KaLM embedding multilingual mini instruct v2
HIT-TMG/KaLM-embedding-multilingual-mini-instruct-v2
published Jun 2025 · updated Oct 2025
A popular open embeddings model, with 919 downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
HIT-TMG/KaLM-embedding-multilingual-mini-instruct-v2 is a multilingual text embedding model that converts sentences and passages into fixed-length vector representations for retrieval, classification, clustering, and semantic similarity tasks. Built on a 0.5B parameter Qwen2 backbone, it uses bidirectional attention and simple mean pooling to produce dense embeddings, supporting input sequences of up to 32,768 tokens and offering Matryoshka Representation Learning dimensions (896, 512, 256, 128, 64).
Architecture and Training
The model employs a progressive multi-stage training pipeline: weak-supervised pre-training on over 20 data categories, supervised fine-tuning on 100 categories, and contrastive distillation with soft signals. Key innovations include a focal-style reweighting mechanism that emphasizes difficult samples and an online hard-negative mixing strategy that enriches training pairs. These techniques, combined with ranking consistency filtering and persona-based synthetic data generation, improve both performance and generalization across languages.
Benchmark Performance
On the Massive Text Embedding Benchmark (MTEB) for both Chinese and English, the model achieves state-of-the-art results among sub-1B parameter models, rivaling embedding models 3–26 times larger. The following figures compare its performance on MTEB (Chinese and English) against other models.
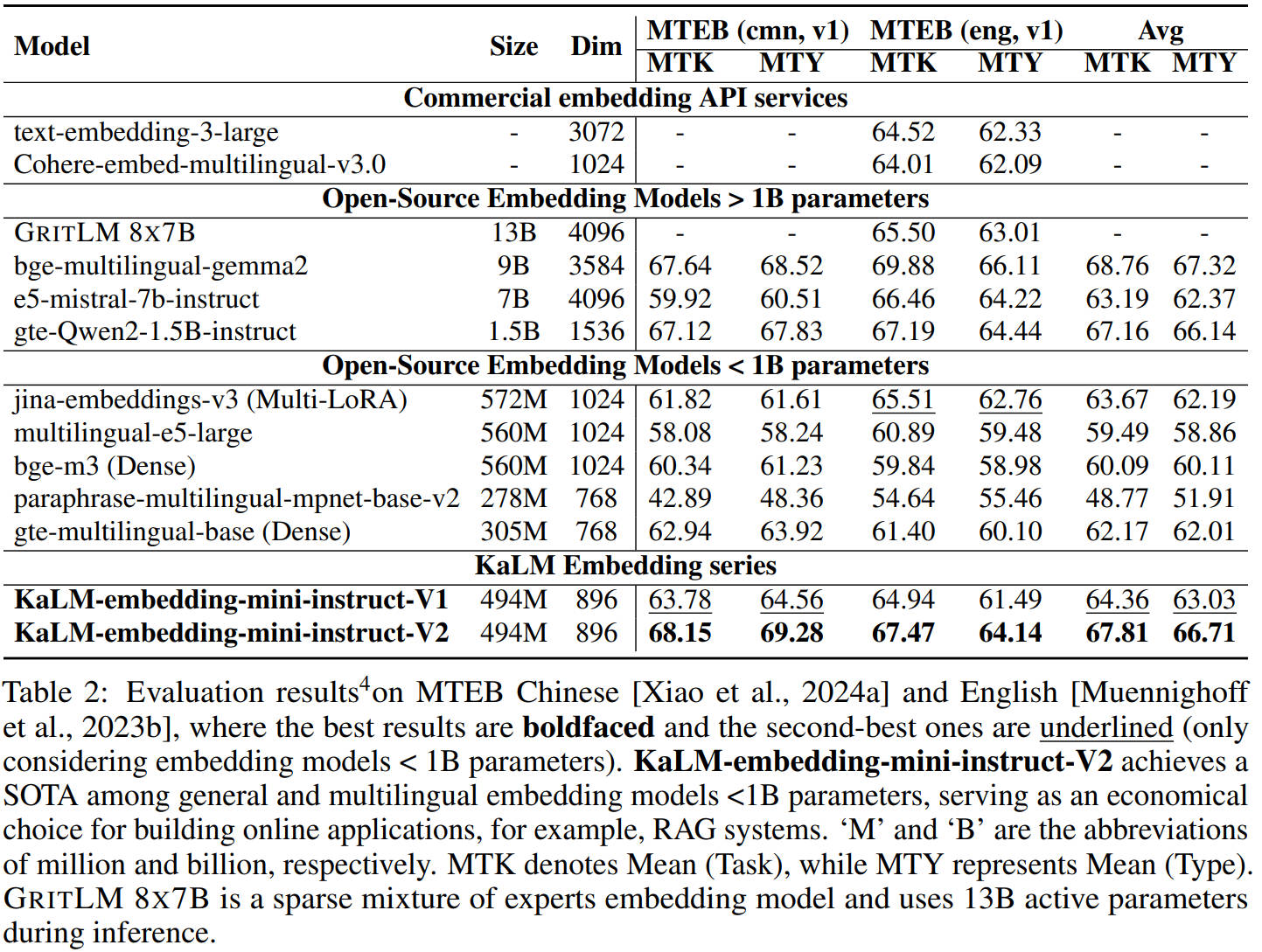
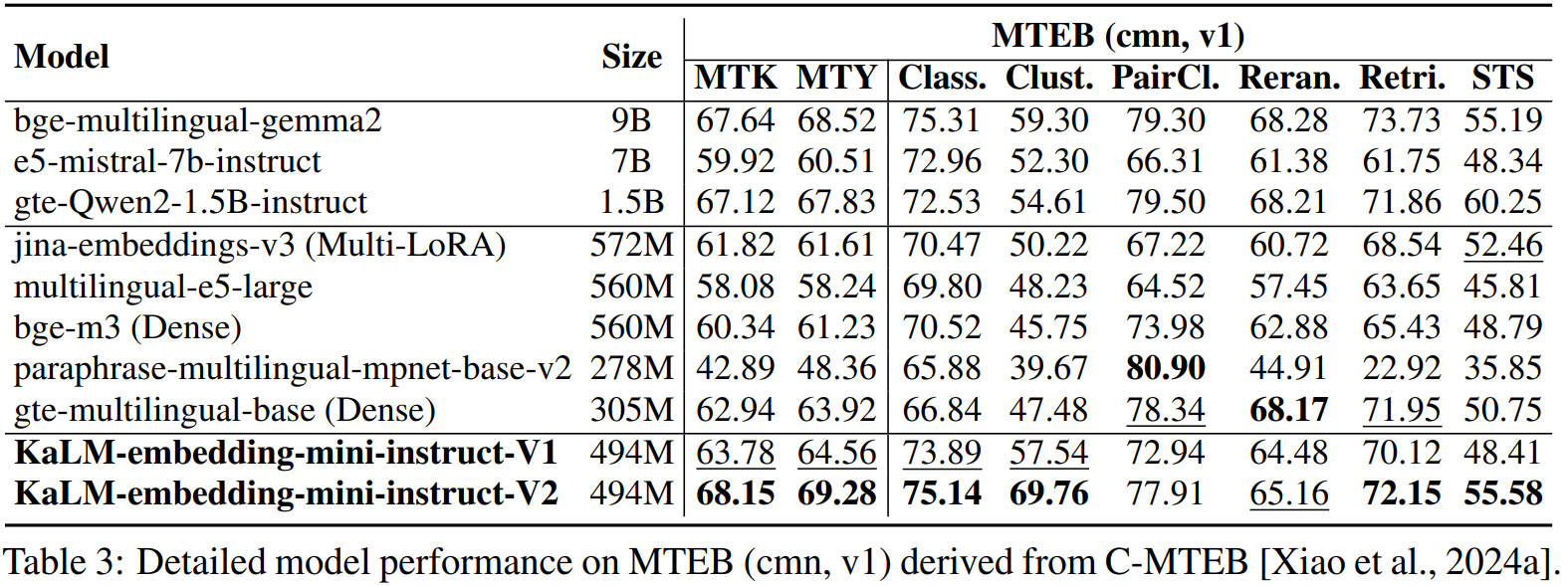
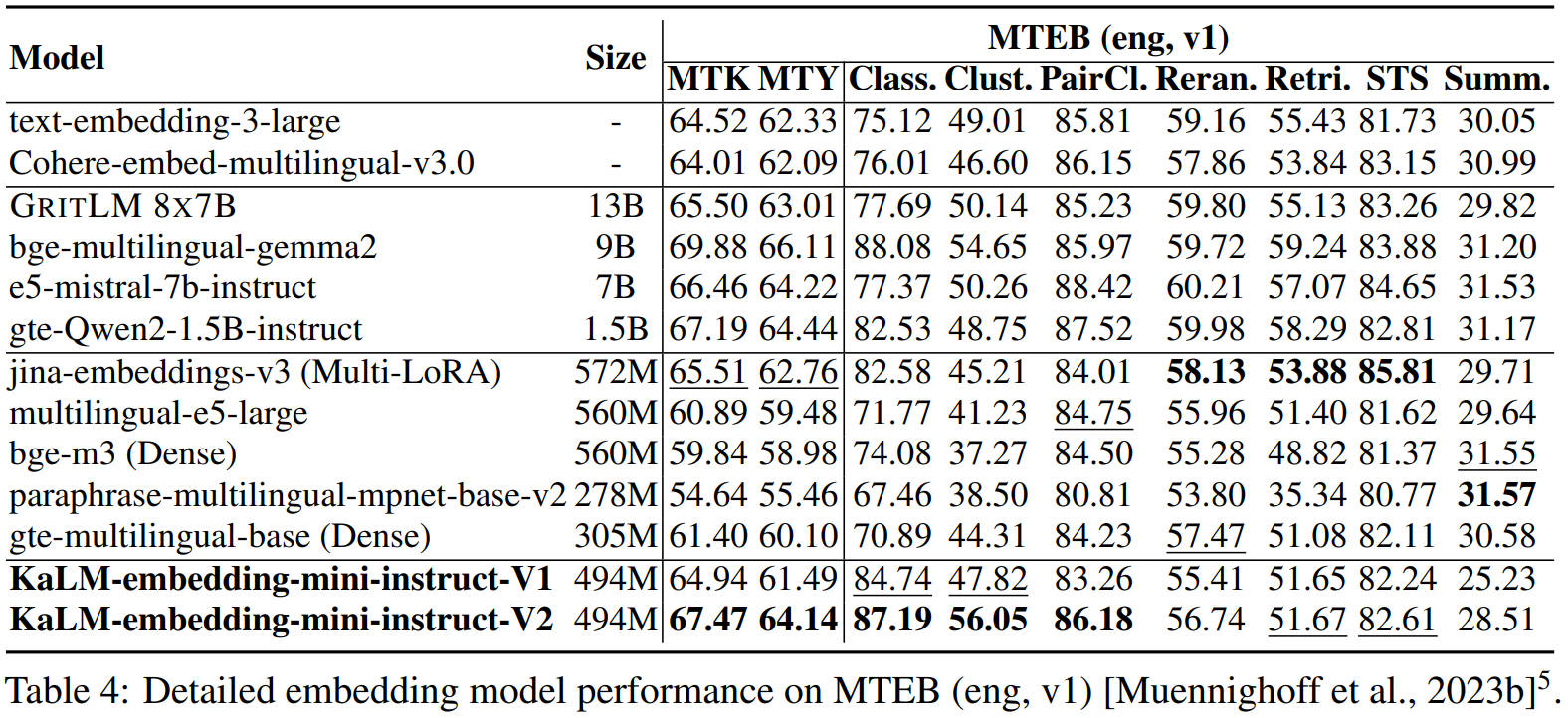
These results validate the model’s ability to deliver competitive retrieval and embedding quality while maintaining a compact footprint suitable for latency-sensitive applications.
We're benchmarking and onboarding KaLM embedding multilingual mini instruct v2 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.