Jina Embeddings V5 Text Nano
jinaai/jina-embeddings-v5-text-nano
published Jan 2026 · updated Apr 2026
Jina Embeddings V5 Text Nano is an embedding model that generates multilingual text embeddings for retrieval, text-matching, clustering, and classification tasks.
specs
| Task | Text Embedding (retrieval, text-matching, clustering, classification) |
| Architecture | EuroBERT-210M (base) |
| Parameters | 239M |
| Max Sequence Length | 8192 |
| Embedding Dimension | 768 |
about this model
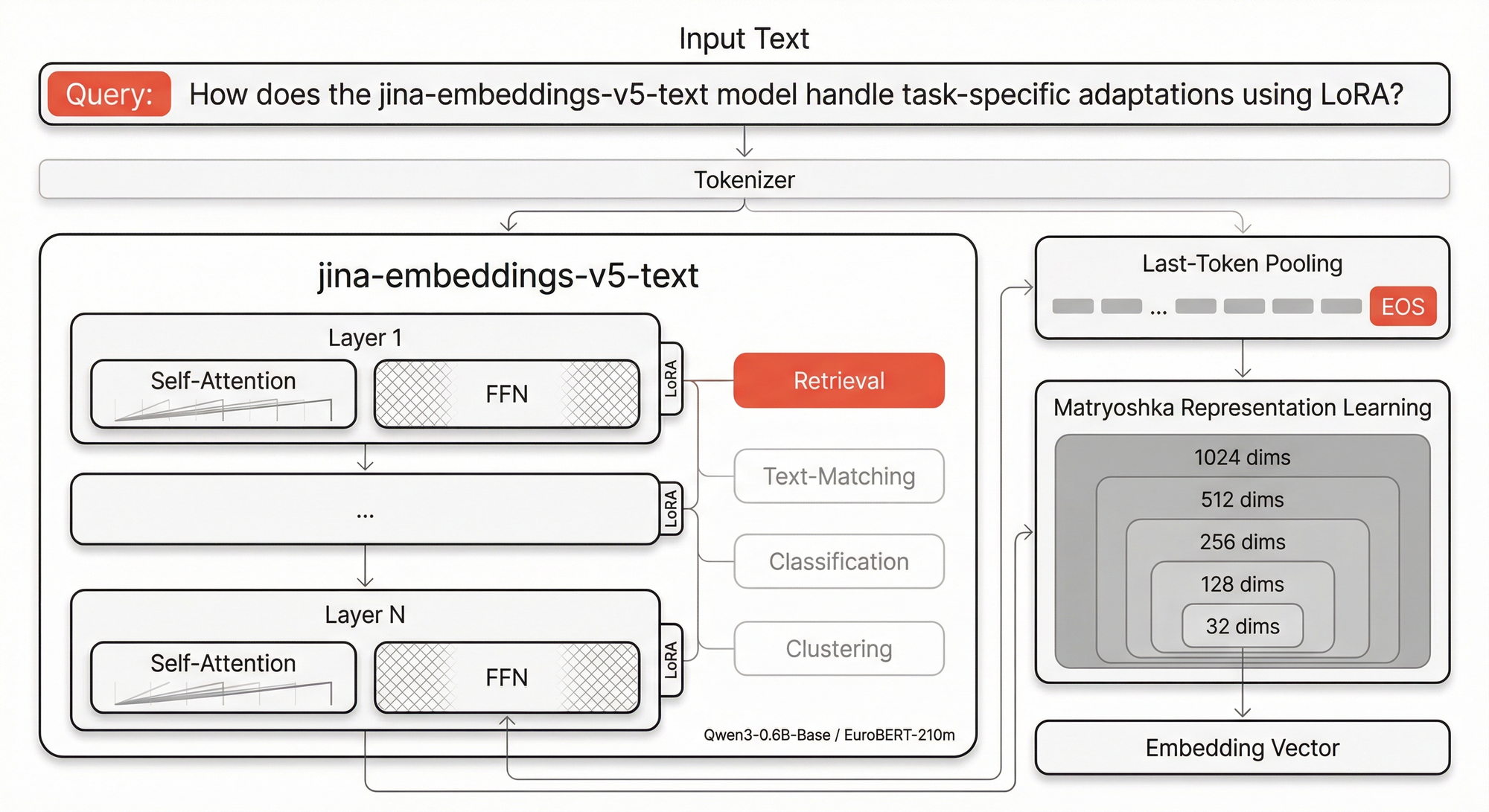
jina-embeddings-v5-text-nano is a text embedding model that generates multilingual dense vector representations for retrieval, text-matching, clustering, and classification tasks, hosted as a managed API on gigarouter.
