Higgs TTS 3
bosonai/higgs-tts-3-4b
published Jun 2026 · updated Jun 2026
Higgs TTS 3 is a TTS model that generates expressive conversational speech with zero-shot voice cloning and inline control over emotion, style, prosody, pauses, and sound effects across 100+ languages.
specs
| Task | Text-to-Speech (TTS) |
| Architecture | ~4B autoregressive decoder with multi-codebook fused embedding/head, Higgs Tokenizer (8 codebooks, 25 fps) |
| Parameters | ~4 billion |
| License | Boson Higgs TTS 3 Research and Non-Commercial License (non-commercial use only; commercial requires separate license) |
about this model
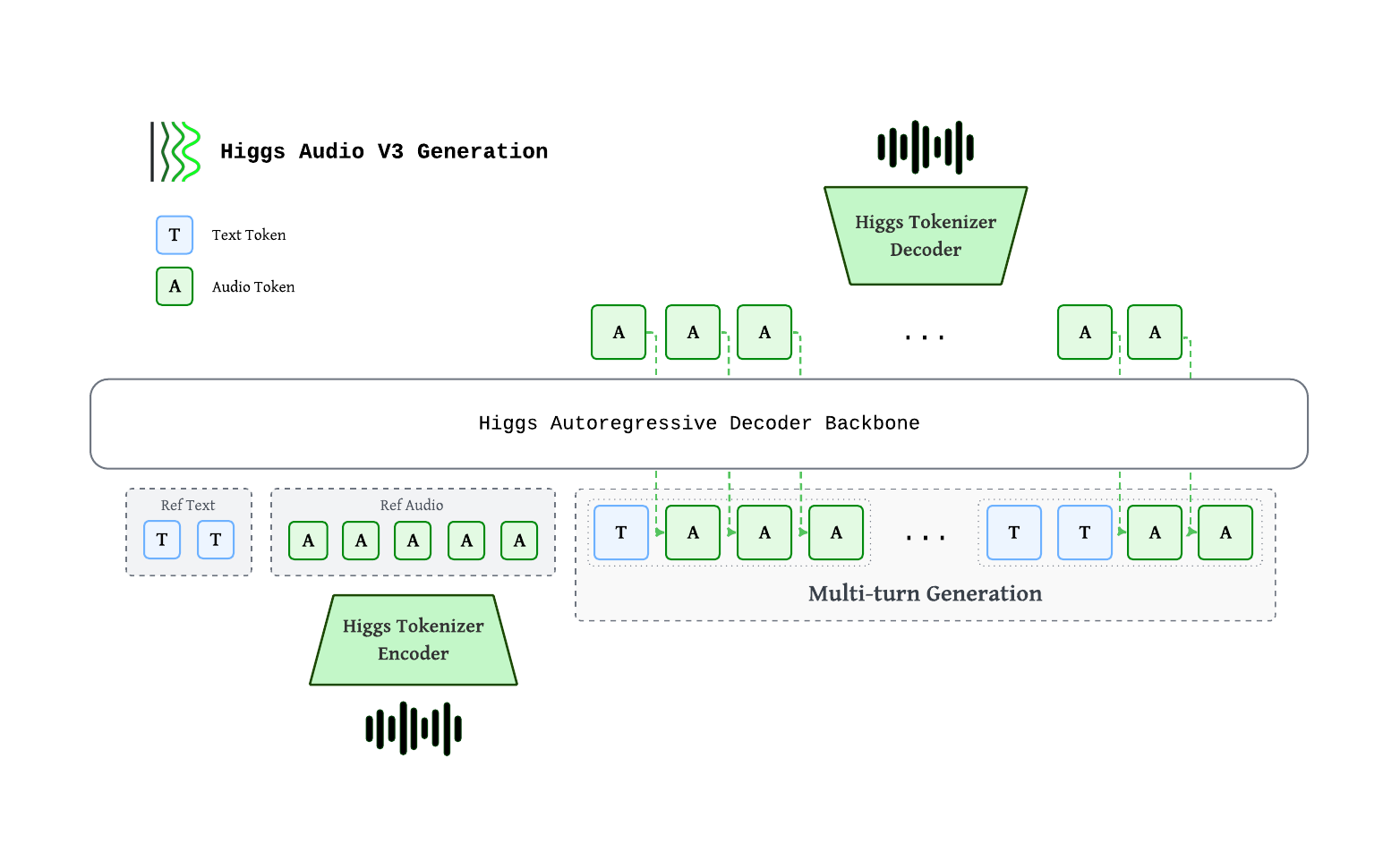
bosonai/higgs-tts-3-4b is a text-to-speech (TTS) model designed for voice chat, producing expressive conversational speech across over 100 languages with zero-shot voice cloning and inline control over emotion, style, prosody, pauses, and sound effects. Hosted on gigarouter as an OpenAI-compatible API, the model is built on a ~4B autoregressive decoder backbone (36 layers, hidden size 2560, GQA 32/8) with a Higgs Tokenizer that encodes audio into 8 codebooks at 25 fps. It outputs 24 kHz waveforms at 40 ms per frame.
Multilingual Performance
The model achieves single-digit word error rate (WER) or character error rate (CER) on 102 languages. 85 languages score below 5 (polished quality), and 17 languages score between 5 and 10 (usable). Benchmark results from the Boson blog show Higgs TTS 3 outperforming both its predecessor and the best non-Higgs model across four multilingual tests:
| Benchmark | Higgs TTS 3 | Best non-Higgs |
|---|---|---|
| SeedTTS | 1.11 | 1.21 |
| CV3 | 4.41 | 4.60 |
| MiniMax-Multilingual | 2.74 | 2.98 |
| Higgs-Multilingual (111 languages) | 3.61 | 3.63 |
Conversational Benchmarks
In win-rate evaluations against models including Fish Audio S2 Pro, Qwen3-TTS-1.7B, IndexTTS-2, MOSS-TTS-v1.5, and OmniVoice, Higgs TTS 3 achieved an overall win rate of 53.65%. Category breakdowns: Emotions 53.75%, Foreign Words 48.75%, Paralinguistics 68.57%, Complex Pronunciation 25.10%, Questions 61.43%, Syntactic Complexity 60.71%. Results have been reproduced by the SGLang-Omni team.
Control Tokens
Inline control tokens follow <|category:value|> syntax and can be inserted mid-utterance. Supported categories include 21 emotions (e.g., <|emotion:elation|>, <|emotion:anger|>), 3 styles (<|style:singing|>, <|style:shouting|>, <|style:whispering|>), and 9 sound effects (e.g., <|sfx:laughter|>, <|sfx:cough|>). Detailed prompting examples are available in the model’s PROMPTING.md.
best for
- ·Voice chatbots and conversational AI
- ·Expressive narration for audiobooks and stories
- ·Multilingual customer service voice responses
- ·Zero-shot voice cloning for personalized assistants
FAQ
It supports 100+ languages with single-digit WER/CER on 102 languages; 85 languages achieve below 5% WER/CER.
Yes, by inserting control tokens like <|emotion:anger|> or <|style:whispering|> in the text.
It achieves lower WER across benchmarks than Higgs TTS 2 and outperforms models like SeedTTS and Qwen3-TTS in conversational benchmarks (53.65% overall win rate).
Use the OpenAI-compatible endpoint with your API key, passing the text and optional control tokens.
It is released for research and non-commercial use under the Boson Higgs TTS 3 Research and Non-Commercial License; commercial use requires a separate license.
We're benchmarking and onboarding Higgs TTS 3 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.