Higgs TTS 2 Base
bosonai/higgs-tts-2-3b-base
published Jul 2025 · updated Jun 2026
Higgs TTS 2 Base is a text-to-speech model that generates expressive, multilingual speech with zero-shot voice cloning and emergent capabilities like prosody adaptation and multi-speaker dialogue.
specs
| Task | Text-to-Speech |
| Architecture | Llama-3.2-3B with DualFFN Audio Adapter |
| Parameters | 5.8B total (3.6B LLM + 2.2B DualFFN) |
| Audio Quality | 24 kHz sampling rate |
| Training Data | Over 10 million hours of audio (AudioVerse) |
about this model
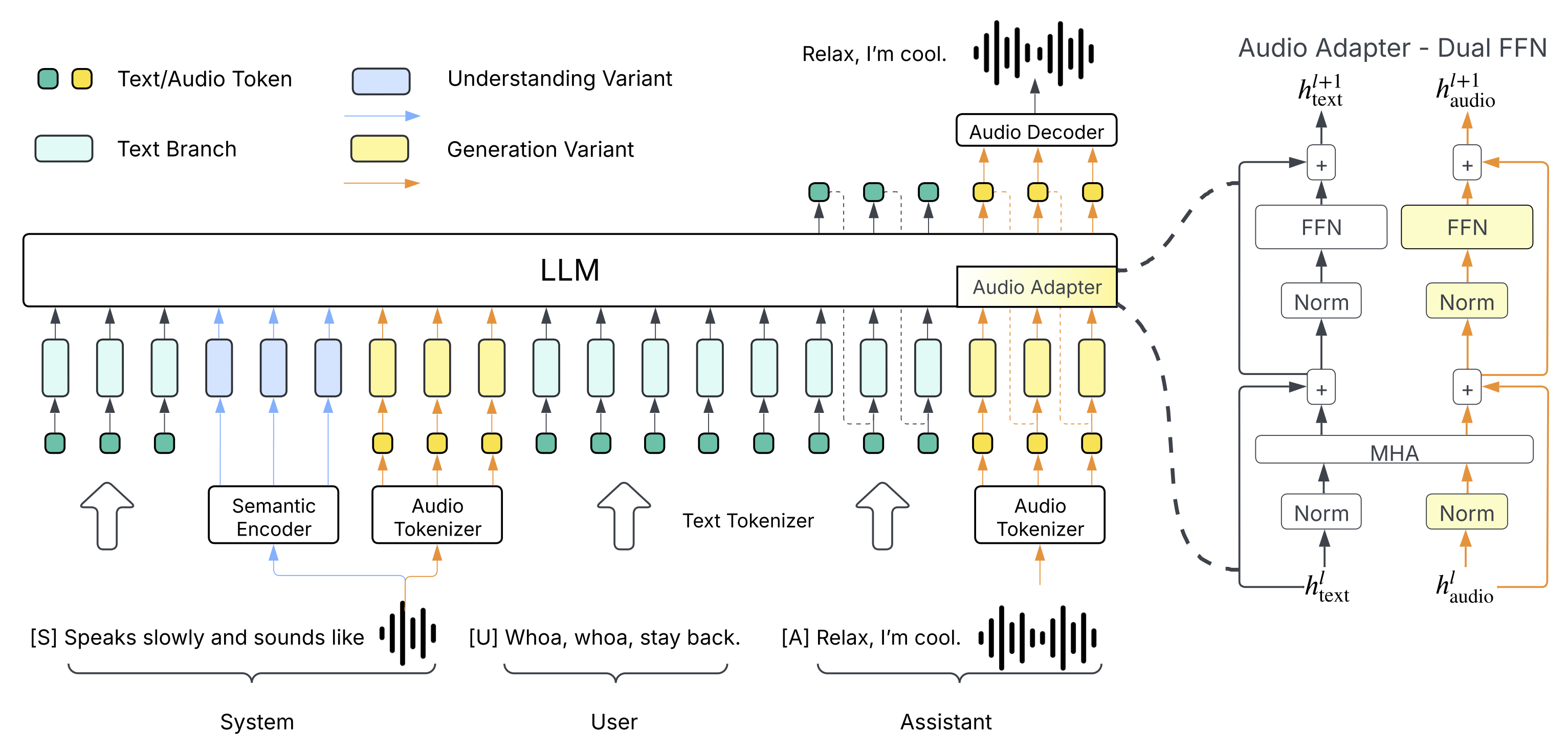
Higgs TTS 2 (base) is a text-to-speech model that generates expressive speech from text input using a 3.6B-parameter Llama-3.2-3B backbone augmented with a 2.2B-parameter DualFFN audio adapter, resulting in training and inference FLOPs equivalent to the 3B LLM alone.
