-Realtime-0.5B.
We're benchmarking and onboarding VibeVoice Realtime 0.5B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.