Qwen3-TTS 0.6B Base
Qwen/Qwen3-TTS-12Hz-0.6B-Base
published Jan 2026 · updated Jan 2026
Qwen3-TTS 0.6B Base is a text-to-speech model that supports multilingual voice cloning and description-based control.
specs
| Task | Text-to-Speech (TTS) |
| Architecture | Discrete multi-codebook LM with Qwen3-TTS-Tokenizer-12Hz |
| Parameters | 0.6B |
| License | Apache 2.0 |
| Languages | 10 (Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian) |
| Streaming Latency | As low as 97ms end-to-end |
about this model
Qwen3-TTS-12Hz-0.6B-Base is a multilingual text-to-speech model that generates high-quality speech from text, supporting voice cloning from a 3-second audio sample and description-based control over acoustic attributes. Trained on over 5 million hours of speech data covering 10 languages (Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian) and multiple dialectal profiles, it is designed for robust, low-latency streaming synthesis.
The model uses a dual-track language model (LM) architecture with the proprietary Qwen3-TTS-Tokenizer-12Hz, a 12.5 Hz, 16-layer multi-codebook codec that achieves extreme bitrate reduction. This enables end-to-end synthesis latency as low as 97 ms (first audio packet emitted immediately), making it suitable for real-time interactive applications. The architecture also includes a lightweight causal ConvNet for streaming waveform reconstruction.
Key capabilities include rapid voice cloning, speech generation driven by natural language instructions (e.g., tone, speaking rate, emotion), and flexible voice design. The 0.6B parameter Base model is one of two released sizes (0.6B and 1.7B) under the Apache 2.0 license. Evaluation across benchmarks such as the TTS multilingual test set, InstructTTSEval, and a long speech test set demonstrates state-of-the-art performance in both objective and subjective measures.
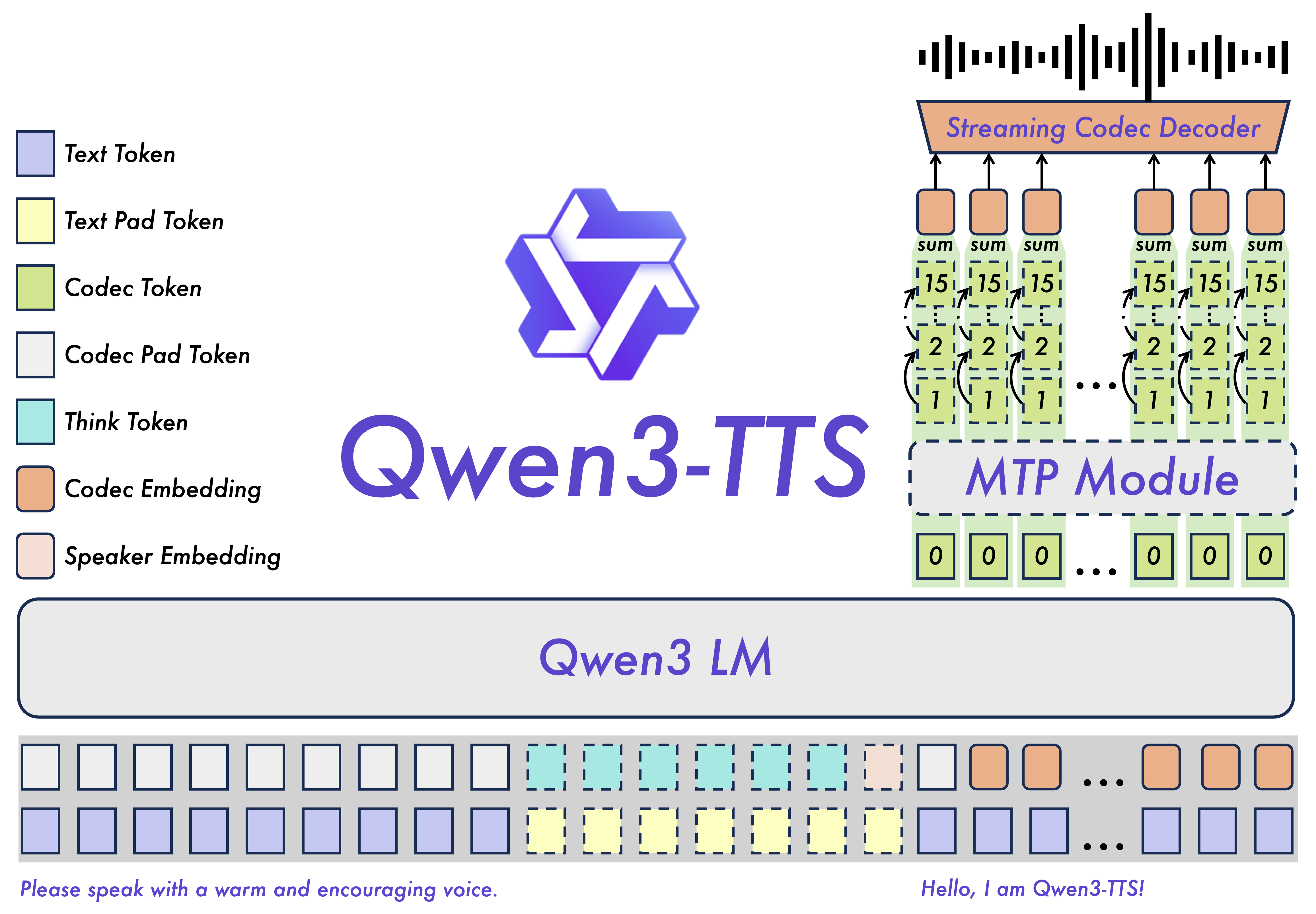
For developers, this model is hosted as a managed, OpenAI-compatible API on gigarouter, eliminating the need for local setup. All features—voice clone, voice design, multilingual synthesis, and low-latency streaming—are accessible via a single API call. The model is released under the Apache 2.0 license, with technical details documented in the Qwen3-TTS Technical Report.
best for
- ·Real-time voice cloning for multilingual chatbots
- ·Description-based voice control for audiobook narration
- ·Low-latency speech synthesis for interactive voice assistants
FAQ
It has 0.6B parameters and can achieve end-to-end synthesis latency as low as 97ms.
Yes, with only 3 seconds of reference audio.
10 languages: Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian.
Apache 2.0.
Use the gigarouter OpenAI-compatible endpoint with an API key.
We're benchmarking and onboarding Qwen3-TTS 0.6B Base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.