MOSS TTS Nano
OpenMOSS-Team/MOSS-TTS-Nano-100M
published Apr 2026 · updated Apr 2026
MOSS TTS Nano is a tiny multilingual speech generation model that produces 48 kHz stereo audio from text, supports zero-shot voice cloning, and runs on CPU without a GPU.
specs
| Task | Text-to-Speech (TTS) |
| Architecture | Autoregressive Audio Tokenizer + LLM (CAT-based) |
| Parameters | 0.1B (100 million) |
| Output Audio | 48 kHz, 2-channel stereo |
| License | Not yet licensed (see LICENSE file) |
about this model
MOSS-TTS-Nano is a multilingual text-to-speech model that generates 48 kHz stereo speech using a pure autoregressive Audio Tokenizer + LLM pipeline, with only 0.1B parameters.
The model is designed for real-time speech generation with minimal footprint. It supports streaming inference and can run on a 4-core CPU without a GPU. Voice cloning is the primary workflow, enabling zero-shot cloning from a reference audio prompt. An ONNX CPU version is available that removes PyTorch dependencies and delivers nearly 2x processing efficiency compared to the original.
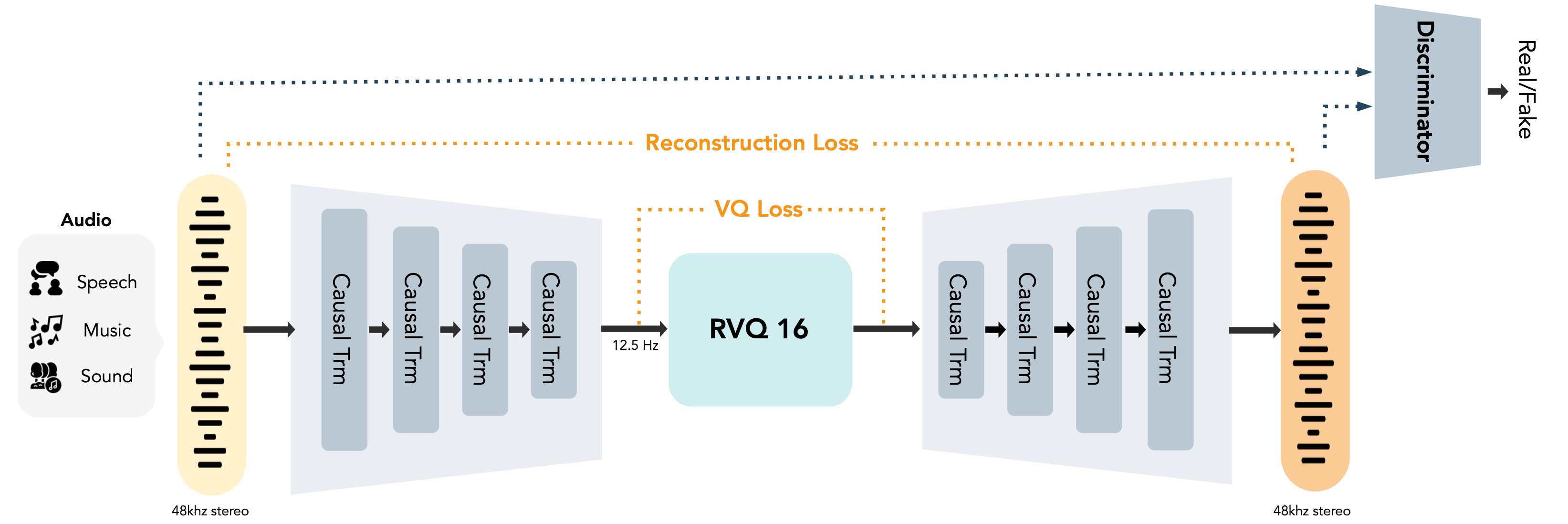
MOSS-TTS-Nano is built on the MOSS-Audio-Tokenizer-Nano backbone: a lightweight tokenizer with approximately 20 million parameters that compresses 48 kHz stereo audio into a 12.5 Hz token stream using RVQ with 16 codebooks, supporting variable bitrates from 0.125 kbps to 4 kbps.

Supported Languages
| Language | Code | Language | Code | Language | Code |
|---|---|---|---|---|---|
| Chinese | zh | English | en | German | de |
| Spanish | es | French | fr | Japanese | ja |
| Italian | it | Hungarian | hu | Korean | ko |
| Russian | ru | Persian (Farsi) | fa | Arabic | ar |
| Polish | pl | Portuguese | pt | Czech | cs |
| Danish | da | Swedish | sv | Greek | el |
| Turkish | tr |

The model also supports long-form text input with automatic chunked voice cloning, and is designed for simple local setup, web serving, and lightweight product integration. Finetuning code and a local reader application are available separately.
best for
- ·Zero-shot voice cloning from a short reference audio
- ·Multilingual TTS in 20 languages
- ·CPU-based real-time speech generation for local demos and lightweight products
FAQ
It is best for zero-shot voice cloning and real-time multilingual speech synthesis, especially in CPU-friendly, low-latency deployments.
It supports 20 languages including Chinese, English, German, Spanish, French, Japanese, Korean, and more.
Yes, it can run on a 4-core CPU for streaming inference, and an ONNX version provides near 2x speed on a single CPU core.
The output is 48 kHz stereo (2-channel) WAV audio, generated via voice cloning with a reference audio prompt.
Send a request to the gigarouter OpenAI-compatible endpoint with your API key; the model accepts text and optional reference audio for voice cloning.
We're benchmarking and onboarding MOSS TTS Nano as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.