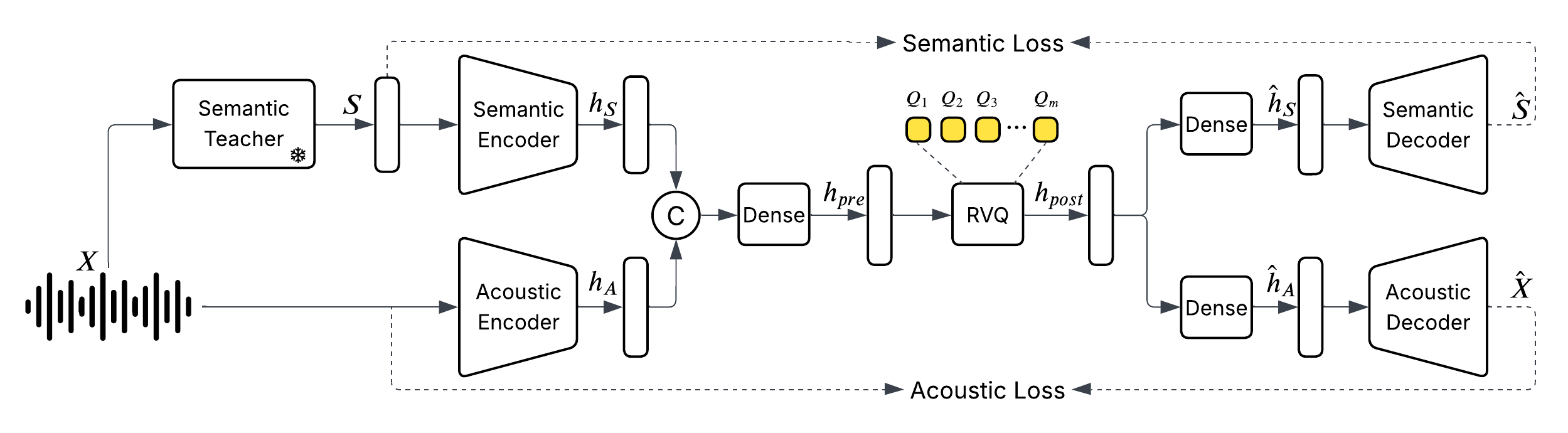
Pretrained on over 10 million hours of diverse audio data (speech, music, sound events) at 24 kHz, the model uses a unified audio tokenizer operating at 25 frames per second that captures both semantic and acoustic features. The DualFFN architecture preserves 91% of the original LLM’s training speed while improving word error rate and speaker similarity, as shown in ablation studies.
