Supertonic 3
Supertone/supertonic-3
published May 2026 · updated May 2026
Supertonic 3 is a lightweight on-device multilingual text-to-speech system that runs with ONNX Runtime for local inference.
specs
| Task | Text-to-Speech |
| Architecture | ONNX Runtime-based |
| Parameters | ~99M |
| License | OpenRAIL-M (model) and MIT (sample code) |
about this model
Supertonic 3 is a text-to-speech model that synthesizes speech in 31 languages from a compact 99M-parameter ONNX runtime, optimized for low-latency inference on CPU and edge devices. It is hosted by gigarouter as an OpenAI-compatible API, allowing developers to integrate high-quality multilingual TTS without managing infrastructure.
Key Capabilities
- 31 languages including English, Korean, Japanese, Arabic, and all EU languages (see language table).
- Improved reading stability over Supertonic 2 — fewer repeat and skip failures, especially on short and long utterances.
- Higher speaker similarity across the shared-language set compared with Supertonic 2.
- Expression tags (e.g.,
<laugh>,<breath>,<sigh>) add natural prosodic nuances without reference audio. - Outputs 44.1 kHz 16-bit WAV directly, ready for playback without upsampling.
- 10 preset voice styles (M1–M5, F1–F5) included; zero-shot custom voice styles can be created via the Supertonic Voice Builder.
Benchmark Highlights
Across measured languages, Supertonic 3 achieves competitive Word Error Rate (WER) and Character Error Rate (CER) compared with larger open TTS models such as VoxCPM2, while remaining lightweight enough for CPU-only deployment.
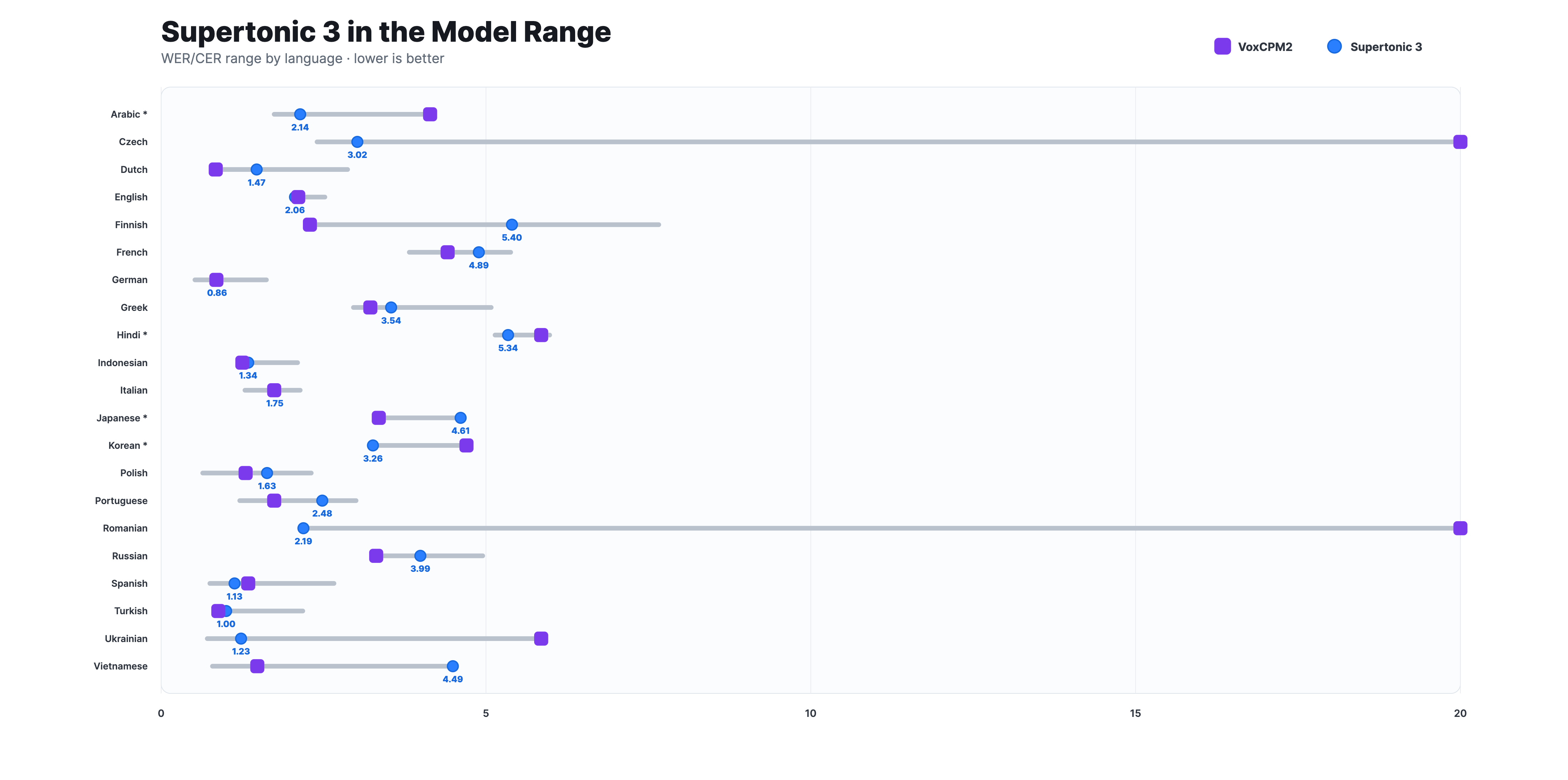
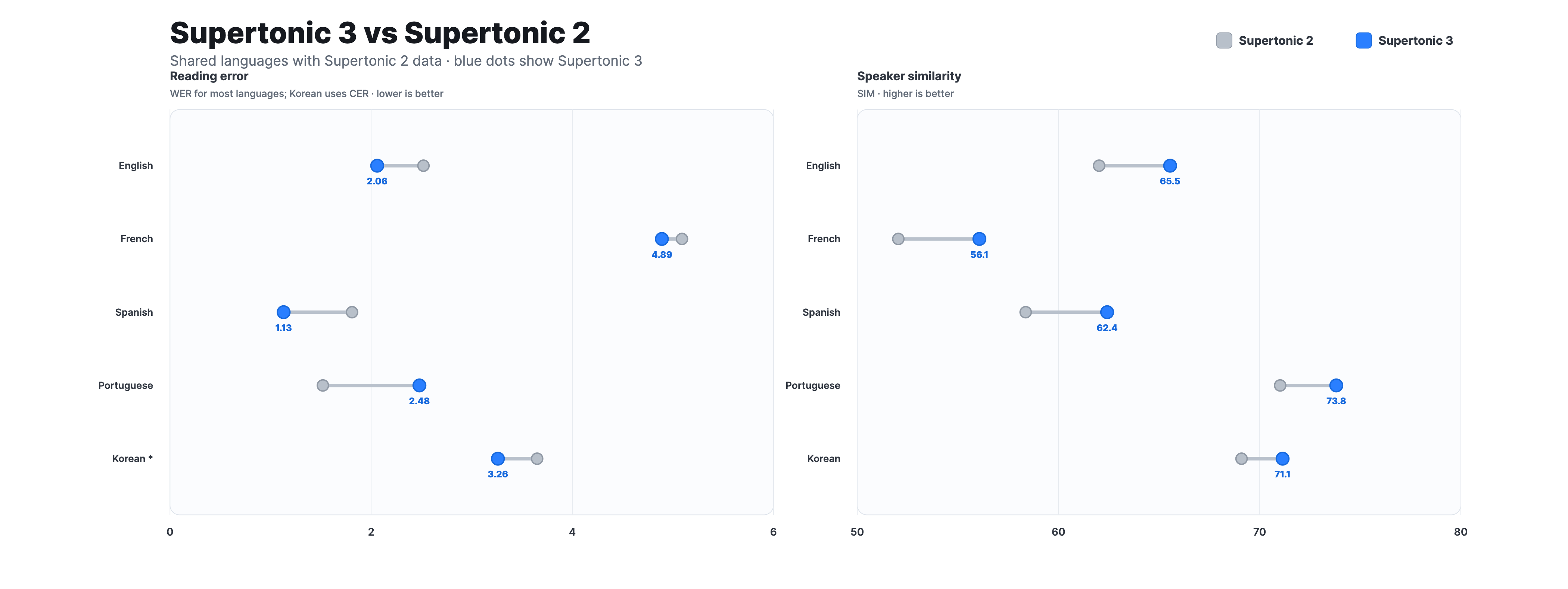
Compared with Supertonic 2, Supertonic 3 reduces repeat/skip failures and improves speaker similarity.
