Jina Embeddings V5 Omni Nano
jinaai/jina-embeddings-v5-omni-nano
published Apr 2026 · updated Jun 2026
Jina Embeddings V5 Omni Nano is a multimodal embedding model that accepts text, images, video, and audio and produces embeddings in a shared vector space.
specs
| Task | Embedding (multimodal) |
| Architecture | GELATO (Geometry-preserving Embeddings via Locked Aligned TOwers) |
| Parameters | ~1.04B |
| License | cc-by-nc-4.0 |
about this model
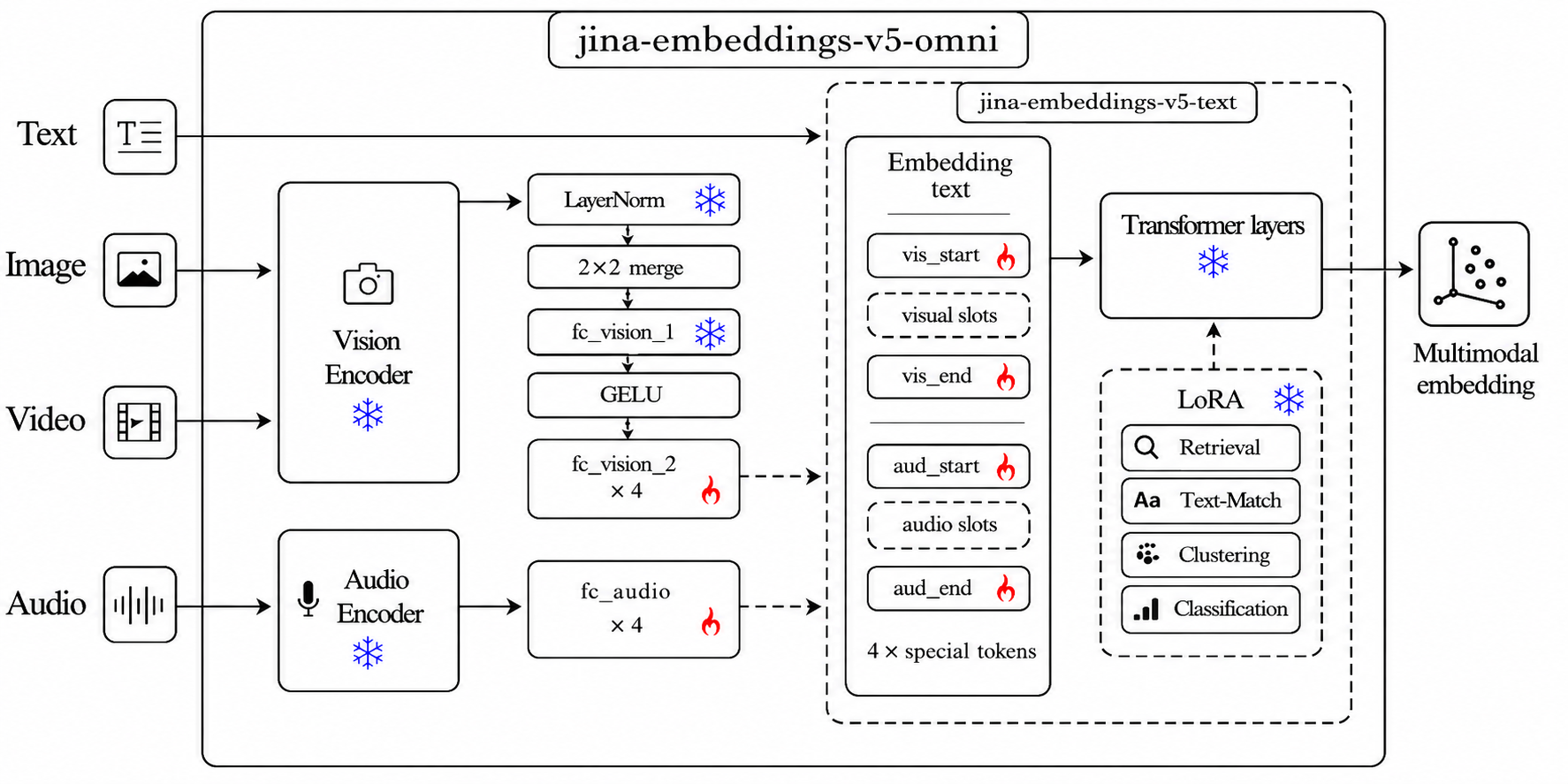
jina-embeddings-v5-omni-nano is a multimodal embedding model that accepts text, images, video, and audio, producing 768-dimensional L2-normalized embeddings in a shared vector space aligned with the text-only jina-embeddings-v5-text-nano, enabling cross-modality search without reindexing. It implements the GELATO architecture (Geometry-preserving Embeddings via Locked Aligned TOwers), where the backbone text model and non-text encoders remain frozen; only connecting components (0.35% of total weights) are trained.
