Qwen3 TTS 12Hz 1.7B CustomVoice
Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice
published Jan 2026 · updated Jan 2026
Qwen3 TTS 12Hz 1.7B CustomVoice is a multilingual text-to-speech model that generates speech with style control over 9 premium timbres via user instructions, supporting streaming and low-latency synthesis.
specs
| Task | Text-to-Speech (TTS) |
| Architecture | Discrete multi-codebook language model with dual-track hybrid streaming |
| Parameters | 1.7B |
| License | Apache 2.0 |
about this model
Qwen3-TTS-12Hz-1.7B-CustomVoice is a text-to-speech model that generates natural speech with instruction-driven control over timbre, emotion, and prosody across 10 languages, using a discrete multi-codebook LM architecture for end-to-end speech modeling. Built on the Qwen3-TTS-Tokenizer-12Hz (12.5 Hz, 16-layer multi-codebook), it achieves extreme bitrate reduction and ultra-low-latency streaming with a 97 ms first-packet emission. The model supports Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian, and offers nine premium built-in timbres covering varied gender, age, and dialectal profiles.
Key capabilities
- Instruction-controlled voice: Natural language instructions adjust tone, speaking rate, and emotional expression (e.g., “用特别愤怒的语气说”).
- Streaming generation: Dual-Track hybrid architecture outputs audio immediately after a single character is input, with end-to-end latency as low as 97 ms.
- Multilingual & dialectal support: Native-quality output for each built-in speaker’s language; each speaker can also speak any supported language.
Built-in timbres
| Speaker | Description | Native language |
|---|---|---|
| Vivian | Bright, slightly edgy young female voice | Chinese |
| Serena | Warm, gentle young female voice | Chinese |
| Uncle_Fu | Seasoned male voice, low, mellow timbre | Chinese |
| Dylan | Youthful Beijing male voice, clear, natural | Chinese (Beijing Dialect) |
| Eric | Lively Chengdu male voice, slightly husky brightness | Chinese (Sichuan Dialect) |
| Ryan | Dynamic male voice, strong rhythmic drive | English |
| Aiden | Sunny American male voice, clear midrange | English |
| Ono_Anna | Playful Japanese female voice, light nimble timbre | Japanese |
| Sohee | Warm Korean female voice, rich emotion | Korean |
Architecture & training
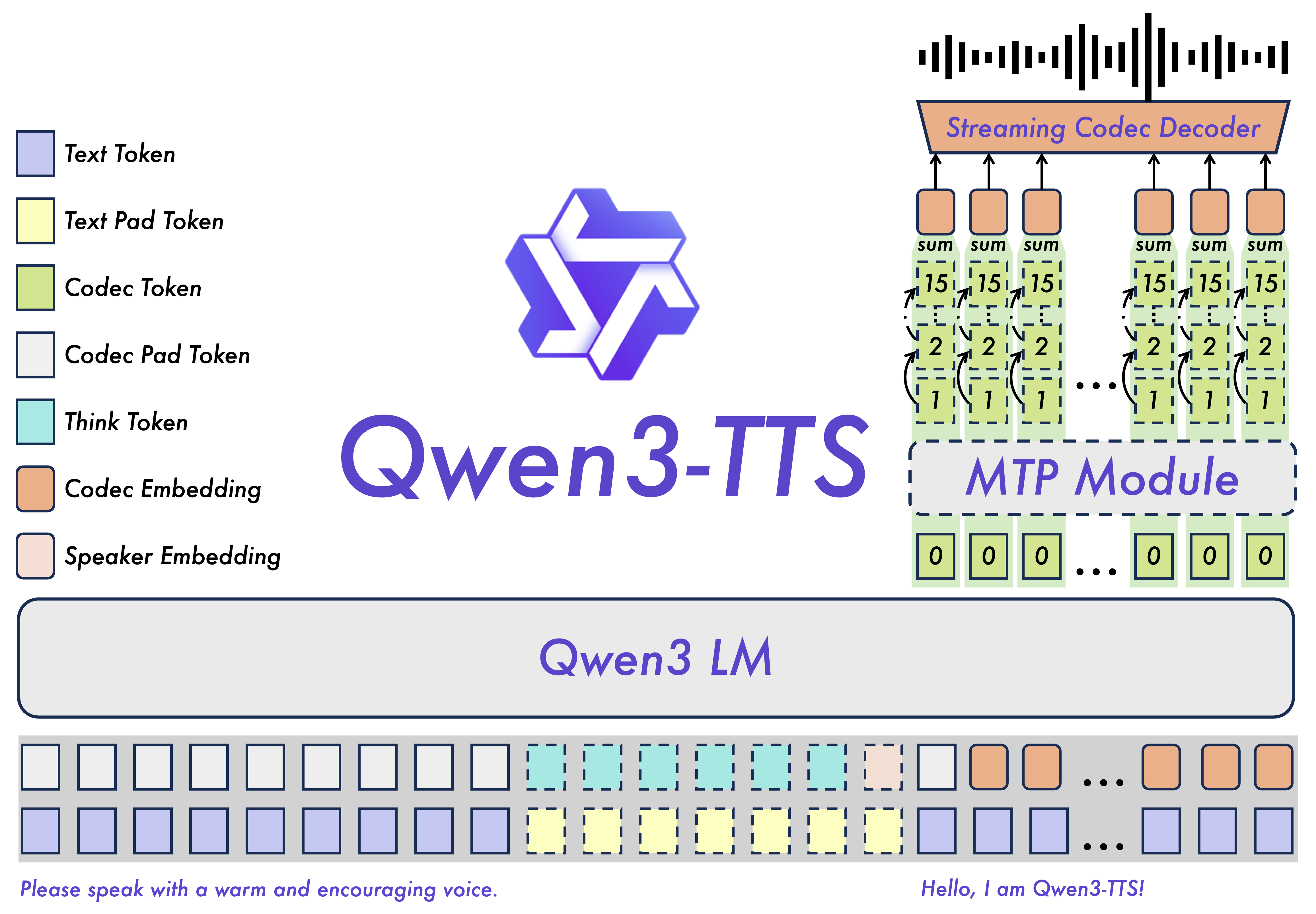
Trained on over 5 million hours of speech data. 1,916,676,352 parameters (~1.7 B), weights in BF16 format. Licensed under Apache 2.0.
Benchmark performance
State-of-the-art results on diverse objective and subjective evaluations, including the TTS multilingual test set, InstructTTSEval, and the long speech test set (see technical report).
best for
- ·Generating speech with specific emotion or tone using natural language instructions
- ·Real-time streaming TTS with sub-100ms first-packet latency
- ·Multilingual voice output across 10 languages with 9 built-in premium timbres
FAQ
It supports Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian.
Pass an optional instruct string when calling generate_custom_voice, e.g. "Very happy." or "用特别愤怒的语气说".
The model can emit the first audio packet in as low as 97ms after a single character input.
Yes, you can call it via the OpenAI-compatible endpoint using an API key on gigarouter.
It is released under the Apache 2.0 license.
We're benchmarking and onboarding Qwen3 TTS 12Hz 1.7B CustomVoice as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.