Jina Embeddings V2 Small EN
jinaai/jina-embeddings-v2-small-en
published Sep 2023 · updated Jan 2025
Jina Embeddings V2 Small EN is a text embedding model that encodes English text into fixed-sized vectors, supporting up to 8192 tokens per input.
specs
| Task | Text Embedding |
| Architecture | BERT (JinaBERT) with ALiBi |
| Parameters | 33 million |
| License | Apache 2.0 |
| Max Sequence Length | 8192 tokens |
about this model
jina-embeddings-v2-small-en is an English monolingual embedding model that supports an 8192-token sequence length. Based on a BERT architecture with the symmetric bidirectional variant of ALiBi, the model was pretrained on the C4 dataset and further trained on over 400 million sentence pairs and hard negatives collected by Jina AI. With 33 million parameters, it delivers fast, memory-efficient inference while maintaining strong performance across embedding tasks.
The model was trained at a 512-token sequence length but extrapolates to 8k tokens (or longer) thanks to ALiBi, making it suitable for long document applications such as retrieval, semantic textual similarity, reranking, RAG, and generative search. According to the Jina Embeddings 2 paper (arXiv 2310.19923), the model matches the performance of OpenAI’s proprietary ada-002 model on MTEB benchmarks and shows extended-context benefits for tasks like NarrativeQA.
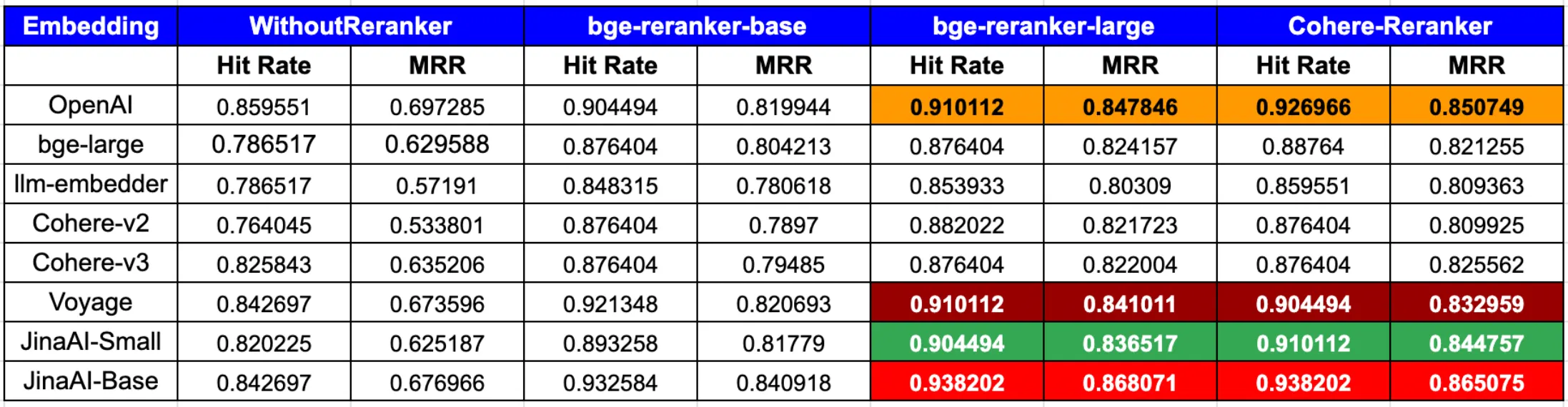
In evaluations reported by LlamaIndex, the combination of JinaAI-Base embeddings with a CohereRerank or bge-reranker-large reranker achieves peak hit rate and MRR for RAG pipelines.
The model is released under the Apache 2.0 license and is available in PyTorch, ONNX, Core ML, and Safetensors formats.
best for
- ·Long document retrieval (searching within articles or reports)
- ·Semantic textual similarity and clustering
- ·Retrieval-Augmented Generation (RAG) pipelines
FAQ
Up to 8192 tokens, enabled by ALiBi position encoding despite training on 512-token sequences.
According to the Jina Embeddings 2 paper, it matches the performance of OpenAI's ada-002 on the MTEB benchmark.
Apache 2.0, as listed on the Hugging Face model page.
Use the OpenAI-compatible endpoint with your gigarouter API key; refer to the gigarouter documentation for endpoint details.
Mean pooling is recommended to aggregate token embeddings into a single sentence vector.
We're benchmarking and onboarding Jina Embeddings V2 Small EN as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.