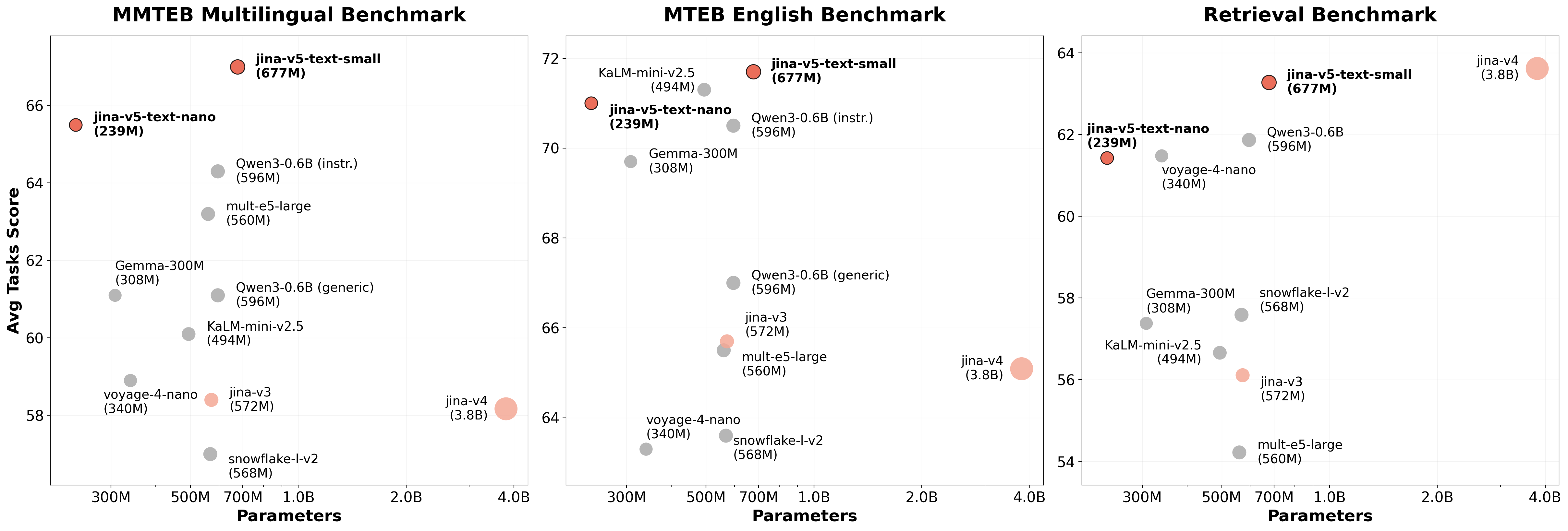
Built on EuroBERT-210M with 239M parameters, it achieves a 71.0 average on MTEB English v2 and 65.5 on MMTEB, matching or exceeding all other sub-500M embedding models including KaLM-mini-v2.5 (494M) and Gemma-300M (308M). The model is trained by combining embedding distillation from Qwen3-Embedding-4B with task-specific contrastive losses, producing compact yet high-performance embeddings.
It supports multilingual text up to 32K tokens and produces embeddings that remain robust under truncation and binary quantization. Embedding dimension is 768 with matryoshka dimensions at 32, 64, 128, 256, 512, and 768. Pooling uses last-token pooling.
Performance highlights
- MTEB English v2: 71.0
- MMTEB: 65.5
- Parameters: 239M – smallest model to match top sub-500M results

For full training details and benchmark methodology, see the technical report.
best for
- ·Multilingual semantic search and retrieval
- ·Text matching across multiple languages
- ·Document clustering for multilingual datasets
- ·Classification of multilingual text (e.g., support tickets, content moderation)
FAQ
The maximum sequence length is 8192 tokens.
The model outputs 768-dimensional embeddings, and supports Matryoshka dimensions of 32, 64, 128, 256, 512, and 768.
With only 239M parameters, it matches or exceeds all other sub-500M embedding models including KaLM-mini-v2.5 (494M) and Gemma-300M (308M) on MTEB/MMTEB.
Send text (or text with task parameter) to the OpenAI-compatible endpoint with your API key. The model supports tasks: retrieval, text-matching, clustering, classification.
The model card does not specify a license.
We're benchmarking and onboarding Jina Embeddings V5 Text Nano as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.