Key Strengths
- Four task adapters built in: retrieval, classification, clustering, and text‑matching. Task‑specific variants are also available.
- Text embeddings are identical to those of
jina-embeddings-v5-text-nano– existing text‑only indices can be extended without rebuilding. - Supports nearly 100 languages and accepts a wide range of file types (images, video, audio, PDF).
- Runs on commodity hardware (not just GPU servers).
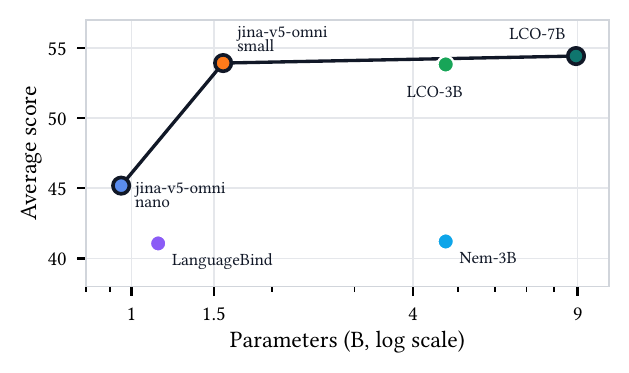
Performance
The GELATO approach yields results competitive with larger multimodal embedding models. jina-embeddings-v5-omni-small (the larger sibling) achieves best‑in‑class image benchmark scores for the ~1B parameter class and beats models up to 20× larger on multilingual visual understanding; jina-embeddings-v5-omni-nano defines the open‑weight frontier for its size on image (MIEB-Lite), video (MMEB-V), and audio (MAEB) benchmarks.
Supported Inputs and Capabilities
- Max sequence length: 8192 tokens
- Pooling: last‑token
- Image encoder: fine‑tuned SigLIP2 Base (from Qwen3.5‑0.8B)
- Audio encoder: Whisper‑large‑v3 (extracted from Qwen2.5‑Omni‑7B)
- License: cc‑by‑nc‑4.0 (Creative Commons Non‑Commercial)

best for
- ·Multimodal semantic search and RAG across text, images, video, and audio
- ·Zero-shot and few-shot classification with any input modality
- ·Clustering and topic discovery for mixed-media datasets
FAQ
It supports text, images, video, and audio, producing embeddings in a shared vector space.
The embedding dimension is 768 and the maximum sequence length is 8192 tokens.
At ~1.04B parameters, it is small enough to run on commodity hardware and defines the open-weight frontier for its size class on image, video, and audio benchmarks.
The model is licensed under cc-by-nc-4.0 (Creative Commons Non-Commercial).
Use the gigarouter OpenAI-compatible endpoint with your API key, sending input data as text, image URLs, video URLs, or audio URLs.
We're benchmarking and onboarding Jina Embeddings V5 Omni Nano as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.