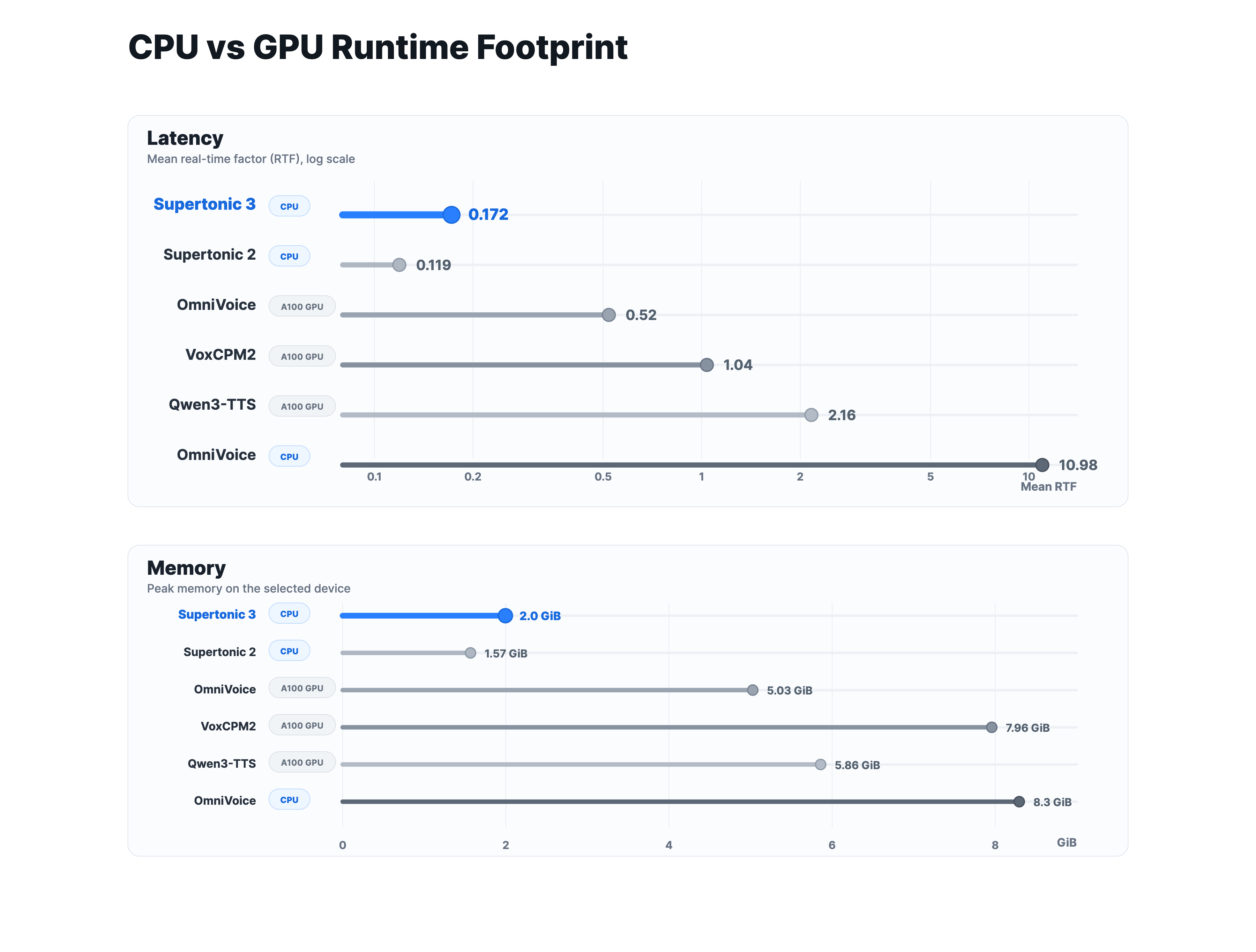
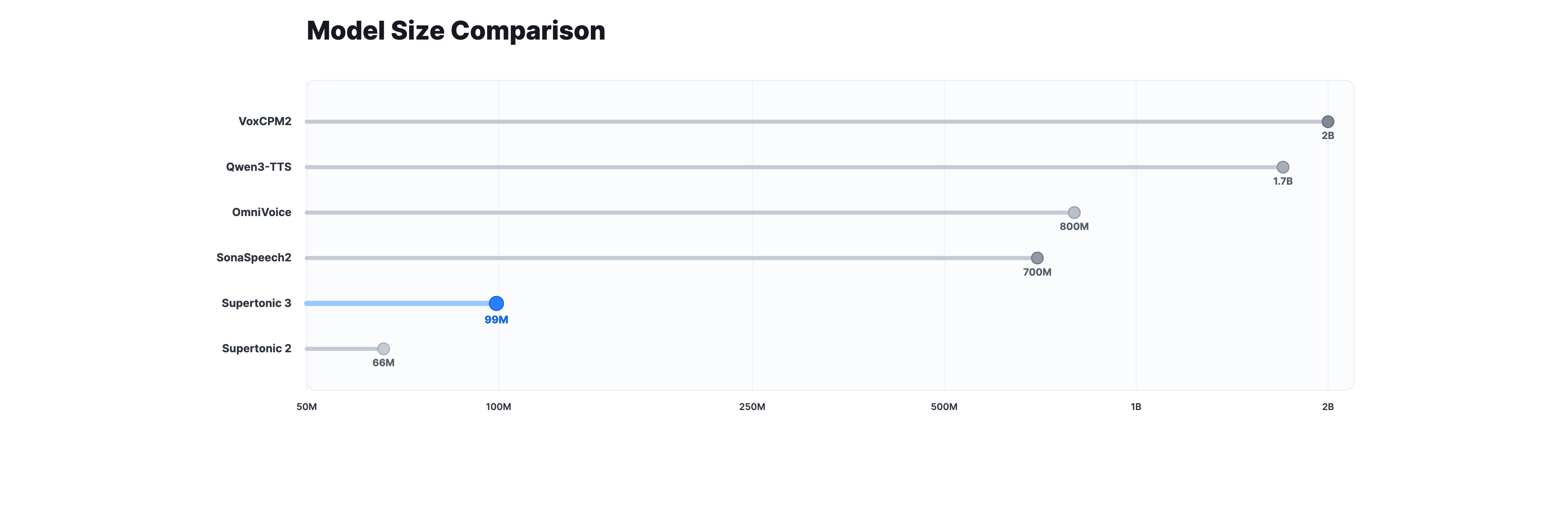
Runtime and Model Size
Supertonic 3 runs fast on CPU (even against baselines measured on A100 GPU) and uses substantially less memory. The public ONNX assets total ~99M parameters, making it far smaller than 0.7B–2B class TTS systems.
Supported Languages
| Code | Language | Code | Language | Code | Language | Code | Language |
|---|---|---|---|---|---|---|---|
| en | English | ko | Korean | ja | Japanese | ar | Arabic |
| bg | Bulgarian | cs | Czech | da | Danish | de | German |
| el | Greek | es | Spanish | et | Estonian | fi | Finnish |
| fr | French | hi | Hindi | hr | Croatian | hu | Hungarian |
| id | Indonesian | it | Italian | lt | Lithuanian | lv | Latvian |
| nl | Dutch | pl | Polish | pt | Portuguese | ro | Romanian |
| ru | Russian | sk | Slovak | sl | Slovenian | sv | Swedish |
| tr | Turkish | uk | Ukrainian | vi | Vietnamese |
Audio Samples
Reference-generated pairs across English, Japanese, Korean, and news reading styles are available at the official demo page.
best for
- ·On-device real-time speech synthesis for apps and browser extensions
- ·Multilingual audiobook narration and voice assistants
- ·Privacy-preserving TTS for edge devices like Raspberry Pi
FAQ
31 languages including English, Korean, Japanese, Arabic, and many more.
Approximately 99 million parameters.
44.1kHz 16-bit WAV.
Use the gigarouter OpenAI-compatible endpoint with your API key.
Runs on CPU, no GPU required; minimal dependencies.
We're benchmarking and onboarding Supertonic 3 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.