Jina Embeddings V2 Base EN
jinaai/jina-embeddings-v2-base-en
published Sep 2023 · updated Jan 2025
Jina Embeddings V2 Base EN is a text embedding model that supports up to 8192 tokens and is designed for long document retrieval, semantic search, and RAG applications.
specs
| Task | Text Embedding |
| Architecture | BERT with ALiBi (JinaBERT) |
| Parameters | 137 million |
| License | Apache 2.0 |
| Max Sequence Length | 8192 tokens |
| Task | Text Embedding |
| Architecture | BERT with ALiBi (JinaBERT) |
| Parameters | 137 million |
| License | Apache 2.0 |
| Max Sequence Length | 8192 tokens |
about this model
jina-embeddings-v2-base-en is an English monolingual text embedding model that supports an 8192-token sequence length. It is based on a BERT architecture enhanced with the symmetric bidirectional variant of ALiBi (Attention with Linear Biases), which enables input length extrapolation beyond the 512-token training limit. The model was pretrained on the C4 dataset and further fine-tuned on over 400 million sentence pairs and hard negatives from diverse domains. With 137 million parameters, it delivers efficient inference suitable for single-GPU deployment. Gigarouter hosts this model as a managed, OpenAI-compatible API, allowing developers to use it via a single API call without managing infrastructure.

Key Strengths and Performance
In the MTEB benchmark, Jina Embeddings 2 achieves state-of-the-art performance and matches the quality of OpenAI’s text-embedding-ada-002, as reported in the accompanying technical report. The model is released under the Apache-2.0 license.
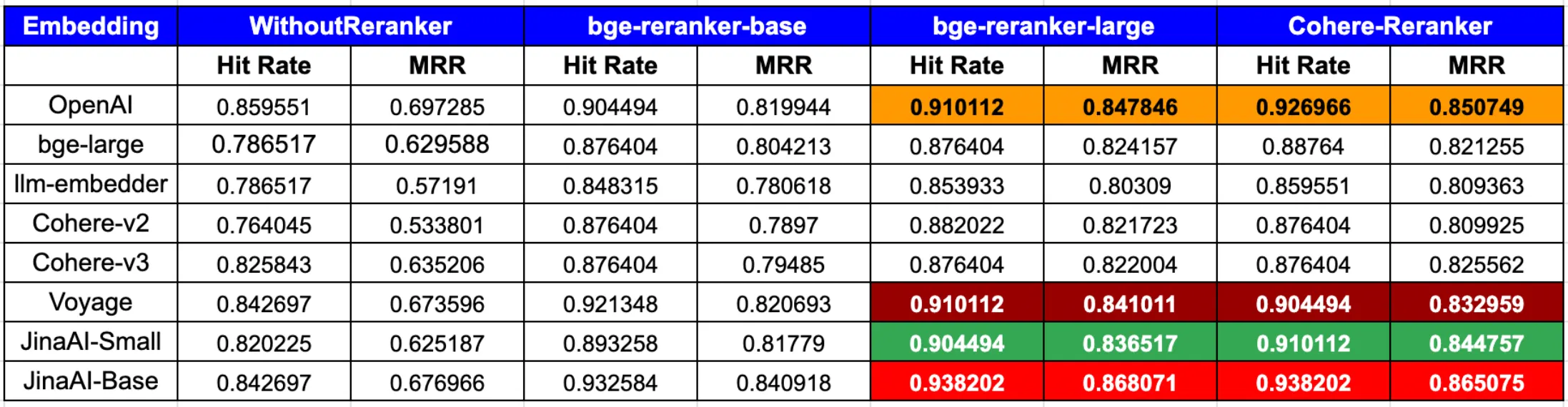
In retrieval-augmented generation (RAG) evaluations conducted by LlamaIndex, jina-embeddings-v2-base-en combined with a reranker yields strong results:
| Reranker | Hit Rate | MRR |
|---|---|---|
| bge-reranker-large | 0.938202 | 0.868539 |
| CohereRerank | 0.932584 | 0.873689 |
best for
- ·Long document retrieval and search
- ·Retrieval-Augmented Generation (RAG)
- ·Semantic textual similarity
FAQ
It supports up to 8192 tokens, thanks to ALiBi positional encoding.
Use the OpenAI-compatible endpoint with your gigarouter API key, specifying the model name jinaai/jina-embeddings-v2-base-en.
It has 137 million parameters and is recommended for single GPU inference for fast performance.
Apache 2.0 license.
Yes, mean pooling is recommended to produce high-quality sentence embeddings; the encode function handles this automatically when using the transformers package.
It supports up to 8192 tokens, thanks to ALiBi positional encoding.
Use the OpenAI-compatible endpoint with your gigarouter API key, specifying the model name jinaai/jina-embeddings-v2-base-en.
It has 137 million parameters and is recommended for single GPU inference for fast performance.
Apache 2.0 license.
Yes, mean pooling is recommended to produce high-quality sentence embeddings; the encode function handles this automatically when using the transformers package.
We're benchmarking and onboarding Jina Embeddings V2 Base EN as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.