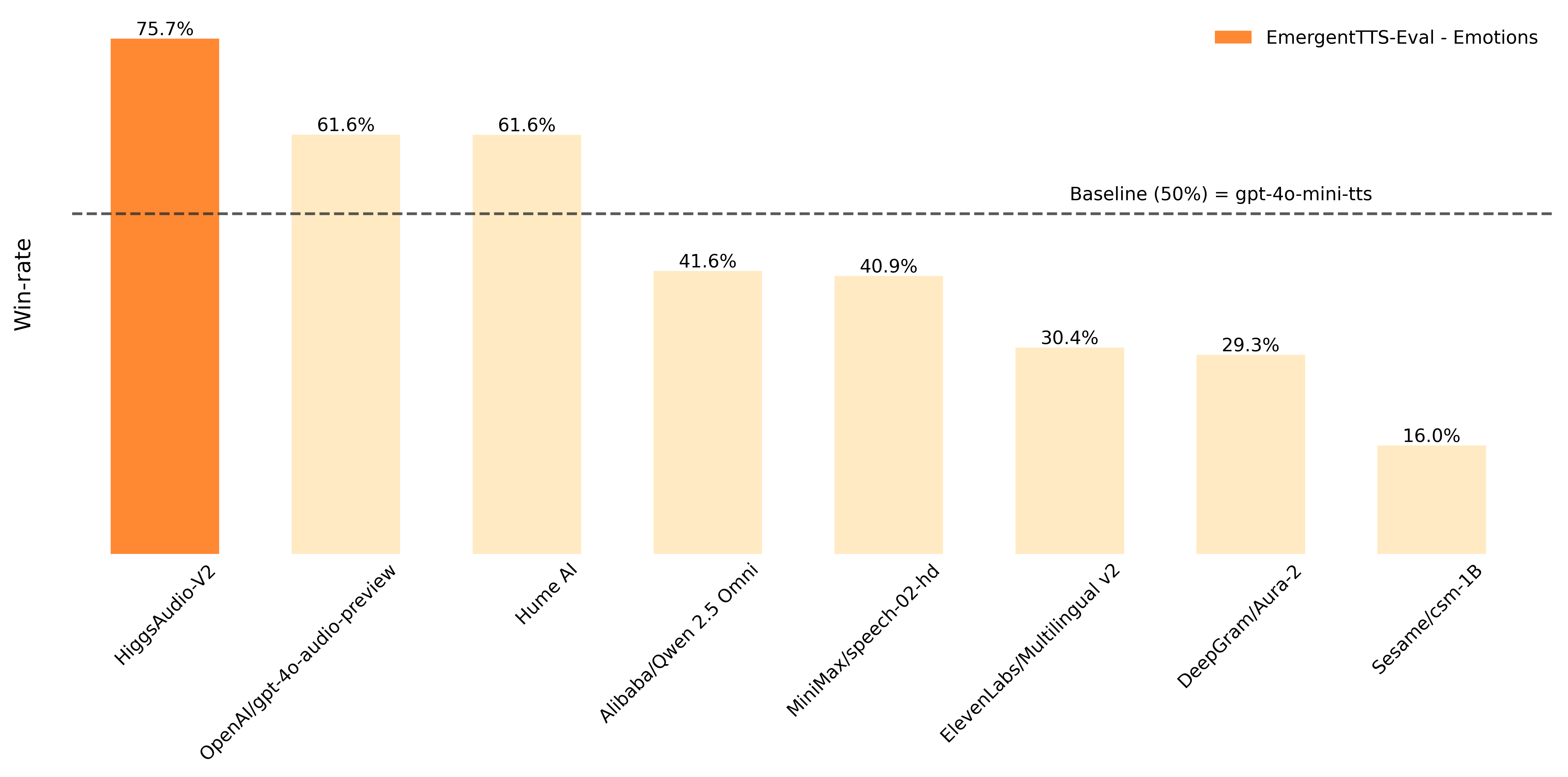
On the EmergentTTS-Eval benchmark, Higgs TTS 2 achieves a win rate of 75.71% over gpt-4o-mini-tts for the “Emotions” category and 55.71% for “Questions” (judge: Gemini 2.5 Pro). On Seed-TTS Eval and Emotional Speech Dataset (ESD), the model demonstrates competitive performance:
| Benchmark | Metric | Value |
|---|---|---|
| Seed-TTS Eval | WER ↓ | 2.44 |
| Seed-TTS Eval | SIM ↑ | 67.70 |
| ESD | WER ↓ | 1.78 |
| ESD | SIM (emo2vec) ↑ | 86.13 |
The model also supports zero-shot multi-speaker dialog generation, automatic prosody adaptation, and simultaneous speech and background music generation.
best for
- ·Expressive narration with automatic prosody adaptation
- ·Zero-shot multi-speaker dialogue generation
FAQ
It accepts a chat template with text and optional reference audio, processed by AutoProcessor.
It generates 24 kHz audio in a waveform or audio file.
It achieves a 75.7% win rate over GPT-4o-mini-tts on Emotions in EmergentTTS-Eval.
Yes, it is available as a hosted OpenAI-compatible API on gigarouter with an API key.
At least an RTX 4090 for efficient inference of the 3B model.
We're benchmarking and onboarding Higgs TTS 2 Base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.