jina embeddings v5 omni small
jinaai/jina-embeddings-v5-omni-small
published Apr 2026 · updated Jun 2026
A popular open embeddings model, with 76.6K downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
jina-embeddings-v5-omni-small is a multimodal embedding model that accepts text, images, video, and audio and produces embeddings in a shared vector space aligned with the text-only jinaai/jina-embeddings-v5-text-small, enabling index-with-text and query-with-any-modality without reindexing.
Architecture
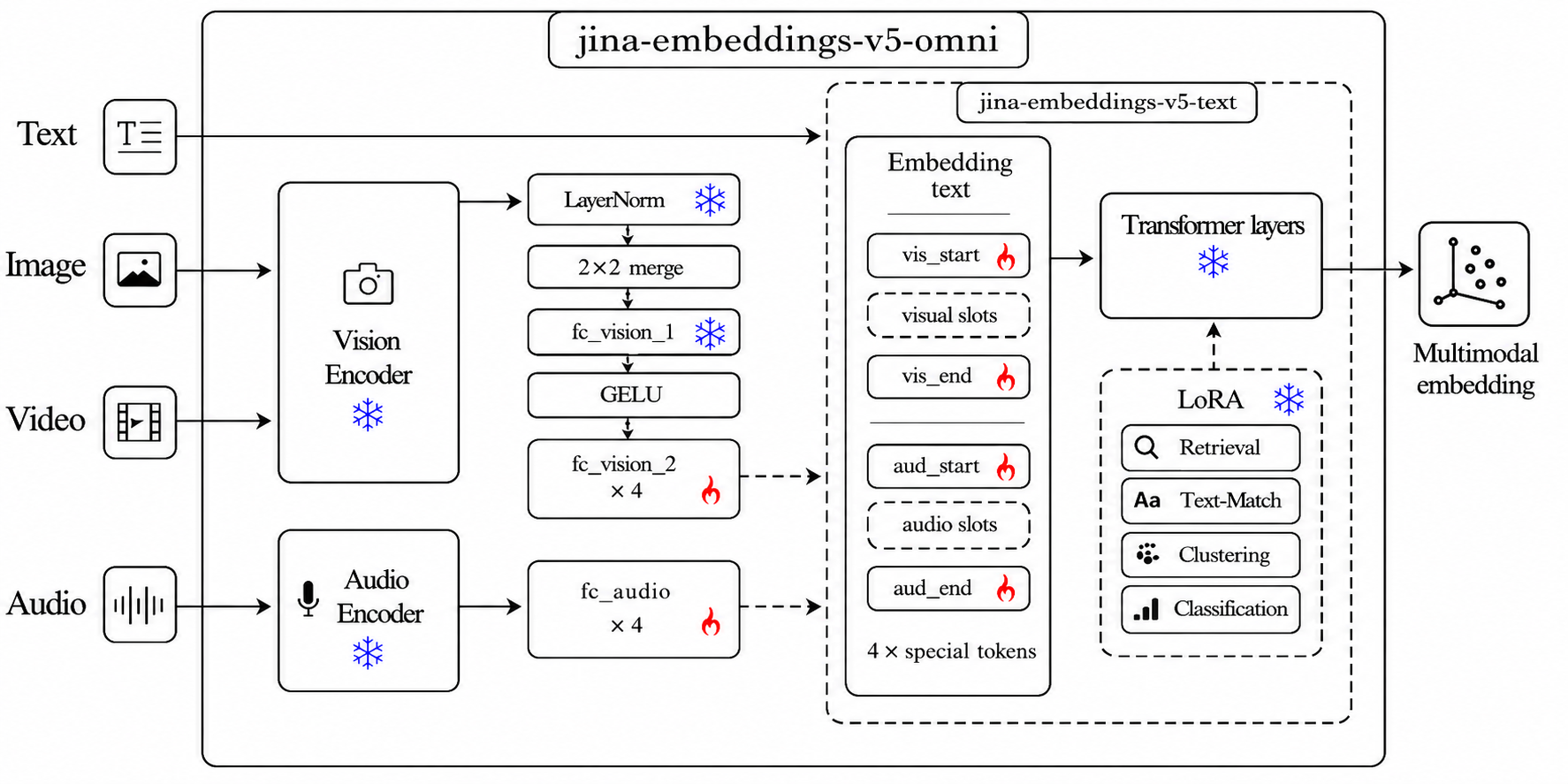
The model uses the GELATO (Geometry-preserving Embeddings via Locked Aligned TOwers) approach. Non-text encoders are adapted to feed a frozen language model that generates embeddings for all input types. Only the connecting components are trained—0.35% of total weights. The text backbone remains bit-identical to the text-only Jina Embeddings v5 model. The vision encoder is a fine-tuned SigLIP2 So400m (from Qwen3.5-2B) and the audio encoder is Whisper-large-v3 (from Qwen2.5-Omni-7B).
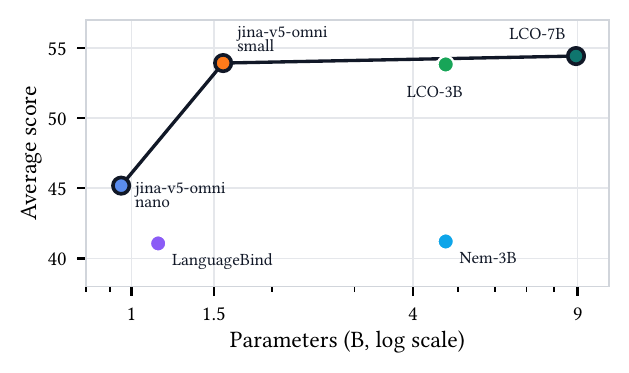
Benchmark Performance
- Best performance on image benchmarks of any model in the ~1 billion parameter range; only models with 3–30 times as many parameters beat it.
- State-of-the-art multilingual visual understanding, outperforming models up to 20× larger.
- Best-in-size-class audio embeddings; only models with double or more parameters perform better on standard benchmarks.
The model supports retrieval, classification, clustering, and text-matching tasks via separate adapters. Embedding dimension is 1024, with Matryoshka dimensions from 32 to 1024. Maximum sequence length is 32768 tokens.
We're benchmarking and onboarding jina embeddings v5 omni small as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.