Fish Audio S2 Pro
fishaudio/s2-pro
published Mar 2026 · updated Mar 2026
Fish Audio S2 Pro is a text-to-speech model that generates expressive, multi-speaker speech with fine-grained inline control of prosody and emotion via natural-language tags.
specs
| Task | Text-to-Speech (TTS) |
| Architecture | Dual-Autoregressive Transformer (Slow AR 4B, Fast AR 400M) with RVQ audio codec |
| Parameters | 4.4B total |
| License | Fish Audio Research License (research/non-commercial free; commercial requires separate license) |
| Languages | 80+ languages, including English, Japanese, Chinese, Korean, Spanish, French, German, etc. |
about this model
Fish Audio S2 Pro is a text-to-speech (TTS) model that combines a dual-autoregressive (Dual-AR) transformer architecture with reinforcement learning alignment to enable fine-grained inline control of prosody, emotion, and voice style. Trained on over 10 million hours of audio across 80+ languages, the model uses a 4-billion-parameter "Slow AR" decoder to predict the primary semantic codebook along the time axis, while a 400-million-parameter "Fast AR" decoder generates the remaining 9 residual codebooks at each time step, preserving acoustic fidelity with efficient inference.
Key capabilities
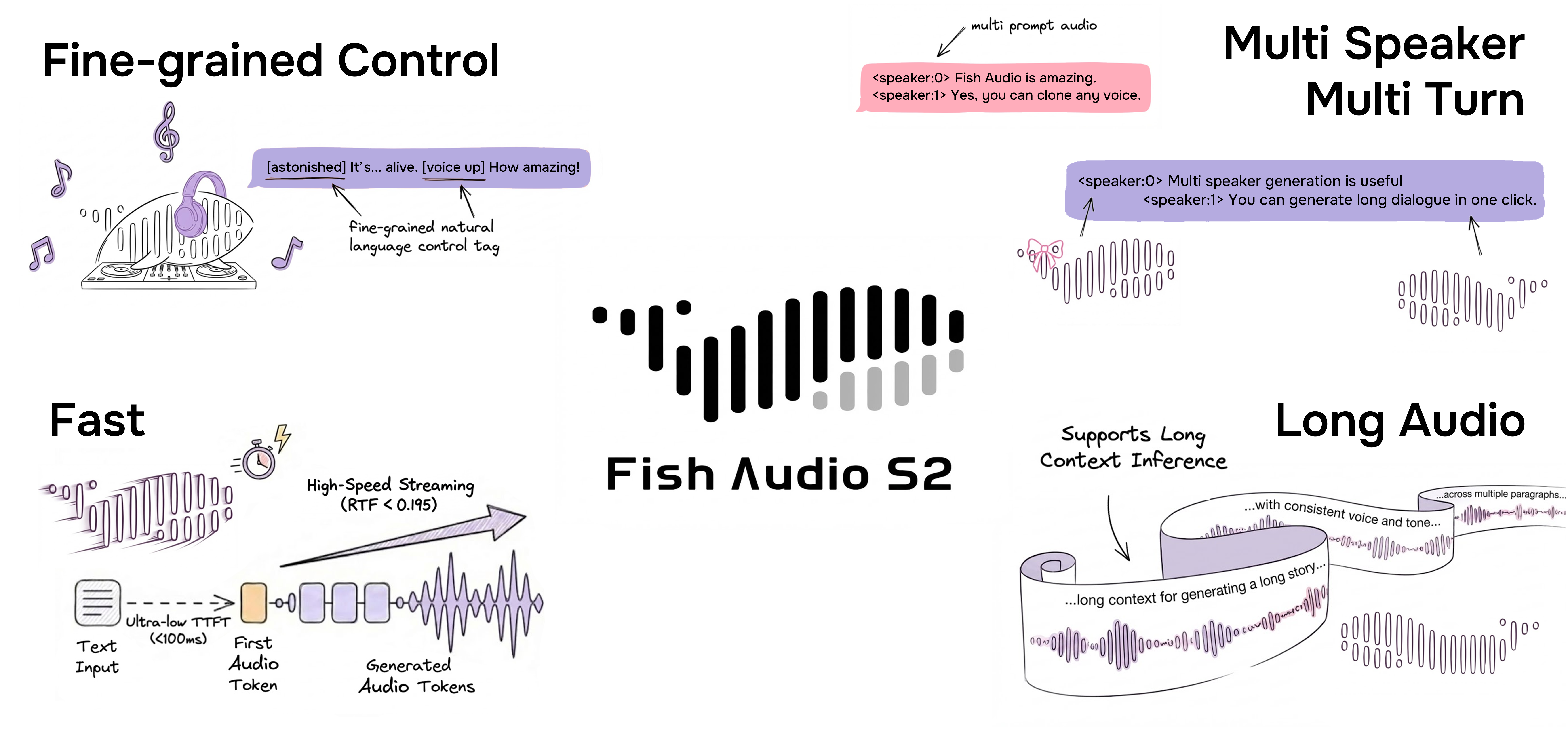
- Inline control through natural language: Users embed free-form textual instructions (e.g.,
[whisper in small voice],[professional broadcast tone]) directly in the input text. Over 15,000 unique tags are supported, allowing open-ended expression at the word level without predefined labels. - Multilingual support: Tier-1 languages are Japanese, English, and Chinese; Tier-2 includes Korean, Spanish, Portuguese, Arabic, Russian, French, and German, with 70+ additional languages.
- Dual-AR architecture: Because the architecture is structurally isomorphic to autoregressive LLMs, it inherits all SGLang-native serving optimizations—continuous batching, paged KV cache, CUDA graph replay, and RadixAttention-based prefix caching.
Production streaming performance (single NVIDIA H200 GPU)
- Real-time factor (RTF): 0.195
- Time-to-first-audio: ~100 ms
- Throughput: 3,000+ acoustic tokens/s while maintaining RTF below 0.5
For further details, see the technical report, the model repository, and the Fish Audio playground.
best for
- ·Creating expressive, controllable speech for audiobooks and podcasts
- ·Building real-time voice assistants with low-latency streaming
- ·Generating multi-turn dialogue with consistent speaker voices
FAQ
It uses a decoder-only transformer with a Dual-Autoregressive (Dual-AR) design: a 4B parameter Slow AR for primary semantic codebook and a 400M parameter Fast AR for residual acoustic details.
4.4B parameters total (4B Slow AR + 400M Fast AR).
Over 80 languages, with Tier 1 support for Japanese, English, and Chinese, and Tier 2 for Korean, Spanish, Portuguese, Arabic, Russian, French, German, and many others.
Insert free-form natural-language tags in the text, e.g., `[whisper]`, `[angry]`, `[excited tone]`, or custom descriptions like `[professional broadcast tone]`. The model supports 15,000+ unique tags.
Research and non-commercial use is free, but commercial use requires a separate license from Fish Audio. Contact [email protected].
Use the OpenAI-compatible endpoint with your gigarouter API key. Provide input text and optional tags. Refer to the gigarouter documentation for endpoint details.
We're benchmarking and onboarding Fish Audio S2 Pro as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.